mirror of https://github.com/apache/superset.git
Compare commits
155 Commits
0588f7ed73
...
fb58f15a4f
| Author | SHA1 | Date |
|---|---|---|
|
|
fb58f15a4f | |
|
|
f5843fe588 | |
|
|
49231da42f | |
|
|
517f254726 | |
|
|
f95d9cde40 | |
|
|
49992dd9d2 | |
|
|
3e74ff174c | |
|
|
b4c4ab7790 | |
|
|
5331dc740a | |
|
|
27952e7057 | |
|
|
0ce5864fc7 | |
|
|
593c653ab5 | |
|
|
d36bccdc8c | |
|
|
513852b7c3 | |
|
|
e94360486e | |
|
|
b17db6d669 | |
|
|
f4b6c3049b | |
|
|
55391bb587 | |
|
|
38e2843b24 | |
|
|
7c8423a522 | |
|
|
ec8351d336 | |
|
|
e4f93b293f | |
|
|
2b4b771449 | |
|
|
538d1bb245 | |
|
|
3ac387bb66 | |
|
|
fe37d914e5 | |
|
|
51da5adbc7 | |
|
|
3cc8434c5a | |
|
|
c641bbfb9e | |
|
|
2e9cc654ef | |
|
|
f03de27a92 | |
|
|
601896b1fc | |
|
|
2e5f3ed851 | |
|
|
a38dc90abe | |
|
|
efda57e8a5 | |
|
|
44690fb299 | |
|
|
f9f0bc687d | |
|
|
4d2247a7e1 | |
|
|
743c0bde7e | |
|
|
c975f97ce8 | |
|
|
76d897eaa2 | |
|
|
a08c24c4aa | |
|
|
fca3a525d0 | |
|
|
db5edb3a42 | |
|
|
3a2a930ad3 | |
|
|
7e94dc5b40 | |
|
|
cdbf8f394a | |
|
|
173d5d09bf | |
|
|
c5e7d870f0 | |
|
|
1e47e65ac5 | |
|
|
271510f0a8 | |
|
|
63afa24c11 | |
|
|
ce1d18e534 | |
|
|
4afeabe042 | |
|
|
6cf681df68 | |
|
|
52f8734662 | |
|
|
7b40b6426c | |
|
|
2d63722150 | |
|
|
e8a678b75a | |
|
|
bc65c245fe | |
|
|
a9075fdb1f | |
|
|
8baf754615 | |
|
|
cf90def462 | |
|
|
9db431b430 | |
|
|
f155138659 | |
|
|
efc1ab83d4 | |
|
|
68c77d6e9f | |
|
|
063914af04 | |
|
|
b7f3e0bb50 | |
|
|
de82d90b9c | |
|
|
cfc440c56c | |
|
|
83fedcc9ea | |
|
|
cddcff2c63 | |
|
|
e889f17421 | |
|
|
c23876d536 | |
|
|
fe2be5ffea | |
|
|
1ef839ca6d | |
|
|
f5bd183cc5 | |
|
|
7906e7b5ff | |
|
|
11dbae78cb | |
|
|
86d7b04eaa | |
|
|
bfa2c46430 | |
|
|
e465876ed4 | |
|
|
37f900a264 | |
|
|
783dbb5040 | |
|
|
452e26ea79 | |
|
|
529954fbcb | |
|
|
b168520ad2 | |
|
|
7b21e8fbae | |
|
|
76568807c4 | |
|
|
3f86df1445 | |
|
|
95b3f31d9c | |
|
|
17a65b1e03 | |
|
|
0f0f299b3e | |
|
|
6c045f4228 | |
|
|
947391778e | |
|
|
4c1e2bcc7a | |
|
|
6748c4361f | |
|
|
7e91d18853 | |
|
|
2f11f66167 | |
|
|
7263c7cb47 | |
|
|
9ee56bbc5b | |
|
|
96cea5aa1f | |
|
|
9967f52657 | |
|
|
84ef17d818 | |
|
|
fda9c60e25 | |
|
|
68a982dfe6 | |
|
|
69a7bfc88d | |
|
|
0e096e8001 | |
|
|
5ece57bd34 | |
|
|
8a390f03e3 | |
|
|
f3c538a3dd | |
|
|
cd15655ed3 | |
|
|
c457add848 | |
|
|
19170d94c8 | |
|
|
594e5a50a3 | |
|
|
3310315d4b | |
|
|
80f76947d1 | |
|
|
89da4f82d3 | |
|
|
5a9ddbba2e | |
|
|
181a901f75 | |
|
|
aab645e01c | |
|
|
e9c0ca545f | |
|
|
6e01a68276 | |
|
|
4b0452b87b | |
|
|
de9daf7ad9 | |
|
|
c225e17a75 | |
|
|
99c414e4da | |
|
|
0c12369084 | |
|
|
8538796128 | |
|
|
2a62c40526 | |
|
|
08aaebbf7c | |
|
|
caad29b5b3 | |
|
|
54387b4589 | |
|
|
40e77be813 | |
|
|
8afe973968 | |
|
|
99a1601aea | |
|
|
06077d42a8 | |
|
|
6844735a45 | |
|
|
02b69709bb | |
|
|
35c8b7a162 | |
|
|
4f363e1180 | |
|
|
7e679d56ea | |
|
|
aef325a416 | |
|
|
9998a11fdd | |
|
|
cd136ad847 | |
|
|
a29cdefedf | |
|
|
a6d16ed477 | |
|
|
dea430649d | |
|
|
9423d59132 | |
|
|
cbfdba2ca6 | |
|
|
eb4ca010ae | |
|
|
8200261506 | |
|
|
601d011986 | |
|
|
b2aaaf441a |
19
.asf.yaml
19
.asf.yaml
|
|
@ -67,15 +67,16 @@ github:
|
|||
- cypress-matrix (2, chrome)
|
||||
- cypress-matrix (3, chrome)
|
||||
- frontend-build
|
||||
- pre-commit (3.10)
|
||||
- python-lint (3.10)
|
||||
- test-mysql (3.10)
|
||||
- test-postgres (3.10)
|
||||
- test-postgres (3.11)
|
||||
- test-postgres-hive (3.10)
|
||||
- test-postgres-presto (3.10)
|
||||
- test-sqlite (3.10)
|
||||
- unit-tests (3.10)
|
||||
- pre-commit
|
||||
- python-lint
|
||||
- test-mysql
|
||||
- test-postgres (current)
|
||||
- test-postgres (next)
|
||||
- test-postgres-hive
|
||||
- test-postgres-presto
|
||||
- test-sqlite
|
||||
- unit-tests (current)
|
||||
- unit-tests (next)
|
||||
|
||||
required_pull_request_reviews:
|
||||
dismiss_stale_reviews: false
|
||||
|
|
|
|||
|
|
@ -7,6 +7,7 @@ body:
|
|||
value: |
|
||||
Hello Superset Community member! Please keep things tidy by putting your post in the proper place:
|
||||
|
||||
🚨 Reporting a security issue: send an email to security@superset.apache.org. DO NOT USE GITHUB ISSUES TO REPORT SECURITY PROBLEMS.
|
||||
🐛 Reporting a bug: use this form.
|
||||
🙏 Asking a question or getting help: post in the [Superset Slack chat](http://bit.ly/join-superset-slack) or [GitHub Discussions](https://github.com/apache/superset/discussions) under "Q&A / Help".
|
||||
💡 Requesting a new feature: Search [GitHub Discussions](https://github.com/apache/superset/discussions) to see if it exists already. If not, add a new post there under "Ideas".
|
||||
|
|
|
|||
|
|
@ -2,9 +2,9 @@ name: 'Setup Python Environment'
|
|||
description: 'Set up Python and install dependencies with optional configurations.'
|
||||
inputs:
|
||||
python-version:
|
||||
description: 'Python version to set up.'
|
||||
description: 'Python version to set up. Accepts a version number, "current", or "next".'
|
||||
required: true
|
||||
default: '3.10'
|
||||
default: 'current'
|
||||
cache:
|
||||
description: 'Cache dependencies. Options: pip'
|
||||
required: false
|
||||
|
|
@ -13,22 +13,39 @@ inputs:
|
|||
description: 'Type of requirements to install. Options: base, development, default'
|
||||
required: false
|
||||
default: 'dev'
|
||||
install-superset:
|
||||
description: 'Whether to install Superset itself. If false, only python is installed'
|
||||
required: false
|
||||
default: 'true'
|
||||
|
||||
runs:
|
||||
using: 'composite'
|
||||
steps:
|
||||
- name: Set up Python ${{ inputs.python-version }}
|
||||
- name: Interpret Python Version
|
||||
id: set-python-version
|
||||
shell: bash
|
||||
run: |
|
||||
if [ "${{ inputs.python-version }}" = "current" ]; then
|
||||
echo "PYTHON_VERSION=3.10" >> $GITHUB_ENV
|
||||
elif [ "${{ inputs.python-version }}" = "next" ]; then
|
||||
echo "PYTHON_VERSION=3.11" >> $GITHUB_ENV
|
||||
else
|
||||
echo "PYTHON_VERSION=${{ inputs.python-version }}" >> $GITHUB_ENV
|
||||
fi
|
||||
- name: Set up Python ${{ env.PYTHON_VERSION }}
|
||||
uses: actions/setup-python@v5
|
||||
with:
|
||||
python-version: ${{ inputs.python-version }}
|
||||
python-version: ${{ env.PYTHON_VERSION }}
|
||||
cache: ${{ inputs.cache }}
|
||||
- name: Install dependencies
|
||||
run: |
|
||||
sudo apt-get update && sudo apt-get -y install libldap2-dev libsasl2-dev
|
||||
pip install --upgrade pip setuptools wheel
|
||||
if [ "${{ inputs.requirements-type }}" = "dev" ]; then
|
||||
pip install -r requirements/development.txt
|
||||
elif [ "${{ inputs.requirements-type }}" = "base" ]; then
|
||||
pip install -r requirements/base.txt
|
||||
if [ "${{ inputs.install-superset }}" = "true" ]; then
|
||||
sudo apt-get update && sudo apt-get -y install libldap2-dev libsasl2-dev
|
||||
pip install --upgrade pip setuptools wheel
|
||||
if [ "${{ inputs.requirements-type }}" = "dev" ]; then
|
||||
pip install -r requirements/development.txt
|
||||
elif [ "${{ inputs.requirements-type }}" = "base" ]; then
|
||||
pip install -r requirements/base.txt
|
||||
fi
|
||||
fi
|
||||
shell: bash
|
||||
|
|
|
|||
|
|
@ -34,3 +34,7 @@ runs:
|
|||
# simple trick to install globally with dependencies
|
||||
npm pack
|
||||
npm install -g ./supersetbot*.tgz
|
||||
|
||||
- name: echo supersetbot version
|
||||
shell: bash
|
||||
run: supersetbot version
|
||||
|
|
|
|||
|
|
@ -19,14 +19,11 @@ updates:
|
|||
open-pull-requests-limit: 30
|
||||
versioning-strategy: increase
|
||||
|
||||
- package-ecosystem: "pip"
|
||||
directory: "/requirements/"
|
||||
schedule:
|
||||
interval: "monthly"
|
||||
labels:
|
||||
- pip
|
||||
- dependabot
|
||||
open-pull-requests-limit: 30
|
||||
|
||||
# - package-ecosystem: "pip"
|
||||
# NOTE: as dependabot isn't compatible with our python
|
||||
# dependency setup (pip-compile-multi), we'll be using
|
||||
# `supersetbot` instead
|
||||
|
||||
- package-ecosystem: "npm"
|
||||
directory: ".github/actions"
|
||||
|
|
|
|||
|
|
@ -72,6 +72,11 @@
|
|||
- any-glob-to-any-file:
|
||||
- 'superset/translations/zh/**'
|
||||
|
||||
"i18n:traditional-chinese":
|
||||
- changed-files:
|
||||
- any-glob-to-any-file:
|
||||
- 'superset/translations/zh_TW/**'
|
||||
|
||||
"i18n:dutch":
|
||||
- changed-files:
|
||||
- any-glob-to-any-file:
|
||||
|
|
|
|||
|
|
@ -89,6 +89,8 @@ EOF
|
|||
setup-mysql() {
|
||||
say "::group::Initialize database"
|
||||
mysql -h 127.0.0.1 -P 13306 -u root --password=root <<-EOF
|
||||
SET GLOBAL transaction_isolation='READ-COMMITTED';
|
||||
SET GLOBAL TRANSACTION ISOLATION LEVEL READ COMMITTED;
|
||||
DROP DATABASE IF EXISTS superset;
|
||||
CREATE DATABASE superset DEFAULT CHARACTER SET utf8 COLLATE utf8_unicode_ci;
|
||||
DROP DATABASE IF EXISTS sqllab_test_db;
|
||||
|
|
@ -115,12 +117,6 @@ testdata() {
|
|||
say "::endgroup::"
|
||||
}
|
||||
|
||||
codecov() {
|
||||
say "::group::Upload code coverage"
|
||||
bash ".github/workflows/codecov.sh" "$@"
|
||||
say "::endgroup::"
|
||||
}
|
||||
|
||||
cypress-install() {
|
||||
cd "$GITHUB_WORKSPACE/superset-frontend/cypress-base"
|
||||
|
||||
|
|
@ -189,11 +185,6 @@ cypress-run-all() {
|
|||
|
||||
cypress-run "sqllab/*" "Backend persist"
|
||||
|
||||
# Upload code coverage separately so each page can have separate flags
|
||||
# -c will clean existing coverage reports, -F means add flags
|
||||
# || true to prevent CI failure on codecov upload
|
||||
codecov -c -F "cypress" || true
|
||||
|
||||
say "::group::Flask log for backend persist"
|
||||
cat "$flasklog"
|
||||
say "::endgroup::"
|
||||
|
|
@ -221,9 +212,7 @@ cypress-run-applitools() {
|
|||
nohup flask run --no-debugger -p $port >"$flasklog" 2>&1 </dev/null &
|
||||
local flaskProcessId=$!
|
||||
|
||||
$cypress --spec "cypress/e2e/*/**/*.applitools.test.ts" --browser "$browser" --headless --config ignoreTestFiles="[]"
|
||||
|
||||
codecov -c -F "cypress" || true
|
||||
$cypress --spec "cypress/e2e/*/**/*.applitools.test.ts" --browser "$browser" --headless
|
||||
|
||||
say "::group::Flask log for default run"
|
||||
cat "$flasklog"
|
||||
|
|
|
|||
|
|
@ -0,0 +1,68 @@
|
|||
name: Bump Python Package
|
||||
|
||||
on:
|
||||
# Can be triggered manually
|
||||
workflow_dispatch:
|
||||
inputs:
|
||||
package:
|
||||
required: false
|
||||
description: The python package to bump (all if empty)
|
||||
group:
|
||||
required: false
|
||||
description: The optional dependency group to bump (as defined in pyproject.toml)
|
||||
limit:
|
||||
required: true
|
||||
description: Max number of PRs to open (0 for no limit)
|
||||
default: 5
|
||||
|
||||
jobs:
|
||||
bump-python-package:
|
||||
runs-on: ubuntu-latest
|
||||
permissions:
|
||||
actions: write
|
||||
contents: write
|
||||
pull-requests: write
|
||||
checks: write
|
||||
steps:
|
||||
|
||||
- name: "Checkout ${{ github.ref }} ( ${{ github.sha }} )"
|
||||
uses: actions/checkout@v4
|
||||
with:
|
||||
persist-credentials: true
|
||||
ref: master
|
||||
|
||||
- name: Setup supersetbot
|
||||
uses: ./.github/actions/setup-supersetbot/
|
||||
|
||||
- name: Set up Python ${{ inputs.python-version }}
|
||||
uses: actions/setup-python@v5
|
||||
with:
|
||||
python-version: "3.10"
|
||||
|
||||
- name: Install pip-compile-multi
|
||||
run: pip install pip-compile-multi
|
||||
|
||||
- name: supersetbot bump-python -p "${{ github.event.inputs.package }}"
|
||||
env:
|
||||
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
|
||||
run: |
|
||||
git config --global user.email "action@github.com"
|
||||
git config --global user.name "GitHub Action"
|
||||
|
||||
PACKAGE_OPT=""
|
||||
if [ -n "${{ github.event.inputs.package }}" ]; then
|
||||
PACKAGE_OPT="-p ${{ github.event.inputs.package }}"
|
||||
fi
|
||||
|
||||
GROUP_OPT=""
|
||||
if [ -n "${{ github.event.inputs.group }}" ]; then
|
||||
GROUP_OPT="-g ${{ github.event.inputs.group }}"
|
||||
fi
|
||||
|
||||
supersetbot bump-python \
|
||||
--verbose \
|
||||
--use-current-repo \
|
||||
--include-subpackages \
|
||||
--limit ${{ github.event.inputs.limit }} \
|
||||
$PACKAGE_OPT \
|
||||
$GROUP_OPT
|
||||
File diff suppressed because it is too large
Load Diff
|
|
@ -23,5 +23,22 @@ jobs:
|
|||
# compatible/incompatible licenses addressed here: https://www.apache.org/legal/resolved.html
|
||||
# find SPDX identifiers here: https://spdx.org/licenses/
|
||||
deny-licenses: MS-LPL, BUSL-1.1, QPL-1.0, Sleepycat, SSPL-1.0, CPOL-1.02, AGPL-3.0, GPL-1.0+, BSD-4-Clause-UC, NPL-1.0, NPL-1.1, JSON
|
||||
# adding an exception for an ambigious license on store2, which has been resolved in the latest version. It's MIT: https://github.com/nbubna/store/blob/master/LICENSE-MIT
|
||||
allow-dependencies-licenses: 'pkg:npm/store2@2.14.2'
|
||||
allow-dependencies-licenses:
|
||||
# adding an exception for an ambigious license on store2, which has been resolved in
|
||||
# the latest version. It's MIT: https://github.com/nbubna/store/blob/master/LICENSE-MIT
|
||||
- 'pkg:npm/store2@2.14.2'
|
||||
# adding exception for all applitools modules (eyes-cypress and its dependencies),
|
||||
# which has an explicit OSS license approved by ASF
|
||||
# license: https://applitools.com/legal/open-source-terms-of-use/
|
||||
- 'pkg:npm/applitools/core'
|
||||
- 'pkg:npm/applitools/core-base'
|
||||
- 'pkg:npm/applitools/css-tree'
|
||||
- 'pkg:npm/applitools/ec-client'
|
||||
- 'pkg:npm/applitools/eg-socks5-proxy-server'
|
||||
- 'pkg:npm/applitools/eyes'
|
||||
- 'pkg:npm/applitools/eyes-cypress'
|
||||
- 'pkg:npm/applitools/nml-client'
|
||||
- 'pkg:npm/applitools/tunnel-client'
|
||||
- 'pkg:npm/applitools/utils'
|
||||
# Selecting BSD-3-Clause licensing terms for node-forge to ensure compatibility with Apache
|
||||
- 'pkg:npm/node-forge@1.3.1'
|
||||
|
|
|
|||
|
|
@ -21,7 +21,7 @@ jobs:
|
|||
steps:
|
||||
- id: set_matrix
|
||||
run: |
|
||||
MATRIX_CONFIG=$(if [ "${{ github.event_name }}" == "pull_request" ]; then echo '["ci"]'; else echo '["dev", "lean", "py310", "websocket", "dockerize"]'; fi)
|
||||
MATRIX_CONFIG=$(if [ "${{ github.event_name }}" == "pull_request" ]; then echo '["dev"]'; else echo '["dev", "lean", "py310", "websocket", "dockerize"]'; fi)
|
||||
echo "matrix_config=${MATRIX_CONFIG}" >> $GITHUB_OUTPUT
|
||||
echo $GITHUB_OUTPUT
|
||||
|
||||
|
|
@ -73,6 +73,8 @@ jobs:
|
|||
- name: Build Docker Image
|
||||
if: steps.check.outputs.python || steps.check.outputs.frontend || steps.check.outputs.docker
|
||||
shell: bash
|
||||
env:
|
||||
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
|
||||
run: |
|
||||
# Single platform builds in pull_request context to speed things up
|
||||
if [ "${{ github.event_name }}" = "push" ]; then
|
||||
|
|
|
|||
|
|
@ -16,9 +16,6 @@ concurrency:
|
|||
jobs:
|
||||
pre-commit:
|
||||
runs-on: ubuntu-20.04
|
||||
strategy:
|
||||
matrix:
|
||||
python-version: ["3.10"]
|
||||
steps:
|
||||
- name: "Checkout ${{ github.ref }} ( ${{ github.sha }} )"
|
||||
uses: actions/checkout@v4
|
||||
|
|
|
|||
|
|
@ -16,9 +16,6 @@ concurrency:
|
|||
jobs:
|
||||
test-load-examples:
|
||||
runs-on: ubuntu-20.04
|
||||
strategy:
|
||||
matrix:
|
||||
python-version: ["3.10"]
|
||||
env:
|
||||
PYTHONPATH: ${{ github.workspace }}
|
||||
SUPERSET_CONFIG: tests.integration_tests.superset_test_config
|
||||
|
|
|
|||
|
|
@ -4,9 +4,11 @@ on:
|
|||
push:
|
||||
paths:
|
||||
- "docs/**"
|
||||
- "README.md"
|
||||
branches:
|
||||
- "master"
|
||||
- "[0-9].[0-9]"
|
||||
|
||||
workflow_dispatch: {}
|
||||
|
||||
jobs:
|
||||
config:
|
||||
|
|
@ -27,9 +29,6 @@ jobs:
|
|||
if: needs.config.outputs.has-secrets
|
||||
name: Build & Deploy
|
||||
runs-on: "ubuntu-latest"
|
||||
defaults:
|
||||
run:
|
||||
working-directory: docs
|
||||
steps:
|
||||
- name: "Checkout ${{ github.ref }} ( ${{ github.sha }} )"
|
||||
uses: actions/checkout@v4
|
||||
|
|
@ -40,14 +39,30 @@ jobs:
|
|||
uses: actions/setup-node@v4
|
||||
with:
|
||||
node-version: '18'
|
||||
- name: Setup Python
|
||||
uses: ./.github/actions/setup-backend/
|
||||
- uses: actions/setup-java@v4
|
||||
with:
|
||||
distribution: 'zulu'
|
||||
java-version: '21'
|
||||
- name: Install Graphviz
|
||||
run: sudo apt-get install -y graphviz
|
||||
- name: Compute Entity Relationship diagram (ERD)
|
||||
env:
|
||||
SUPERSET_SECRET_KEY: not-a-secret
|
||||
run: |
|
||||
python scripts/erd/erd.py
|
||||
curl -L http://sourceforge.net/projects/plantuml/files/1.2023.7/plantuml.1.2023.7.jar/download > ~/plantuml.jar
|
||||
java -jar ~/plantuml.jar -v -tsvg -r -o "${{ github.workspace }}/docs/static/img/" "${{ github.workspace }}/scripts/erd/erd.puml"
|
||||
- name: yarn install
|
||||
working-directory: docs
|
||||
run: |
|
||||
yarn install --check-cache
|
||||
- name: yarn build
|
||||
working-directory: docs
|
||||
run: |
|
||||
yarn build
|
||||
- name: deploy docs
|
||||
if: github.ref == 'refs/heads/master'
|
||||
uses: ./.github/actions/github-action-push-to-another-repository
|
||||
env:
|
||||
API_TOKEN_GITHUB: ${{ secrets.SUPERSET_SITE_BUILD }}
|
||||
|
|
|
|||
|
|
@ -78,6 +78,8 @@ jobs:
|
|||
working-directory: ./superset-frontend/packages/generator-superset
|
||||
run: npx jest
|
||||
- name: Upload code coverage
|
||||
if: steps.check.outputs.frontend
|
||||
working-directory: ./superset-frontend
|
||||
run: ../.github/workflows/codecov.sh -c -F javascript
|
||||
uses: codecov/codecov-action@v4
|
||||
with:
|
||||
flags: javascript
|
||||
token: ${{ secrets.CODECOV_TOKEN }}
|
||||
verbose: true
|
||||
|
|
|
|||
|
|
@ -23,13 +23,14 @@ jobs:
|
|||
fetch-depth: 0
|
||||
|
||||
- name: Set up Helm
|
||||
uses: azure/setup-helm@v3
|
||||
uses: azure/setup-helm@v4
|
||||
with:
|
||||
version: v3.5.4
|
||||
|
||||
- uses: actions/setup-python@v5
|
||||
- name: Setup Python
|
||||
uses: ./.github/actions/setup-backend/
|
||||
with:
|
||||
python-version: "3.10"
|
||||
install-superset: 'false'
|
||||
|
||||
- name: Set up chart-testing
|
||||
uses: ./.github/actions/chart-testing-action
|
||||
|
|
|
|||
|
|
@ -28,7 +28,7 @@ jobs:
|
|||
git config user.email "$GITHUB_ACTOR@users.noreply.github.com"
|
||||
|
||||
- name: Install Helm
|
||||
uses: azure/setup-helm@v3
|
||||
uses: azure/setup-helm@v4
|
||||
with:
|
||||
version: v3.5.4
|
||||
|
||||
|
|
|
|||
|
|
@ -16,9 +16,6 @@ concurrency:
|
|||
jobs:
|
||||
test-mysql:
|
||||
runs-on: ubuntu-20.04
|
||||
strategy:
|
||||
matrix:
|
||||
python-version: ["3.10"]
|
||||
env:
|
||||
PYTHONPATH: ${{ github.workspace }}
|
||||
SUPERSET_CONFIG: tests.integration_tests.superset_test_config
|
||||
|
|
@ -32,6 +29,11 @@ jobs:
|
|||
MYSQL_ROOT_PASSWORD: root
|
||||
ports:
|
||||
- 13306:3306
|
||||
options: >-
|
||||
--health-cmd="mysqladmin ping --silent"
|
||||
--health-interval=10s
|
||||
--health-timeout=5s
|
||||
--health-retries=5
|
||||
redis:
|
||||
image: redis:7-alpine
|
||||
options: --entrypoint redis-server
|
||||
|
|
@ -51,14 +53,11 @@ jobs:
|
|||
- name: Setup Python
|
||||
uses: ./.github/actions/setup-backend/
|
||||
if: steps.check.outputs.python
|
||||
with:
|
||||
python-version: ${{ matrix.python-version }}
|
||||
- name: Setup MySQL
|
||||
if: steps.check.outputs.python
|
||||
uses: ./.github/actions/cached-dependencies
|
||||
with:
|
||||
run: |
|
||||
setup-mysql
|
||||
run: setup-mysql
|
||||
- name: Run celery
|
||||
if: steps.check.outputs.python
|
||||
run: celery --app=superset.tasks.celery_app:app worker -Ofair -c 2 &
|
||||
|
|
@ -67,14 +66,16 @@ jobs:
|
|||
run: |
|
||||
./scripts/python_tests.sh
|
||||
- name: Upload code coverage
|
||||
if: steps.check.outputs.python
|
||||
run: |
|
||||
bash .github/workflows/codecov.sh -c -F python -F mysql
|
||||
uses: codecov/codecov-action@v4
|
||||
with:
|
||||
flags: python,mysql
|
||||
token: ${{ secrets.CODECOV_TOKEN }}
|
||||
verbose: true
|
||||
test-postgres:
|
||||
runs-on: ubuntu-20.04
|
||||
strategy:
|
||||
matrix:
|
||||
python-version: ["3.10", "3.11"]
|
||||
python-version: ["current", "next"]
|
||||
env:
|
||||
PYTHONPATH: ${{ github.workspace }}
|
||||
SUPERSET_CONFIG: tests.integration_tests.superset_test_config
|
||||
|
|
@ -124,15 +125,14 @@ jobs:
|
|||
run: |
|
||||
./scripts/python_tests.sh
|
||||
- name: Upload code coverage
|
||||
if: steps.check.outputs.python
|
||||
run: |
|
||||
bash .github/workflows/codecov.sh -c -F python -F postgres
|
||||
uses: codecov/codecov-action@v4
|
||||
with:
|
||||
flags: python,postgres
|
||||
token: ${{ secrets.CODECOV_TOKEN }}
|
||||
verbose: true
|
||||
|
||||
test-sqlite:
|
||||
runs-on: ubuntu-20.04
|
||||
strategy:
|
||||
matrix:
|
||||
python-version: ["3.10"]
|
||||
env:
|
||||
PYTHONPATH: ${{ github.workspace }}
|
||||
SUPERSET_CONFIG: tests.integration_tests.superset_test_config
|
||||
|
|
@ -160,8 +160,6 @@ jobs:
|
|||
- name: Setup Python
|
||||
uses: ./.github/actions/setup-backend/
|
||||
if: steps.check.outputs.python
|
||||
with:
|
||||
python-version: ${{ matrix.python-version }}
|
||||
- name: Install dependencies
|
||||
if: steps.check.outputs.python
|
||||
uses: ./.github/actions/cached-dependencies
|
||||
|
|
@ -177,6 +175,8 @@ jobs:
|
|||
run: |
|
||||
./scripts/python_tests.sh
|
||||
- name: Upload code coverage
|
||||
if: steps.check.outputs.python
|
||||
run: |
|
||||
bash .github/workflows/codecov.sh -c -F python -F sqlite
|
||||
uses: codecov/codecov-action@v4
|
||||
with:
|
||||
flags: python,sqlite
|
||||
token: ${{ secrets.CODECOV_TOKEN }}
|
||||
verbose: true
|
||||
|
|
|
|||
|
|
@ -17,9 +17,6 @@ concurrency:
|
|||
jobs:
|
||||
python-lint:
|
||||
runs-on: ubuntu-20.04
|
||||
strategy:
|
||||
matrix:
|
||||
python-version: ["3.10"]
|
||||
steps:
|
||||
- name: "Checkout ${{ github.ref }} ( ${{ github.sha }} )"
|
||||
uses: actions/checkout@v4
|
||||
|
|
@ -34,18 +31,9 @@ jobs:
|
|||
- name: Setup Python
|
||||
uses: ./.github/actions/setup-backend/
|
||||
if: steps.check.outputs.python
|
||||
with:
|
||||
python-version: ${{ matrix.python-version }}
|
||||
- name: pylint
|
||||
if: steps.check.outputs.python
|
||||
# `-j 0` run Pylint in parallel
|
||||
run: pylint -j 0 superset
|
||||
|
||||
babel-extract:
|
||||
runs-on: ubuntu-20.04
|
||||
strategy:
|
||||
matrix:
|
||||
python-version: ["3.10"]
|
||||
steps:
|
||||
- name: "Checkout ${{ github.ref }} ( ${{ github.sha }} )"
|
||||
uses: actions/checkout@v4
|
||||
|
|
@ -60,8 +48,6 @@ jobs:
|
|||
- name: Setup Python
|
||||
if: steps.check.outputs.python
|
||||
uses: ./.github/actions/setup-backend/
|
||||
with:
|
||||
python-version: ${{ matrix.python-version }}
|
||||
- name: Test babel extraction
|
||||
if: steps.check.outputs.python
|
||||
run: flask fab babel-extract --target superset/translations --output superset/translations/messages.pot --config superset/translations/babel.cfg -k _,__,t,tn,tct
|
||||
|
|
|
|||
|
|
@ -17,9 +17,6 @@ concurrency:
|
|||
jobs:
|
||||
test-postgres-presto:
|
||||
runs-on: ubuntu-20.04
|
||||
strategy:
|
||||
matrix:
|
||||
python-version: ["3.10"]
|
||||
env:
|
||||
PYTHONPATH: ${{ github.workspace }}
|
||||
SUPERSET_CONFIG: tests.integration_tests.superset_test_config
|
||||
|
|
@ -78,15 +75,14 @@ jobs:
|
|||
run: |
|
||||
./scripts/python_tests.sh -m 'chart_data_flow or sql_json_flow'
|
||||
- name: Upload code coverage
|
||||
if: steps.check.outputs.python
|
||||
run: |
|
||||
bash .github/workflows/codecov.sh -c -F python -F presto
|
||||
uses: codecov/codecov-action@v4
|
||||
with:
|
||||
flags: python,presto
|
||||
token: ${{ secrets.CODECOV_TOKEN }}
|
||||
verbose: true
|
||||
|
||||
test-postgres-hive:
|
||||
runs-on: ubuntu-20.04
|
||||
strategy:
|
||||
matrix:
|
||||
python-version: ["3.10"]
|
||||
env:
|
||||
PYTHONPATH: ${{ github.workspace }}
|
||||
SUPERSET_CONFIG: tests.integration_tests.superset_test_config
|
||||
|
|
@ -144,6 +140,8 @@ jobs:
|
|||
run: |
|
||||
./scripts/python_tests.sh -m 'chart_data_flow or sql_json_flow'
|
||||
- name: Upload code coverage
|
||||
if: steps.check.outputs.python
|
||||
run: |
|
||||
bash .github/workflows/codecov.sh -c -F python -F hive
|
||||
uses: codecov/codecov-action@v4
|
||||
with:
|
||||
flags: python,hive
|
||||
token: ${{ secrets.CODECOV_TOKEN }}
|
||||
verbose: true
|
||||
|
|
|
|||
|
|
@ -19,7 +19,7 @@ jobs:
|
|||
runs-on: ubuntu-20.04
|
||||
strategy:
|
||||
matrix:
|
||||
python-version: ["3.10", "3.11"]
|
||||
python-version: ["current", "next"]
|
||||
env:
|
||||
PYTHONPATH: ${{ github.workspace }}
|
||||
steps:
|
||||
|
|
@ -46,6 +46,8 @@ jobs:
|
|||
run: |
|
||||
pytest --durations-min=0.5 --cov-report= --cov=superset ./tests/common ./tests/unit_tests --cache-clear
|
||||
- name: Upload code coverage
|
||||
if: steps.check.outputs.python
|
||||
run: |
|
||||
bash .github/workflows/codecov.sh -c -F python -F unit
|
||||
uses: codecov/codecov-action@v4
|
||||
with:
|
||||
flags: python,unit
|
||||
token: ${{ secrets.CODECOV_TOKEN }}
|
||||
verbose: true
|
||||
|
|
|
|||
|
|
@ -47,9 +47,6 @@ jobs:
|
|||
|
||||
babel-extract:
|
||||
runs-on: ubuntu-20.04
|
||||
strategy:
|
||||
matrix:
|
||||
python-version: ["3.10"]
|
||||
steps:
|
||||
- name: "Checkout ${{ github.ref }} ( ${{ github.sha }} )"
|
||||
uses: actions/checkout@v4
|
||||
|
|
@ -65,8 +62,6 @@ jobs:
|
|||
- name: Setup Python
|
||||
if: steps.check.outputs.python
|
||||
uses: ./.github/actions/setup-backend/
|
||||
with:
|
||||
python-version: ${{ matrix.python-version }}
|
||||
- name: Test babel extraction
|
||||
if: steps.check.outputs.python
|
||||
run: ./scripts/babel_update.sh
|
||||
|
|
|
|||
|
|
@ -1,4 +1,4 @@
|
|||
name: Docker Publish Release
|
||||
name: Publish a Release
|
||||
|
||||
on:
|
||||
release:
|
||||
|
|
@ -72,6 +72,7 @@ jobs:
|
|||
env:
|
||||
DOCKERHUB_USER: ${{ secrets.DOCKERHUB_USER }}
|
||||
DOCKERHUB_TOKEN: ${{ secrets.DOCKERHUB_TOKEN }}
|
||||
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
|
||||
run: |
|
||||
RELEASE="${{ github.event.release.tag_name }}"
|
||||
FORCE_LATEST=""
|
||||
|
|
@ -98,3 +99,14 @@ jobs:
|
|||
uses: actions/checkout@v4
|
||||
with:
|
||||
persist-credentials: false
|
||||
|
||||
- name: Label the PRs with the right release-related labels
|
||||
env:
|
||||
GITHUB_TOKEN: ${{ secrets.GITHUB_TOKEN }}
|
||||
run: |
|
||||
RELEASE="${{ github.event.release.tag_name }}"
|
||||
if [ "${{ github.event_name }}" = "workflow_dispatch" ]; then
|
||||
# in the case of a manually-triggered run, read release from input
|
||||
RELEASE="${{ github.event.inputs.release }}"
|
||||
fi
|
||||
supersetbot release-label $RELEASE
|
||||
|
|
@ -19,25 +19,6 @@ repos:
|
|||
rev: v0.2.2
|
||||
hooks:
|
||||
- id: auto-walrus
|
||||
- repo: https://github.com/asottile/pyupgrade
|
||||
rev: v3.4.0
|
||||
hooks:
|
||||
- id: pyupgrade
|
||||
exclude: scripts/change_detector.py
|
||||
args:
|
||||
- --py39-plus
|
||||
- repo: https://github.com/hadialqattan/pycln
|
||||
rev: v2.1.2
|
||||
hooks:
|
||||
- id: pycln
|
||||
args:
|
||||
- --disable-all-dunder-policy
|
||||
- --exclude=superset/config.py
|
||||
- --extend-exclude=tests/integration_tests/superset_test_config.*.py
|
||||
- repo: https://github.com/PyCQA/isort
|
||||
rev: 5.12.0
|
||||
hooks:
|
||||
- id: isort
|
||||
- repo: https://github.com/pre-commit/mirrors-mypy
|
||||
rev: v1.3.0
|
||||
hooks:
|
||||
|
|
@ -66,18 +47,13 @@ repos:
|
|||
hooks:
|
||||
- id: check-docstring-first
|
||||
- id: check-added-large-files
|
||||
exclude: \.(geojson)$
|
||||
exclude: ^.*\.(geojson)$|^docs/static/img/screenshots/.*
|
||||
- id: check-yaml
|
||||
exclude: ^helm/superset/templates/
|
||||
- id: debug-statements
|
||||
- id: end-of-file-fixer
|
||||
- id: trailing-whitespace
|
||||
args: ["--markdown-linebreak-ext=md"]
|
||||
- repo: https://github.com/psf/black
|
||||
rev: 23.1.0
|
||||
hooks:
|
||||
- id: black
|
||||
language_version: python3
|
||||
- repo: https://github.com/pre-commit/mirrors-prettier
|
||||
rev: v3.1.0 # Use the sha or tag you want to point at
|
||||
hooks:
|
||||
|
|
@ -95,3 +71,23 @@ repos:
|
|||
hooks:
|
||||
- id: helm-docs
|
||||
files: helm
|
||||
- repo: https://github.com/astral-sh/ruff-pre-commit
|
||||
rev: v0.4.0
|
||||
hooks:
|
||||
- id: ruff
|
||||
args: [ --fix ]
|
||||
- id: ruff-format
|
||||
- repo: local
|
||||
hooks:
|
||||
- id: pylint
|
||||
name: pylint
|
||||
entry: pylint
|
||||
language: system
|
||||
types: [python]
|
||||
exclude: ^(tests/|superset/migrations/|scripts/|RELEASING/|docker/)
|
||||
args:
|
||||
[
|
||||
"-rn", # Only display messages
|
||||
"-sn", # Don't display the score
|
||||
"--rcfile=.pylintrc",
|
||||
]
|
||||
|
|
|
|||
|
|
@ -77,6 +77,7 @@ disable=
|
|||
cyclic-import, # re-enable once this no longer raises false positives
|
||||
missing-docstring,
|
||||
duplicate-code,
|
||||
line-too-long,
|
||||
unspecified-encoding,
|
||||
too-many-instance-attributes # re-enable once this no longer raises false positives
|
||||
|
||||
|
|
@ -171,7 +172,7 @@ max-nested-blocks=5
|
|||
[FORMAT]
|
||||
|
||||
# Maximum number of characters on a single line.
|
||||
max-line-length=90
|
||||
max-line-length=100
|
||||
|
||||
# Regexp for a line that is allowed to be longer than the limit.
|
||||
ignore-long-lines=^\s*(# )?<?https?://\S+>?$
|
||||
|
|
|
|||
|
|
@ -64,5 +64,10 @@ temporary_superset_ui/*
|
|||
# docs overrides for third party logos we don't have the rights to
|
||||
google-big-query.svg
|
||||
google-sheets.svg
|
||||
ibm-db2.svg
|
||||
postgresql.svg
|
||||
snowflake.svg
|
||||
|
||||
# docs-related
|
||||
erd.puml
|
||||
erd.svg
|
||||
|
|
|
|||
|
|
@ -0,0 +1,63 @@
|
|||
<?xml version="1.0"?>
|
||||
<?xml-stylesheet type="text/xsl"?>
|
||||
<rdf:RDF xml:lang="en"
|
||||
xmlns="http://usefulinc.com/ns/doap#"
|
||||
xmlns:rdf="http://www.w3.org/1999/02/22-rdf-syntax-ns#"
|
||||
xmlns:asfext="http://projects.apache.org/ns/asfext#"
|
||||
xmlns:foaf="http://xmlns.com/foaf/0.1/">
|
||||
<!--
|
||||
Licensed to the Apache Software Foundation (ASF) under one or more
|
||||
contributor license agreements. See the NOTICE file distributed with
|
||||
this work for additional information regarding copyright ownership.
|
||||
The ASF licenses this file to You under the Apache License, Version 2.0
|
||||
(the "License"); you may not use this file except in compliance with
|
||||
the License. You may obtain a copy of the License at
|
||||
|
||||
https://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing, software
|
||||
distributed under the License is distributed on an "AS IS" BASIS,
|
||||
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
|
||||
See the License for the specific language governing permissions and
|
||||
limitations under the License.
|
||||
-->
|
||||
<Project rdf:about="https://superset.apache.org">
|
||||
<created>2024-04-10</created>
|
||||
<license rdf:resource="https://spdx.org/licenses/Apache-2.0" />
|
||||
<name>Apache Superset</name>
|
||||
<homepage rdf:resource="https://superset.apache.org" />
|
||||
<asfext:pmc rdf:resource="https://superset.apache.org" />
|
||||
<shortdesc>Apache Superset™ is an open-source modern data exploration and visualization platform.</shortdesc>
|
||||
<description>Superset is a fast, lightweight, intuitive, business intelligence platform. Loaded with options, Superset makes it easy for users of all skill sets to explore and visualize their data, from simple line charts to highly detailed geospatial charts.
|
||||
|
||||
* Powerful yet easy to use:
|
||||
Superset makes it easy to explore your data, using either our simple no-code viz builder or state-of-the-art SQL IDE.
|
||||
|
||||
* Integrates with modern databases
|
||||
Superset can connect to any SQL-based databases including modern cloud-native databases and engines at petabyte scale.
|
||||
|
||||
* Modern architecture
|
||||
Superset is lightweight and highly scalable, leveraging the power of your existing data infrastructure without requiring yet another ingestion layer.
|
||||
|
||||
* Rich visualizations and dashboards
|
||||
Superset ships with 40+ pre-installed visualization types. Our plug-in architecture makes it easy to build custom visualizations.
|
||||
|
||||
</description>
|
||||
<bug-database rdf:resource="https://github.com/apache/superset/issues" />
|
||||
<mailing-list rdf:resource="https://lists.apache.org/list.html?dev@superset.apache.org" />
|
||||
<download-page rdf:resource="https://dist.apache.org/repos/dist/release/superset/" />
|
||||
<programming-language>JavaScript</programming-language>
|
||||
<programming-language>Python</programming-language>
|
||||
<programming-language>Typescript</programming-language>
|
||||
<category rdf:resource="https://projects.apache.org/category/big-data" />
|
||||
<category rdf:resource="https://projects.apache.org/category/database" />
|
||||
<category rdf:resource="https://projects.apache.org/category/data-engineering" />
|
||||
<category rdf:resource="https://projects.apache.org/category/geospatial" />
|
||||
<repository>
|
||||
<GitRepository>
|
||||
<location rdf:resource="https://github.com/apache/superset.git"/>
|
||||
<browse rdf:resource="https://github.com/apache/superset/"/>
|
||||
</GitRepository>
|
||||
</repository>
|
||||
</Project>
|
||||
</rdf:RDF>
|
||||
|
|
@ -32,7 +32,6 @@ under the License.
|
|||
- [#26369](https://github.com/apache/superset/pull/26369) refactor: Removes the filters set feature (@michael-s-molina)
|
||||
- [#26416](https://github.com/apache/superset/pull/26416) fix: improve performance on reports log queries (@dpgaspar)
|
||||
- [#26290](https://github.com/apache/superset/pull/26290) feat(echarts-funnel): Implement % calculation type (@kgabryje)
|
||||
- [#26288](https://github.com/apache/superset/pull/26288) chore: Ensure Mixins are ordered according to the MRO (@john-bodley)
|
||||
|
||||
**Features**
|
||||
|
||||
|
|
@ -470,3 +469,4 @@ under the License.
|
|||
- [#26100](https://github.com/apache/superset/pull/26100) build(deps-dev): bump @types/node from 20.9.4 to 20.10.0 in /superset-websocket (@dependabot[bot])
|
||||
- [#26099](https://github.com/apache/superset/pull/26099) build(deps-dev): bump @types/cookie from 0.5.4 to 0.6.0 in /superset-websocket (@dependabot[bot])
|
||||
- [#26104](https://github.com/apache/superset/pull/26104) docs: update CVEs fixed on 2.1.2 (@dpgaspar)
|
||||
- [#26288](https://github.com/apache/superset/pull/26288) chore: Ensure Mixins are ordered according to the MRO (@john-bodley)
|
||||
|
|
|
|||
1575
CONTRIBUTING.md
1575
CONTRIBUTING.md
File diff suppressed because it is too large
Load Diff
14
Dockerfile
14
Dockerfile
|
|
@ -76,7 +76,7 @@ RUN mkdir -p ${PYTHONPATH} superset/static requirements superset-frontend apache
|
|||
&& chown -R superset:superset ./* \
|
||||
&& rm -rf /var/lib/apt/lists/*
|
||||
|
||||
COPY --chown=superset:superset setup.py MANIFEST.in README.md ./
|
||||
COPY --chown=superset:superset pyproject.toml setup.py MANIFEST.in README.md ./
|
||||
# setup.py uses the version information in package.json
|
||||
COPY --chown=superset:superset superset-frontend/package.json superset-frontend/
|
||||
COPY --chown=superset:superset requirements/base.txt requirements/
|
||||
|
|
@ -119,9 +119,15 @@ RUN apt-get update -qq \
|
|||
libasound2 \
|
||||
libxtst6 \
|
||||
wget \
|
||||
pkg-config \
|
||||
# Install GeckoDriver WebDriver
|
||||
&& wget -q https://github.com/mozilla/geckodriver/releases/download/${GECKODRIVER_VERSION}/geckodriver-${GECKODRIVER_VERSION}-linux64.tar.gz -O - | tar xfz - -C /usr/local/bin \
|
||||
git \
|
||||
pkg-config
|
||||
|
||||
RUN pip install playwright
|
||||
RUN playwright install-deps
|
||||
RUN playwright install chromium
|
||||
|
||||
# Install GeckoDriver WebDriver
|
||||
RUN wget -q https://github.com/mozilla/geckodriver/releases/download/${GECKODRIVER_VERSION}/geckodriver-${GECKODRIVER_VERSION}-linux64.tar.gz -O - | tar xfz - -C /usr/local/bin \
|
||||
# Install Firefox
|
||||
&& wget -q https://download-installer.cdn.mozilla.net/pub/firefox/releases/${FIREFOX_VERSION}/linux-x86_64/en-US/firefox-${FIREFOX_VERSION}.tar.bz2 -O - | tar xfj - -C /opt \
|
||||
&& ln -s /opt/firefox/firefox /usr/local/bin/firefox \
|
||||
|
|
|
|||
2
NOTICE
2
NOTICE
|
|
@ -1,5 +1,5 @@
|
|||
Apache Superset
|
||||
Copyright 2016-2021 The Apache Software Foundation
|
||||
Copyright 2016-2024 The Apache Software Foundation
|
||||
|
||||
This product includes software developed at The Apache Software
|
||||
Foundation (http://www.apache.org/).
|
||||
|
|
|
|||
120
README.md
120
README.md
|
|
@ -1,3 +1,7 @@
|
|||
---
|
||||
hide_title: true
|
||||
sidebar_position: 1
|
||||
---
|
||||
<!--
|
||||
Licensed to the Apache Software Foundation (ASF) under one
|
||||
or more contributor license agreements. See the NOTICE file
|
||||
|
|
@ -30,12 +34,14 @@ under the License.
|
|||
|
||||
<picture width="500">
|
||||
<source
|
||||
width="600"
|
||||
media="(prefers-color-scheme: dark)"
|
||||
src="https://github.com/apache/superset/raw/master/superset-frontend/src/assets/branding/superset-logo-horiz-apache-dark.png"
|
||||
src="https://superset.apache.org/img/superset-logo-horiz-dark.svg"
|
||||
alt="Superset logo (dark)"
|
||||
/>
|
||||
<img
|
||||
src="https://github.com/apache/superset/raw/master/superset-frontend/src/assets/branding/superset-logo-horiz-apache.png"
|
||||
width="600"
|
||||
src="https://superset.apache.org/img/superset-logo-horiz-apache.svg"
|
||||
alt="Superset logo (light)"
|
||||
/>
|
||||
</picture>
|
||||
|
|
@ -45,11 +51,11 @@ A modern, enterprise-ready business intelligence web application.
|
|||
[**Why Superset?**](#why-superset) |
|
||||
[**Supported Databases**](#supported-databases) |
|
||||
[**Installation and Configuration**](#installation-and-configuration) |
|
||||
[**Release Notes**](RELEASING/README.md#release-notes-for-recent-releases) |
|
||||
[**Release Notes**](https://github.com/apache/superset/blob/master/RELEASING/README.md#release-notes-for-recent-releases) |
|
||||
[**Get Involved**](#get-involved) |
|
||||
[**Contributor Guide**](#contributor-guide) |
|
||||
[**Resources**](#resources) |
|
||||
[**Organizations Using Superset**](RESOURCES/INTHEWILD.md)
|
||||
[**Organizations Using Superset**](https://github.com/apache/superset/blob/master/RESOURCES/INTHEWILD.md)
|
||||
|
||||
## Why Superset?
|
||||
|
||||
|
|
@ -70,76 +76,76 @@ Superset provides:
|
|||
## Screenshots & Gifs
|
||||
|
||||
**Video Overview**
|
||||
|
||||
https://user-images.githubusercontent.com/64562059/234390129-321d4f35-cb4b-45e8-89d9-20ae292f34fc.mp4
|
||||
<!-- File hosted here https://github.com/apache/superset-site/raw/lfs/superset-video-4k.mp4 -->
|
||||
https://superset.staged.apache.org/superset-video-4k.mp4
|
||||
|
||||
<br/>
|
||||
|
||||
**Large Gallery of Visualizations**
|
||||
|
||||
<kbd><img title="Gallery" src="superset-frontend/src/assets/images/screenshots/gallery.jpg"/></kbd><br/>
|
||||
<kbd><img title="Gallery" src="https://superset.apache.org/img/screenshots/gallery.jpg"/></kbd><br/>
|
||||
|
||||
**Craft Beautiful, Dynamic Dashboards**
|
||||
|
||||
<kbd><img title="View Dashboards" src="superset-frontend/src/assets/images/screenshots/slack_dash.jpg"/></kbd><br/>
|
||||
<kbd><img title="View Dashboards" src="https://superset.apache.org/img/screenshots/slack_dash.jpg"/></kbd><br/>
|
||||
|
||||
**No-Code Chart Builder**
|
||||
|
||||
<kbd><img title="Slice & dice your data" src="superset-frontend/src/assets/images/screenshots/explore.jpg"/></kbd><br/>
|
||||
<kbd><img title="Slice & dice your data" src="https://superset.apache.org/img/screenshots/explore.jpg"/></kbd><br/>
|
||||
|
||||
**Powerful SQL Editor**
|
||||
|
||||
<kbd><img title="SQL Lab" src="superset-frontend/src/assets/images/screenshots/sql_lab.jpg"/></kbd><br/>
|
||||
<kbd><img title="SQL Lab" src="https://superset.apache.org/img/screenshots/sql_lab.jpg"/></kbd><br/>
|
||||
|
||||
## Supported Databases
|
||||
|
||||
Superset can query data from any SQL-speaking datastore or data engine (Presto, Trino, Athena, [and more](https://superset.apache.org/docs/databases/installing-database-drivers/)) that has a Python DB-API driver and a SQLAlchemy dialect.
|
||||
Superset can query data from any SQL-speaking datastore or data engine (Presto, Trino, Athena, [and more](https://superset.apache.org/docs/configuration/databases)) that has a Python DB-API driver and a SQLAlchemy dialect.
|
||||
|
||||
Here are some of the major database solutions that are supported:
|
||||
|
||||
<p align="center">
|
||||
<img src="superset-frontend/src/assets/images/redshift.png" alt="redshift" border="0" width="200" height="80"/>
|
||||
<img src="superset-frontend/src/assets/images/google-biquery.png" alt="google-biquery" border="0" width="200" height="80"/>
|
||||
<img src="superset-frontend/src/assets/images/snowflake.png" alt="snowflake" border="0" width="200" height="80"/>
|
||||
<img src="superset-frontend/src/assets/images/trino.png" alt="trino" border="0" width="200" height="80"/>
|
||||
<img src="superset-frontend/src/assets/images/presto.png" alt="presto" border="0" width="200" height="80"/>
|
||||
<img src="superset-frontend/src/assets/images/databricks.png" alt="databricks" border="0" width="200" height="80" />
|
||||
<img src="superset-frontend/src/assets/images/druid.png" alt="druid" border="0" width="200" height="80" />
|
||||
<img src="superset-frontend/src/assets/images/firebolt.png" alt="firebolt" border="0" width="200" height="80" />
|
||||
<img src="superset-frontend/src/assets/images/timescale.png" alt="timescale" border="0" width="200" height="80" />
|
||||
<img src="superset-frontend/src/assets/images/rockset.png" alt="rockset" border="0" width="200" height="80" />
|
||||
<img src="superset-frontend/src/assets/images/postgresql.png" alt="postgresql" border="0" width="200" height="80" />
|
||||
<img src="superset-frontend/src/assets/images/mysql.png" alt="mysql" border="0" width="200" height="80" />
|
||||
<img src="superset-frontend/src/assets/images/mssql-server.png" alt="mssql-server" border="0" width="200" height="80" />
|
||||
<img src="superset-frontend/src/assets/images/db2.png" alt="db2" border="0" width="200" height="80" />
|
||||
<img src="superset-frontend/src/assets/images/sqlite.png" alt="sqlite" border="0" width="200" height="80" />
|
||||
<img src="superset-frontend/src/assets/images/sybase.png" alt="sybase" border="0" width="200" height="80" />
|
||||
<img src="superset-frontend/src/assets/images/mariadb.png" alt="mariadb" border="0" width="200" height="80" />
|
||||
<img src="superset-frontend/src/assets/images/vertica.png" alt="vertica" border="0" width="200" height="80" />
|
||||
<img src="superset-frontend/src/assets/images/oracle.png" alt="oracle" border="0" width="200" height="80" />
|
||||
<img src="superset-frontend/src/assets/images/firebird.png" alt="firebird" border="0" width="200" height="80" />
|
||||
<img src="superset-frontend/src/assets/images/greenplum.png" alt="greenplum" border="0" width="200" height="80" />
|
||||
<img src="superset-frontend/src/assets/images/clickhouse.png" alt="clickhouse" border="0" width="200" height="80" />
|
||||
<img src="superset-frontend/src/assets/images/exasol.png" alt="exasol" border="0" width="200" height="80" />
|
||||
<img src="superset-frontend/src/assets/images/monet-db.png" alt="monet-db" border="0" width="200" height="80" />
|
||||
<img src="superset-frontend/src/assets/images/apache-kylin.png" alt="apache-kylin" border="0" width="200" height="80"/>
|
||||
<img src="superset-frontend/src/assets/images/hologres.png" alt="hologres" border="0" width="200" height="80"/>
|
||||
<img src="superset-frontend/src/assets/images/netezza.png" alt="netezza" border="0" width="200" height="80"/>
|
||||
<img src="superset-frontend/src/assets/images/pinot.png" alt="pinot" border="0" width="200" height="80"/>
|
||||
<img src="superset-frontend/src/assets/images/teradata.png" alt="teradata" border="0" width="200" height="80"/>
|
||||
<img src="superset-frontend/src/assets/images/yugabyte.png" alt="yugabyte" border="0" width="200" height="80"/>
|
||||
<img src="superset-frontend/src/assets/images/databend.png" alt="databend" border="0" width="200" height="80"/>
|
||||
<img src="superset-frontend/src/assets/images/starrocks.png" alt="starrocks" border="0" width="200" height="80"/>
|
||||
<img src="superset-frontend/src/assets/images/doris.png" alt="doris" border="0" width="200" height="80"/>
|
||||
<img src="https://superset.apache.org/img/databases/redshift.png" alt="redshift" border="0" width="200"/>
|
||||
<img src="https://superset.apache.org/img/databases/google-biquery.png" alt="google-biquery" border="0" width="200"/>
|
||||
<img src="https://superset.apache.org/img/databases/snowflake.png" alt="snowflake" border="0" width="200"/>
|
||||
<img src="https://superset.apache.org/img/databases/trino.png" alt="trino" border="0" width="150" />
|
||||
<img src="https://superset.apache.org/img/databases/presto.png" alt="presto" border="0" width="200"/>
|
||||
<img src="https://superset.apache.org/img/databases/databricks.png" alt="databricks" border="0" width="160" />
|
||||
<img src="https://superset.apache.org/img/databases/druid.png" alt="druid" border="0" width="200" />
|
||||
<img src="https://superset.apache.org/img/databases/firebolt.png" alt="firebolt" border="0" width="200" />
|
||||
<img src="https://superset.apache.org/img/databases/timescale.png" alt="timescale" border="0" width="200" />
|
||||
<img src="https://superset.apache.org/img/databases/rockset.png" alt="rockset" border="0" width="200" />
|
||||
<img src="https://superset.apache.org/img/databases/postgresql.png" alt="postgresql" border="0" width="200" />
|
||||
<img src="https://superset.apache.org/img/databases/mysql.png" alt="mysql" border="0" width="200" />
|
||||
<img src="https://superset.apache.org/img/databases/mssql-server.png" alt="mssql-server" border="0" width="200" />
|
||||
<img src="https://superset.apache.org/img/databases/imb-db2.svg" alt="db2" border="0" width="220" />
|
||||
<img src="https://superset.apache.org/img/databases/sqlite.png" alt="sqlite" border="0" width="200" />
|
||||
<img src="https://superset.apache.org/img/databases/sybase.png" alt="sybase" border="0" width="200" />
|
||||
<img src="https://superset.apache.org/img/databases/mariadb.png" alt="mariadb" border="0" width="200" />
|
||||
<img src="https://superset.apache.org/img/databases/vertica.png" alt="vertica" border="0" width="200" />
|
||||
<img src="https://superset.apache.org/img/databases/oracle.png" alt="oracle" border="0" width="200" />
|
||||
<img src="https://superset.apache.org/img/databases/firebird.png" alt="firebird" border="0" width="200" />
|
||||
<img src="https://superset.apache.org/img/databases/greenplum.png" alt="greenplum" border="0" width="200" />
|
||||
<img src="https://superset.apache.org/img/databases/clickhouse.png" alt="clickhouse" border="0" width="200" />
|
||||
<img src="https://superset.apache.org/img/databases/exasol.png" alt="exasol" border="0" width="160" />
|
||||
<img src="https://superset.apache.org/img/databases/monet-db.png" alt="monet-db" border="0" width="200" />
|
||||
<img src="https://superset.apache.org/img/databases/apache-kylin.png" alt="apache-kylin" border="0" width="80"/>
|
||||
<img src="https://superset.apache.org/img/databases/hologres.png" alt="hologres" border="0" width="80"/>
|
||||
<img src="https://superset.apache.org/img/databases/netezza.png" alt="netezza" border="0" width="80"/>
|
||||
<img src="https://superset.apache.org/img/databases/pinot.png" alt="pinot" border="0" width="200" />
|
||||
<img src="https://superset.apache.org/img/databases/teradata.png" alt="teradata" border="0" width="200" />
|
||||
<img src="https://superset.apache.org/img/databases/yugabyte.png" alt="yugabyte" border="0" width="200" />
|
||||
<img src="https://superset.apache.org/img/databases/databend.png" alt="databend" border="0" width="200" />
|
||||
<img src="https://superset.apache.org/img/databases/starrocks.png" alt="starrocks" border="0" width="200" />
|
||||
<img src="https://superset.apache.org/img/databases/doris.png" alt="doris" border="0" width="200" />
|
||||
</p>
|
||||
|
||||
**A more comprehensive list of supported databases** along with the configuration instructions can be found [here](https://superset.apache.org/docs/databases/installing-database-drivers).
|
||||
**A more comprehensive list of supported databases** along with the configuration instructions can be found [here](https://superset.apache.org/docs/configuration/databases).
|
||||
|
||||
Want to add support for your datastore or data engine? Read more [here](https://superset.apache.org/docs/frequently-asked-questions#does-superset-work-with-insert-database-engine-here) about the technical requirements.
|
||||
|
||||
## Installation and Configuration
|
||||
|
||||
[Extended documentation for Superset](https://superset.apache.org/docs/installation/installing-superset-using-docker-compose)
|
||||
[Extended documentation for Superset](https://superset.apache.org/docs/installation/docker-compose)
|
||||
|
||||
## Get Involved
|
||||
|
||||
|
|
@ -159,26 +165,22 @@ how to set up a development environment.
|
|||
|
||||
## Resources
|
||||
|
||||
- [Superset "In the Wild"](RESOURCES/INTHEWILD.md) - open a PR to add your org to the list!
|
||||
- [Feature Flags](RESOURCES/FEATURE_FLAGS.md) - the status of Superset's Feature Flags.
|
||||
- [Standard Roles](RESOURCES/STANDARD_ROLES.md) - How RBAC permissions map to roles.
|
||||
- [Superset "In the Wild"](https://github.com/apache/superset/blob/master/RESOURCES/INTHEWILD.md) - open a PR to add your org to the list!
|
||||
- [Feature Flags](https://github.com/apache/superset/blob/master/RESOURCES/FEATURE_FLAGS.md) - the status of Superset's Feature Flags.
|
||||
- [Standard Roles](https://github.com/apache/superset/blob/master/RESOURCES/STANDARD_ROLES.md) - How RBAC permissions map to roles.
|
||||
- [Superset Wiki](https://github.com/apache/superset/wiki) - Tons of additional community resources: best practices, community content and other information.
|
||||
- [Superset SIPs](https://github.com/orgs/apache/projects/170) - The status of Superset's SIPs (Superset Improvement Proposals) for both consensus and implementation status.
|
||||
|
||||
Superset 2.0!
|
||||
- [Superset 2.0 Meetup](https://preset.io/events/superset-2-0-meetup/)
|
||||
- [Superset 2.0 Release Notes](https://github.com/apache/superset/tree/master/RELEASING/release-notes-2-0)
|
||||
|
||||
Understanding the Superset Points of View
|
||||
- [The Case for Dataset-Centric Visualization](https://preset.io/blog/dataset-centric-visualization/)
|
||||
- [Understanding the Superset Semantic Layer](https://preset.io/blog/understanding-superset-semantic-layer/)
|
||||
|
||||
|
||||
- Getting Started with Superset
|
||||
- [Superset in 2 Minutes using Docker Compose](https://superset.apache.org/docs/installation/installing-superset-using-docker-compose#installing-superset-locally-using-docker-compose)
|
||||
- [Installing Database Drivers](https://superset.apache.org/docs/databases/docker-add-drivers/)
|
||||
- [Superset in 2 Minutes using Docker Compose](https://superset.apache.org/docs/installation/docker-compose#installing-superset-locally-using-docker-compose)
|
||||
- [Installing Database Drivers](https://superset.apache.org/docs/configuration/databases#installing-database-drivers)
|
||||
- [Building New Database Connectors](https://preset.io/blog/building-database-connector/)
|
||||
- [Create Your First Dashboard](https://superset.apache.org/docs/creating-charts-dashboards/first-dashboard)
|
||||
- [Create Your First Dashboard](https://superset.apache.org/docs/using-superset/creating-your-first-dashboard/)
|
||||
- [Comprehensive Tutorial for Contributing Code to Apache Superset
|
||||
](https://preset.io/blog/tutorial-contributing-code-to-apache-superset/)
|
||||
- [Resources to master Superset by Preset](https://preset.io/resources/)
|
||||
|
|
@ -202,10 +204,10 @@ Understanding the Superset Points of View
|
|||
- [Superset API](https://superset.apache.org/docs/rest-api)
|
||||
|
||||
## Repo Activity
|
||||
<a href="https://next.ossinsight.io/widgets/official/compose-last-28-days-stats?repo_id=39464018" target="_blank" style="display: block" align="center">
|
||||
<a href="https://next.ossinsight.io/widgets/official/compose-last-28-days-stats?repo_id=39464018" target="_blank" align="center">
|
||||
<picture>
|
||||
<source media="(prefers-color-scheme: dark)" srcset="https://next.ossinsight.io/widgets/official/compose-last-28-days-stats/thumbnail.png?repo_id=39464018&image_size=auto&color_scheme=dark" width="655" height="auto">
|
||||
<img alt="Performance Stats of apache/superset - Last 28 days" src="https://next.ossinsight.io/widgets/official/compose-last-28-days-stats/thumbnail.png?repo_id=39464018&image_size=auto&color_scheme=light" width="655" height="auto">
|
||||
<source media="(prefers-color-scheme: dark)" srcset="https://next.ossinsight.io/widgets/official/compose-last-28-days-stats/thumbnail.png?repo_id=39464018&image_size=auto&color_scheme=dark" width="655" height="auto" />
|
||||
<img alt="Performance Stats of apache/superset - Last 28 days" src="https://next.ossinsight.io/widgets/official/compose-last-28-days-stats/thumbnail.png?repo_id=39464018&image_size=auto&color_scheme=light" width="655" height="auto" />
|
||||
</picture>
|
||||
</a>
|
||||
|
||||
|
|
|
|||
|
|
@ -506,3 +506,18 @@ and re-push the proper images and tags through this interface. The action
|
|||
takes the version (ie `3.1.1`), the git reference (any SHA, tag or branch
|
||||
reference), and whether to force the `latest` Docker tag on the
|
||||
generated images.
|
||||
|
||||
### Npm Release
|
||||
You might want to publish the latest @superset-ui release to npm
|
||||
```bash
|
||||
cd superset/superset-frontend
|
||||
```
|
||||
An automated GitHub action will run and generate a new tag, which will contain a version number provided as a parameter.
|
||||
```bash
|
||||
export GH_TOKEN={GITHUB_TOKEN}
|
||||
npx lerna version {VERSION} --conventional-commits --create-release github --no-private --yes --message {COMMIT_MESSAGE}
|
||||
```
|
||||
This action will publish the specified version to npm registry.
|
||||
```bash
|
||||
npx lerna publish from-package --yes
|
||||
```
|
||||
|
|
|
|||
|
|
@ -94,10 +94,10 @@ class GitChangeLog:
|
|||
if not pull_request:
|
||||
pull_request = github_repo.get_pull(pr_number)
|
||||
self._github_prs[pr_number] = pull_request
|
||||
except BadCredentialsException as ex:
|
||||
except BadCredentialsException:
|
||||
print(
|
||||
f"Bad credentials to github provided"
|
||||
f" use access_token parameter or set GITHUB_TOKEN"
|
||||
"Bad credentials to github provided"
|
||||
" use access_token parameter or set GITHUB_TOKEN"
|
||||
)
|
||||
sys.exit(1)
|
||||
|
||||
|
|
@ -167,8 +167,8 @@ class GitChangeLog:
|
|||
def _get_changelog_version_head(self) -> str:
|
||||
if not len(self._logs):
|
||||
print(
|
||||
f"No changes found between revisions. "
|
||||
f"Make sure your branch is up to date."
|
||||
"No changes found between revisions. "
|
||||
"Make sure your branch is up to date."
|
||||
)
|
||||
sys.exit(1)
|
||||
return f"### {self._version} ({self._logs[0].time})"
|
||||
|
|
|
|||
|
|
@ -18,7 +18,7 @@
|
|||
-#}
|
||||
To: {{ receiver_email }}
|
||||
|
||||
Subject: [ANNOUNCE] Apache {{ project_name }} version {{ version }} Released
|
||||
Subject: [ANNOUNCE] Apache {{ project_name }} version {{ version }} released
|
||||
|
||||
Hello Community,
|
||||
|
||||
|
|
@ -33,7 +33,7 @@ https://downloads.apache.org/{{ project_module }}/{{ version }}
|
|||
The PyPI package:
|
||||
https://pypi.org/project/apache-superset/{{ version }}
|
||||
|
||||
The Change Log for the release:
|
||||
The CHANGELOG for the release:
|
||||
https://github.com/apache/{{ project_module }}/blob/{{ version }}/CHANGELOG/{{ version }}.md
|
||||
|
||||
The instructions for updating to the release:
|
||||
|
|
|
|||
|
|
@ -52,7 +52,8 @@ Negative votes:
|
|||
{% endfor -%}
|
||||
{%- endif %}
|
||||
|
||||
Link to vote thread: {{ vote_thread }}
|
||||
Link to vote thread:
|
||||
{{ vote_thread }}
|
||||
|
||||
We will work to complete the release process.
|
||||
|
||||
|
|
|
|||
|
|
@ -30,7 +30,7 @@ https://dist.apache.org/repos/dist/dev/{{ project_module }}/{{ version_rc }}/
|
|||
The Git tag for the release:
|
||||
https://github.com/apache/{{ project_module }}/tree/{{ version_rc }}
|
||||
|
||||
The change log for the release:
|
||||
The CHANGELOG for the release:
|
||||
https://github.com/apache/{{ project_module }}/blob/{{ version_rc }}/CHANGELOG/{{ version }}.md
|
||||
|
||||
The instructions for updating to the release:
|
||||
|
|
@ -39,8 +39,8 @@ https://github.com/apache/{{ project_module }}/blob/{{ version_rc }}/UPDATING.md
|
|||
Public keys are available at:
|
||||
https://www.apache.org/dist/{{ project_module }}/KEYS
|
||||
|
||||
The vote will be open for at least 72 hours or until the necessary number
|
||||
of votes are reached.
|
||||
The vote will be left open until at least 72 hours have passed
|
||||
and the necessary number of votes (3) have been reached.
|
||||
|
||||
Please vote accordingly:
|
||||
|
||||
|
|
|
|||
|
|
@ -31,7 +31,7 @@ except ModuleNotFoundError:
|
|||
RECEIVER_EMAIL = "dev@superset.apache.org"
|
||||
PROJECT_NAME = "Superset"
|
||||
PROJECT_MODULE = "superset"
|
||||
PROJECT_DESCRIPTION = "Apache Superset is a modern, enterprise-ready business intelligence web application"
|
||||
PROJECT_DESCRIPTION = "Apache Superset is a modern, enterprise-ready business intelligence web application."
|
||||
|
||||
|
||||
def string_comma_to_list(message: str) -> list[str]:
|
||||
|
|
|
|||
|
|
@ -27,6 +27,7 @@ These features are considered **unfinished** and should only be used on developm
|
|||
|
||||
[//]: # "PLEASE KEEP THE LIST SORTED ALPHABETICALLY"
|
||||
|
||||
- ALERT_REPORT_TABS
|
||||
- ENABLE_ADVANCED_DATA_TYPES
|
||||
- PRESTO_EXPAND_DATA
|
||||
- SHARE_QUERIES_VIA_KV_STORE
|
||||
|
|
@ -39,44 +40,47 @@ These features are **finished** but currently being tested. They are usable, but
|
|||
|
||||
[//]: # "PLEASE KEEP THE LIST SORTED ALPHABETICALLY"
|
||||
|
||||
- ALERT_REPORTS: [(docs)](https://superset.apache.org/docs/installation/alerts-reports)
|
||||
- ALERT_REPORTS: [(docs)](https://superset.apache.org/docs/configuration/alerts-reports)
|
||||
- ALLOW_FULL_CSV_EXPORT
|
||||
- CACHE_IMPERSONATION
|
||||
- CONFIRM_DASHBOARD_DIFF
|
||||
- DRILL_TO_DETAIL
|
||||
- DYNAMIC_PLUGINS: [(docs)](https://superset.apache.org/docs/installation/running-on-kubernetes)
|
||||
- ENABLE_SUPERSET_META_DB: [(docs)](https://superset.apache.org/docs/databases/meta-database/)
|
||||
- DYNAMIC_PLUGINS: [(docs)](https://superset.apache.org/docs/configuration/running-on-kubernetes)
|
||||
- ENABLE_SUPERSET_META_DB: [(docs)]()
|
||||
- ESTIMATE_QUERY_COST
|
||||
- GLOBAL_ASYNC_QUERIES [(docs)](https://github.com/apache/superset/blob/master/CONTRIBUTING.md#async-chart-queries)
|
||||
- HORIZONTAL_FILTER_BAR
|
||||
- PLAYWRIGHT_REPORTS_AND_THUMBNAILS
|
||||
- RLS_IN_SQLLAB
|
||||
- SSH_TUNNELING [(docs)](https://superset.apache.org/docs/installation/setup-ssh-tunneling)
|
||||
- SSH_TUNNELING [(docs)](https://superset.apache.org/docs/configuration/setup-ssh-tunneling)
|
||||
- USE_ANALAGOUS_COLORS
|
||||
|
||||
## Stable
|
||||
|
||||
These features flags are **safe for production**. They have been tested and will be supported for the foreseeable future.
|
||||
These features flags are **safe for production**. They have been tested and will be supported for the at least the current major version cycle.
|
||||
|
||||
[//]: # "PLEASE KEEP THE LIST SORTED ALPHABETICALLY"
|
||||
[//]: # "PLEASE KEEP THESE LISTS SORTED ALPHABETICALLY"
|
||||
|
||||
### Flags on the path to feature launch and flag deprecation/removal
|
||||
- DASHBOARD_VIRTUALIZATION
|
||||
- DRILL_BY
|
||||
- DISABLE_LEGACY_DATASOURCE_EDITOR
|
||||
|
||||
### Flags retained for runtime configuration
|
||||
- ALERTS_ATTACH_REPORTS
|
||||
- ALLOW_ADHOC_SUBQUERY
|
||||
- DASHBOARD_RBAC [(docs)](https://superset.apache.org/docs/creating-charts-dashboards/first-dashboard#manage-access-to-dashboards)
|
||||
- DASHBOARD_VIRTUALIZATION
|
||||
- DASHBOARD_RBAC [(docs)](https://superset.apache.org/docs/using-superset/first-dashboard#manage-access-to-dashboards)
|
||||
- DATAPANEL_CLOSED_BY_DEFAULT
|
||||
- DISABLE_LEGACY_DATASOURCE_EDITOR
|
||||
- DRILL_BY
|
||||
- DRUID_JOINS
|
||||
- EMBEDDABLE_CHARTS
|
||||
- EMBEDDED_SUPERSET
|
||||
- ENABLE_TEMPLATE_PROCESSING
|
||||
- ESCAPE_MARKDOWN_HTML
|
||||
- LISTVIEWS_DEFAULT_CARD_VIEW
|
||||
- SCHEDULED_QUERIES [(docs)](https://superset.apache.org/docs/installation/alerts-reports)
|
||||
- SCHEDULED_QUERIES [(docs)](https://superset.apache.org/docs/configuration/alerts-reports)
|
||||
- SQLLAB_BACKEND_PERSISTENCE
|
||||
- SQL_VALIDATORS_BY_ENGINE [(docs)](https://superset.apache.org/docs/installation/sql-templating)
|
||||
- THUMBNAILS [(docs)](https://superset.apache.org/docs/installation/cache)
|
||||
- SQL_VALIDATORS_BY_ENGINE [(docs)](https://superset.apache.org/docs/configuration/sql-templating)
|
||||
- THUMBNAILS [(docs)](https://superset.apache.org/docs/configuration/cache)
|
||||
|
||||
## Deprecated Flags
|
||||
|
||||
|
|
|
|||
|
|
@ -17,213 +17,211 @@ specific language governing permissions and limitations
|
|||
under the License.
|
||||
-->
|
||||
|
||||
||Admin|Alpha|Gamma|SQL_LAB|
|
||||
|---|---|---|---|---|
|
||||
|Permission/role description|Admins have all possible rights, including granting or revoking rights from other users and altering other people’s slices and dashboards.|Alpha users have access to all data sources, but they cannot grant or revoke access from other users. They are also limited to altering the objects that they own. Alpha users can add and alter data sources.|Gamma users have limited access. They can only consume data coming from data sources they have been given access to through another complementary role. They only have access to view the slices and dashboards made from data sources that they have access to. Currently Gamma users are not able to alter or add data sources. We assume that they are mostly content consumers, though they can create slices and dashboards.|The sql_lab role grants access to SQL Lab. Note that while Admin users have access to all databases by default, both Alpha and Gamma users need to be given access on a per database basis.||
|
||||
|can read on SavedQuery|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|
|
||||
|can write on SavedQuery|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|
|
||||
|can read on CssTemplate|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can write on CssTemplate|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can read on ReportSchedule|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can write on ReportSchedule|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can read on Chart|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can write on Chart|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can read on Annotation|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can write on Annotation|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can read on Dataset|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can write on Dataset|:heavy_check_mark:|:heavy_check_mark:|O|O|
|
||||
|can read on Log|:heavy_check_mark:|O|O|O|
|
||||
|can write on Log|:heavy_check_mark:|O|O|O|
|
||||
|can read on Dashboard|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can write on Dashboard|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can read on Database|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|
|
||||
|can write on Database|:heavy_check_mark:|O|O|O|
|
||||
|can read on Query|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|
|
||||
|can this form get on ResetPasswordView|:heavy_check_mark:|O|O|O|
|
||||
|can this form post on ResetPasswordView|:heavy_check_mark:|O|O|O|
|
||||
|can this form get on ResetMyPasswordView|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can this form post on ResetMyPasswordView|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can this form get on UserInfoEditView|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can this form post on UserInfoEditView|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can show on UserDBModelView|:heavy_check_mark:|O|O|O|
|
||||
|can edit on UserDBModelView|:heavy_check_mark:|O|O|O|
|
||||
|can delete on UserDBModelView|:heavy_check_mark:|O|O|O|
|
||||
|can add on UserDBModelView|:heavy_check_mark:|O|O|O|
|
||||
|can list on UserDBModelView|:heavy_check_mark:|O|O|O|
|
||||
|can userinfo on UserDBModelView|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|resetmypassword on UserDBModelView|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|resetpasswords on UserDBModelView|:heavy_check_mark:|O|O|O|
|
||||
|userinfoedit on UserDBModelView|:heavy_check_mark:|O|O|O|
|
||||
|can show on RoleModelView|:heavy_check_mark:|O|O|O|
|
||||
|can edit on RoleModelView|:heavy_check_mark:|O|O|O|
|
||||
|can delete on RoleModelView|:heavy_check_mark:|O|O|O|
|
||||
|can add on RoleModelView|:heavy_check_mark:|O|O|O|
|
||||
|can list on RoleModelView|:heavy_check_mark:|O|O|O|
|
||||
|copyrole on RoleModelView|:heavy_check_mark:|O|O|O|
|
||||
|can get on OpenApi|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can show on SwaggerView|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can get on MenuApi|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can list on AsyncEventsRestApi|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can invalidate on CacheRestApi|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can function names on Database|:heavy_check_mark:|O|O|O|
|
||||
|can query form data on Api|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can query on Api|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can time range on Api|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can this form get on CsvToDatabaseView|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can this form post on CsvToDatabaseView|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can this form get on ExcelToDatabaseView|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can this form post on ExcelToDatabaseView|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can external metadata on Datasource|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can save on Datasource|:heavy_check_mark:|:heavy_check_mark:|O|O|
|
||||
|can get on Datasource|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can my queries on SqlLab|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|
|
||||
|can log on Superset|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can schemas access for csv upload on Superset|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can import dashboards on Superset|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can schemas on Superset|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can sqllab history on Superset|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|
|
||||
|can publish on Superset|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can csv on Superset|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|
|
||||
|can slice on Superset|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can sync druid source on Superset|:heavy_check_mark:|O|O|O|
|
||||
|can explore on Superset|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can approve on Superset|:heavy_check_mark:|O|O|O|
|
||||
|can explore json on Superset|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can fetch datasource metadata on Superset|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can csrf token on Superset|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can sqllab on Superset|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|
|
||||
|can select star on Superset|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can warm up cache on Superset|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can sqllab table viz on Superset|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|
|
||||
|can available domains on Superset|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can request access on Superset|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can dashboard on Superset|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can post on TableSchemaView|:heavy_check_mark:|:heavy_check_mark:|O|O|
|
||||
|can expanded on TableSchemaView|:heavy_check_mark:|:heavy_check_mark:|O|O|
|
||||
|can delete on TableSchemaView|:heavy_check_mark:|:heavy_check_mark:|O|O|
|
||||
|can get on TabStateView|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|
|
||||
|can post on TabStateView|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|
|
||||
|can delete query on TabStateView|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|
|
||||
|can migrate query on TabStateView|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|
|
||||
|can activate on TabStateView|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|
|
||||
|can delete on TabStateView|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|
|
||||
|can put on TabStateView|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|
|
||||
|can read on SecurityRestApi|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|
|
||||
|menu access on Security|:heavy_check_mark:|O|O|O|
|
||||
|menu access on List Users|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|menu access on List Roles|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|menu access on Action Log|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|menu access on Manage|:heavy_check_mark:|:heavy_check_mark:|O|O|
|
||||
|menu access on Annotation Layers|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|menu access on CSS Templates|:heavy_check_mark:|:heavy_check_mark:|O|O|
|
||||
|menu access on Import Dashboards|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|menu access on Data|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|menu access on Databases|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|menu access on Datasets|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|menu access on Upload a CSV|:heavy_check_mark:|:heavy_check_mark:|O|O|
|
||||
|menu access on Upload Excel|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|menu access on Charts|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|menu access on Dashboards|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|menu access on SQL Lab|:heavy_check_mark:|O|O|:heavy_check_mark:|
|
||||
|menu access on SQL Editor|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|
|
||||
|menu access on Saved Queries|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|
|
||||
|menu access on Query Search|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|
|
||||
|all datasource access on all_datasource_access|:heavy_check_mark:|:heavy_check_mark:|O|O|
|
||||
|all database access on all_database_access|:heavy_check_mark:|:heavy_check_mark:|O|O|
|
||||
|all query access on all_query_access|:heavy_check_mark:|O|O|O|
|
||||
|can edit on UserOAuthModelView|:heavy_check_mark:|O|O|O|
|
||||
|can list on UserOAuthModelView|:heavy_check_mark:|O|O|O|
|
||||
|can show on UserOAuthModelView|:heavy_check_mark:|O|O|O|
|
||||
|can userinfo on UserOAuthModelView|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can add on UserOAuthModelView|:heavy_check_mark:|O|O|O|
|
||||
|can delete on UserOAuthModelView|:heavy_check_mark:|O|O|O|
|
||||
|userinfoedit on UserOAuthModelView|:heavy_check_mark:|O|O|O|
|
||||
|can write on DynamicPlugin|:heavy_check_mark:|O|O|O|
|
||||
|can edit on DynamicPlugin|:heavy_check_mark:|O|O|O|
|
||||
|can list on DynamicPlugin|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can show on DynamicPlugin|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can download on DynamicPlugin|:heavy_check_mark:|O|O|O|
|
||||
|can add on DynamicPlugin|:heavy_check_mark:|O|O|O|
|
||||
|can delete on DynamicPlugin|:heavy_check_mark:|O|O|O|
|
||||
|can edit on RowLevelSecurityFiltersModelView|:heavy_check_mark:|O|O|O|
|
||||
|can list on RowLevelSecurityFiltersModelView|:heavy_check_mark:|O|O|O|
|
||||
|can show on RowLevelSecurityFiltersModelView|:heavy_check_mark:|O|O|O|
|
||||
|can download on RowLevelSecurityFiltersModelView|:heavy_check_mark:|O|O|O|
|
||||
|can add on RowLevelSecurityFiltersModelView|:heavy_check_mark:|O|O|O|
|
||||
|can delete on RowLevelSecurityFiltersModelView|:heavy_check_mark:|O|O|O|
|
||||
|muldelete on RowLevelSecurityFiltersModelView|:heavy_check_mark:|O|O|O|
|
||||
|can external metadata by name on Datasource|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can get value on KV|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can store on KV|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can tagged objects on TagView|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can suggestions on TagView|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can get on TagView|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can post on TagView|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can delete on TagView|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can edit on DashboardEmailScheduleView|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can list on DashboardEmailScheduleView|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can show on DashboardEmailScheduleView|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can add on DashboardEmailScheduleView|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can delete on DashboardEmailScheduleView|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|muldelete on DashboardEmailScheduleView|:heavy_check_mark:|:heavy_check_mark:|O|O|
|
||||
|can edit on SliceEmailScheduleView|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can list on SliceEmailScheduleView|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can show on SliceEmailScheduleView|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can add on SliceEmailScheduleView|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can delete on SliceEmailScheduleView|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|muldelete on SliceEmailScheduleView|:heavy_check_mark:|:heavy_check_mark:|O|O|
|
||||
|can edit on AlertModelView|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can list on AlertModelView|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can show on AlertModelView|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can add on AlertModelView|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can delete on AlertModelView|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can list on AlertLogModelView|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can show on AlertLogModelView|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can list on AlertObservationModelView|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can show on AlertObservationModelView|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|menu access on Row Level Security|:heavy_check_mark:|O|O|O|
|
||||
|menu access on Access requests|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|menu access on Home|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|menu access on Plugins|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|menu access on Dashboard Email Schedules|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|menu access on Chart Emails|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|menu access on Alerts|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|menu access on Alerts & Report|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|menu access on Scan New Datasources|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can share dashboard on Superset|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can share chart on Superset|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can this form get on ColumnarToDatabaseView|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can this form post on ColumnarToDatabaseView|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|menu access on Upload a Columnar file|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can export on Chart|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can write on DashboardFilterStateRestApi|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can read on DashboardFilterStateRestApi|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can write on DashboardPermalinkRestApi|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can read on DashboardPermalinkRestApi|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can delete embedded on Dashboard|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can set embedded on Dashboard|:heavy_check_mark:|O|O|O|
|
||||
|can export on Dashboard|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can get embedded on Dashboard|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can export on Database|:heavy_check_mark:|O|O|O|
|
||||
|can export on Dataset|:heavy_check_mark:|:heavy_check_mark:|O|O|
|
||||
|can write on ExploreFormDataRestApi|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can read on ExploreFormDataRestApi|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can write on ExplorePermalinkRestApi|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can read on ExplorePermalinkRestApi|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can export on ImportExportRestApi|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can import on ImportExportRestApi|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can export on SavedQuery|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|
|
||||
|can dashboard permalink on Superset|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can grant guest token on SecurityRestApi|:heavy_check_mark:|O|O|O|
|
||||
|can read on AdvancedDataType|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can read on EmbeddedDashboard|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can duplicate on Dataset|:heavy_check_mark:|:heavy_check_mark:|O|O|
|
||||
|can read on Explore|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can samples on Datasource|:heavy_check_mark:|:heavy_check_mark:|O|O|
|
||||
|can read on AvailableDomains|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|can get or create dataset on Dataset|:heavy_check_mark:|:heavy_check_mark:|O|O|
|
||||
|can get column values on Datasource|:heavy_check_mark:|:heavy_check_mark:|O|O|
|
||||
|can export csv on SQLLab|:heavy_check_mark:|O|O|:heavy_check_mark:|
|
||||
|can get results on SQLLab|:heavy_check_mark:|O|O|:heavy_check_mark:|
|
||||
|can execute sql query on SQLLab|:heavy_check_mark:|O|O|:heavy_check_mark:|
|
||||
|can recent activity on Log|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| |Admin|Alpha|Gamma|SQL_LAB|
|
||||
|--------------------------------------------------|---|---|---|---|
|
||||
| Permission/role description |Admins have all possible rights, including granting or revoking rights from other users and altering other people’s slices and dashboards.|Alpha users have access to all data sources, but they cannot grant or revoke access from other users. They are also limited to altering the objects that they own. Alpha users can add and alter data sources.|Gamma users have limited access. They can only consume data coming from data sources they have been given access to through another complementary role. They only have access to view the slices and dashboards made from data sources that they have access to. Currently Gamma users are not able to alter or add data sources. We assume that they are mostly content consumers, though they can create slices and dashboards.|The sql_lab role grants access to SQL Lab. Note that while Admin users have access to all databases by default, both Alpha and Gamma users need to be given access on a per database basis.||
|
||||
| can read on SavedQuery |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|
|
||||
| can write on SavedQuery |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|
|
||||
| can read on CssTemplate |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can write on CssTemplate |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can read on ReportSchedule |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can write on ReportSchedule |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can read on Chart |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can write on Chart |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can read on Annotation |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can write on Annotation |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can read on Dataset |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can write on Dataset |:heavy_check_mark:|:heavy_check_mark:|O|O|
|
||||
| can read on Log |:heavy_check_mark:|O|O|O|
|
||||
| can write on Log |:heavy_check_mark:|O|O|O|
|
||||
| can read on Dashboard |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can write on Dashboard |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can read on Database |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|
|
||||
| can write on Database |:heavy_check_mark:|O|O|O|
|
||||
| can read on Query |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|
|
||||
| can this form get on ResetPasswordView |:heavy_check_mark:|O|O|O|
|
||||
| can this form post on ResetPasswordView |:heavy_check_mark:|O|O|O|
|
||||
| can this form get on ResetMyPasswordView |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can this form post on ResetMyPasswordView |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can this form get on UserInfoEditView |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can this form post on UserInfoEditView |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can show on UserDBModelView |:heavy_check_mark:|O|O|O|
|
||||
| can edit on UserDBModelView |:heavy_check_mark:|O|O|O|
|
||||
| can delete on UserDBModelView |:heavy_check_mark:|O|O|O|
|
||||
| can add on UserDBModelView |:heavy_check_mark:|O|O|O|
|
||||
| can list on UserDBModelView |:heavy_check_mark:|O|O|O|
|
||||
| can userinfo on UserDBModelView |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| resetmypassword on UserDBModelView |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| resetpasswords on UserDBModelView |:heavy_check_mark:|O|O|O|
|
||||
| userinfoedit on UserDBModelView |:heavy_check_mark:|O|O|O|
|
||||
| can show on RoleModelView |:heavy_check_mark:|O|O|O|
|
||||
| can edit on RoleModelView |:heavy_check_mark:|O|O|O|
|
||||
| can delete on RoleModelView |:heavy_check_mark:|O|O|O|
|
||||
| can add on RoleModelView |:heavy_check_mark:|O|O|O|
|
||||
| can list on RoleModelView |:heavy_check_mark:|O|O|O|
|
||||
| copyrole on RoleModelView |:heavy_check_mark:|O|O|O|
|
||||
| can get on OpenApi |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can show on SwaggerView |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can get on MenuApi |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can list on AsyncEventsRestApi |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can invalidate on CacheRestApi |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can function names on Database |:heavy_check_mark:|O|O|O|
|
||||
| can csv upload on Database |:heavy_check_mark:|O|O|O|
|
||||
| can excel upload on Database |:heavy_check_mark:|O|O|O|
|
||||
| can query form data on Api |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can query on Api |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can time range on Api |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can external metadata on Datasource |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can save on Datasource |:heavy_check_mark:|:heavy_check_mark:|O|O|
|
||||
| can get on Datasource |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can my queries on SqlLab |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|
|
||||
| can log on Superset |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can schemas access for csv upload on Superset |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can import dashboards on Superset |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can schemas on Superset |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can sqllab history on Superset |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|
|
||||
| can publish on Superset |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can csv on Superset |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|
|
||||
| can slice on Superset |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can sync druid source on Superset |:heavy_check_mark:|O|O|O|
|
||||
| can explore on Superset |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can approve on Superset |:heavy_check_mark:|O|O|O|
|
||||
| can explore json on Superset |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can fetch datasource metadata on Superset |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can csrf token on Superset |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can sqllab on Superset |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|
|
||||
| can select star on Superset |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can warm up cache on Superset |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can sqllab table viz on Superset |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|
|
||||
| can available domains on Superset |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can request access on Superset |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can dashboard on Superset |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can post on TableSchemaView |:heavy_check_mark:|:heavy_check_mark:|O|O|
|
||||
| can expanded on TableSchemaView |:heavy_check_mark:|:heavy_check_mark:|O|O|
|
||||
| can delete on TableSchemaView |:heavy_check_mark:|:heavy_check_mark:|O|O|
|
||||
| can get on TabStateView |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|
|
||||
| can post on TabStateView |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|
|
||||
| can delete query on TabStateView |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|
|
||||
| can migrate query on TabStateView |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|
|
||||
| can activate on TabStateView |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|
|
||||
| can delete on TabStateView |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|
|
||||
| can put on TabStateView |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|
|
||||
| can read on SecurityRestApi |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|
|
||||
| menu access on Security |:heavy_check_mark:|O|O|O|
|
||||
| menu access on List Users |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| menu access on List Roles |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| menu access on Action Log |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| menu access on Manage |:heavy_check_mark:|:heavy_check_mark:|O|O|
|
||||
| menu access on Annotation Layers |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| menu access on CSS Templates |:heavy_check_mark:|:heavy_check_mark:|O|O|
|
||||
| menu access on Import Dashboards |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| menu access on Data |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| menu access on Databases |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| menu access on Datasets |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| menu access on Upload a CSV |:heavy_check_mark:|:heavy_check_mark:|O|O|
|
||||
| menu access on Upload Excel |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| menu access on Charts |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| menu access on Dashboards |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| menu access on SQL Lab |:heavy_check_mark:|O|O|:heavy_check_mark:|
|
||||
| menu access on SQL Editor |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|
|
||||
| menu access on Saved Queries |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|
|
||||
| menu access on Query Search |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|
|
||||
| all datasource access on all_datasource_access |:heavy_check_mark:|:heavy_check_mark:|O|O|
|
||||
| all database access on all_database_access |:heavy_check_mark:|:heavy_check_mark:|O|O|
|
||||
| all query access on all_query_access |:heavy_check_mark:|O|O|O|
|
||||
| can edit on UserOAuthModelView |:heavy_check_mark:|O|O|O|
|
||||
| can list on UserOAuthModelView |:heavy_check_mark:|O|O|O|
|
||||
| can show on UserOAuthModelView |:heavy_check_mark:|O|O|O|
|
||||
| can userinfo on UserOAuthModelView |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can add on UserOAuthModelView |:heavy_check_mark:|O|O|O|
|
||||
| can delete on UserOAuthModelView |:heavy_check_mark:|O|O|O|
|
||||
| userinfoedit on UserOAuthModelView |:heavy_check_mark:|O|O|O|
|
||||
| can write on DynamicPlugin |:heavy_check_mark:|O|O|O|
|
||||
| can edit on DynamicPlugin |:heavy_check_mark:|O|O|O|
|
||||
| can list on DynamicPlugin |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can show on DynamicPlugin |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can download on DynamicPlugin |:heavy_check_mark:|O|O|O|
|
||||
| can add on DynamicPlugin |:heavy_check_mark:|O|O|O|
|
||||
| can delete on DynamicPlugin |:heavy_check_mark:|O|O|O|
|
||||
| can edit on RowLevelSecurityFiltersModelView |:heavy_check_mark:|O|O|O|
|
||||
| can list on RowLevelSecurityFiltersModelView |:heavy_check_mark:|O|O|O|
|
||||
| can show on RowLevelSecurityFiltersModelView |:heavy_check_mark:|O|O|O|
|
||||
| can download on RowLevelSecurityFiltersModelView |:heavy_check_mark:|O|O|O|
|
||||
| can add on RowLevelSecurityFiltersModelView |:heavy_check_mark:|O|O|O|
|
||||
| can delete on RowLevelSecurityFiltersModelView |:heavy_check_mark:|O|O|O|
|
||||
| muldelete on RowLevelSecurityFiltersModelView |:heavy_check_mark:|O|O|O|
|
||||
| can external metadata by name on Datasource |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can get value on KV |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can store on KV |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can tagged objects on TagView |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can suggestions on TagView |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can get on TagView |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can post on TagView |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can delete on TagView |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can edit on DashboardEmailScheduleView |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can list on DashboardEmailScheduleView |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can show on DashboardEmailScheduleView |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can add on DashboardEmailScheduleView |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can delete on DashboardEmailScheduleView |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| muldelete on DashboardEmailScheduleView |:heavy_check_mark:|:heavy_check_mark:|O|O|
|
||||
| can edit on SliceEmailScheduleView |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can list on SliceEmailScheduleView |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can show on SliceEmailScheduleView |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can add on SliceEmailScheduleView |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can delete on SliceEmailScheduleView |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| muldelete on SliceEmailScheduleView |:heavy_check_mark:|:heavy_check_mark:|O|O|
|
||||
| can edit on AlertModelView |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can list on AlertModelView |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can show on AlertModelView |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can add on AlertModelView |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can delete on AlertModelView |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can list on AlertLogModelView |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can show on AlertLogModelView |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can list on AlertObservationModelView |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can show on AlertObservationModelView |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| menu access on Row Level Security |:heavy_check_mark:|O|O|O|
|
||||
| menu access on Access requests |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| menu access on Home |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| menu access on Plugins |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| menu access on Dashboard Email Schedules |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| menu access on Chart Emails |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| menu access on Alerts |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| menu access on Alerts & Report |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| menu access on Scan New Datasources |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can share dashboard on Superset |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can share chart on Superset |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can this form get on ColumnarToDatabaseView |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can this form post on ColumnarToDatabaseView |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| menu access on Upload a Columnar file |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can export on Chart |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can write on DashboardFilterStateRestApi |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can read on DashboardFilterStateRestApi |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can write on DashboardPermalinkRestApi |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can read on DashboardPermalinkRestApi |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can delete embedded on Dashboard |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can set embedded on Dashboard |:heavy_check_mark:|O|O|O|
|
||||
| can export on Dashboard |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can get embedded on Dashboard |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can export on Database |:heavy_check_mark:|O|O|O|
|
||||
| can export on Dataset |:heavy_check_mark:|:heavy_check_mark:|O|O|
|
||||
| can write on ExploreFormDataRestApi |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can read on ExploreFormDataRestApi |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can write on ExplorePermalinkRestApi |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can read on ExplorePermalinkRestApi |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can export on ImportExportRestApi |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can import on ImportExportRestApi |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can export on SavedQuery |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|
|
||||
| can dashboard permalink on Superset |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can grant guest token on SecurityRestApi |:heavy_check_mark:|O|O|O|
|
||||
| can read on AdvancedDataType |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can read on EmbeddedDashboard |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can duplicate on Dataset |:heavy_check_mark:|:heavy_check_mark:|O|O|
|
||||
| can read on Explore |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can samples on Datasource |:heavy_check_mark:|:heavy_check_mark:|O|O|
|
||||
| can read on AvailableDomains |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
| can get or create dataset on Dataset |:heavy_check_mark:|:heavy_check_mark:|O|O|
|
||||
| can get column values on Datasource |:heavy_check_mark:|:heavy_check_mark:|O|O|
|
||||
| can export csv on SQLLab |:heavy_check_mark:|O|O|:heavy_check_mark:|
|
||||
| can get results on SQLLab |:heavy_check_mark:|O|O|:heavy_check_mark:|
|
||||
| can execute sql query on SQLLab |:heavy_check_mark:|O|O|:heavy_check_mark:|
|
||||
| can recent activity on Log |:heavy_check_mark:|:heavy_check_mark:|:heavy_check_mark:|O|
|
||||
|
|
|
|||
|
|
@ -38,6 +38,15 @@ assists people when migrating to a new version.
|
|||
- [27697](https://github.com/apache/superset/pull/27697) [minor] flask-session bump leads to them
|
||||
deprecating `SESSION_USE_SIGNER`, check your configs as this flag won't do anything moving
|
||||
forward.
|
||||
- [27849](https://github.com/apache/superset/pull/27849/) More of an FYI, but we have a
|
||||
new config `SLACK_ENABLE_AVATARS` (False by default) that works in conjunction with
|
||||
set `SLACK_API_TOKEN` to fetch and serve Slack avatar links
|
||||
- [28134](https://github.com/apache/superset/pull/28134/) The default logging level was changed
|
||||
from DEBUG to INFO - which is the normal/sane default logging level for most software.
|
||||
- [28205](https://github.com/apache/superset/pull/28205) The permission `all_database_access` now
|
||||
more clearly provides access to all databases, as specified in its name. Before it only allowed
|
||||
listing all databases in CRUD-view and dropdown and didn't provide access to data as it
|
||||
seemed the name would imply.
|
||||
|
||||
## 4.0.0
|
||||
|
||||
|
|
|
|||
{kind=link}
Binary file not shown.
|
After Width: | Height: | Size: 10 KiB |
|
|
@ -14,6 +14,13 @@
|
|||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
|
||||
# -----------------------------------------------------------------------
|
||||
# We don't support docker-compose for production environments.
|
||||
# If you choose to use this type of deployment make sure to
|
||||
# create you own docker environment file (docker/.env) with your own
|
||||
# unique random secure passwords and SECRET_KEY.
|
||||
# -----------------------------------------------------------------------
|
||||
x-superset-image: &superset-image apachesuperset.docker.scarf.sh/apache/superset:${TAG:-latest}
|
||||
x-superset-depends-on: &superset-depends-on
|
||||
- db
|
||||
|
|
@ -33,7 +40,11 @@ services:
|
|||
- redis:/data
|
||||
|
||||
db:
|
||||
env_file: docker/.env
|
||||
env_file:
|
||||
- path: docker/.env # default
|
||||
required: true
|
||||
- path: docker/.env-local # optional override
|
||||
required: false
|
||||
image: postgres:15
|
||||
container_name: superset_db
|
||||
restart: unless-stopped
|
||||
|
|
@ -42,7 +53,11 @@ services:
|
|||
- ./docker/docker-entrypoint-initdb.d:/docker-entrypoint-initdb.d
|
||||
|
||||
superset:
|
||||
env_file: docker/.env
|
||||
env_file:
|
||||
- path: docker/.env # default
|
||||
required: true
|
||||
- path: docker/.env-local # optional override
|
||||
required: false
|
||||
image: *superset-image
|
||||
container_name: superset_app
|
||||
command: ["/app/docker/docker-bootstrap.sh", "app-gunicorn"]
|
||||
|
|
@ -57,7 +72,11 @@ services:
|
|||
image: *superset-image
|
||||
container_name: superset_init
|
||||
command: ["/app/docker/docker-init.sh"]
|
||||
env_file: docker/.env
|
||||
env_file:
|
||||
- path: docker/.env # default
|
||||
required: true
|
||||
- path: docker/.env-local # optional override
|
||||
required: false
|
||||
depends_on: *superset-depends-on
|
||||
user: "root"
|
||||
volumes: *superset-volumes
|
||||
|
|
@ -68,7 +87,11 @@ services:
|
|||
image: *superset-image
|
||||
container_name: superset_worker
|
||||
command: ["/app/docker/docker-bootstrap.sh", "worker"]
|
||||
env_file: docker/.env
|
||||
env_file:
|
||||
- path: docker/.env # default
|
||||
required: true
|
||||
- path: docker/.env-local # optional override
|
||||
required: false
|
||||
restart: unless-stopped
|
||||
depends_on: *superset-depends-on
|
||||
user: "root"
|
||||
|
|
@ -84,7 +107,11 @@ services:
|
|||
image: *superset-image
|
||||
container_name: superset_worker_beat
|
||||
command: ["/app/docker/docker-bootstrap.sh", "beat"]
|
||||
env_file: docker/.env
|
||||
env_file:
|
||||
- path: docker/.env # default
|
||||
required: true
|
||||
- path: docker/.env-local # optional override
|
||||
required: false
|
||||
restart: unless-stopped
|
||||
depends_on: *superset-depends-on
|
||||
user: "root"
|
||||
|
|
|
|||
|
|
@ -14,6 +14,13 @@
|
|||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
|
||||
# -----------------------------------------------------------------------
|
||||
# We don't support docker-compose for production environments.
|
||||
# If you choose to use this type of deployment make sure to
|
||||
# create you own docker environment file (docker/.env) with your own
|
||||
# unique random secure passwords and SECRET_KEY.
|
||||
# -----------------------------------------------------------------------
|
||||
x-superset-depends-on: &superset-depends-on
|
||||
- db
|
||||
- redis
|
||||
|
|
@ -38,7 +45,11 @@ services:
|
|||
- redis:/data
|
||||
|
||||
db:
|
||||
env_file: docker/.env
|
||||
env_file:
|
||||
- path: docker/.env # default
|
||||
required: true
|
||||
- path: docker/.env-local # optional override
|
||||
required: false
|
||||
image: postgres:15
|
||||
container_name: superset_db
|
||||
restart: unless-stopped
|
||||
|
|
@ -47,7 +58,11 @@ services:
|
|||
- ./docker/docker-entrypoint-initdb.d:/docker-entrypoint-initdb.d
|
||||
|
||||
superset:
|
||||
env_file: docker/.env
|
||||
env_file:
|
||||
- path: docker/.env # default
|
||||
required: true
|
||||
- path: docker/.env-local # optional override
|
||||
required: false
|
||||
build:
|
||||
<<: *common-build
|
||||
container_name: superset_app
|
||||
|
|
@ -64,7 +79,11 @@ services:
|
|||
build:
|
||||
<<: *common-build
|
||||
command: ["/app/docker/docker-init.sh"]
|
||||
env_file: docker/.env
|
||||
env_file:
|
||||
- path: docker/.env # default
|
||||
required: true
|
||||
- path: docker/.env-local # optional override
|
||||
required: false
|
||||
depends_on: *superset-depends-on
|
||||
user: "root"
|
||||
volumes: *superset-volumes
|
||||
|
|
@ -76,7 +95,11 @@ services:
|
|||
<<: *common-build
|
||||
container_name: superset_worker
|
||||
command: ["/app/docker/docker-bootstrap.sh", "worker"]
|
||||
env_file: docker/.env
|
||||
env_file:
|
||||
- path: docker/.env # default
|
||||
required: true
|
||||
- path: docker/.env-local # optional override
|
||||
required: false
|
||||
restart: unless-stopped
|
||||
depends_on: *superset-depends-on
|
||||
user: "root"
|
||||
|
|
@ -93,7 +116,11 @@ services:
|
|||
<<: *common-build
|
||||
container_name: superset_worker_beat
|
||||
command: ["/app/docker/docker-bootstrap.sh", "beat"]
|
||||
env_file: docker/.env
|
||||
env_file:
|
||||
- path: docker/.env # default
|
||||
required: true
|
||||
- path: docker/.env-local # optional override
|
||||
required: false
|
||||
restart: unless-stopped
|
||||
depends_on: *superset-depends-on
|
||||
user: "root"
|
||||
|
|
|
|||
|
|
@ -14,6 +14,13 @@
|
|||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
|
||||
# -----------------------------------------------------------------------
|
||||
# We don't support docker-compose for production environments.
|
||||
# If you choose to use this type of deployment make sure to
|
||||
# create you own docker environment file (docker/.env) with your own
|
||||
# unique random secure passwords and SECRET_KEY.
|
||||
# -----------------------------------------------------------------------
|
||||
x-superset-user: &superset-user root
|
||||
x-superset-depends-on: &superset-depends-on
|
||||
- db
|
||||
|
|
@ -32,7 +39,6 @@ x-common-build: &common-build
|
|||
cache_from:
|
||||
- apache/superset-cache:3.10-slim-bookworm
|
||||
|
||||
version: "4.0"
|
||||
services:
|
||||
nginx:
|
||||
image: nginx:latest
|
||||
|
|
@ -54,7 +60,11 @@ services:
|
|||
- redis:/data
|
||||
|
||||
db:
|
||||
env_file: docker/.env
|
||||
env_file:
|
||||
- path: docker/.env # default
|
||||
required: true
|
||||
- path: docker/.env-local # optional override
|
||||
required: false
|
||||
image: postgres:15
|
||||
container_name: superset_db
|
||||
restart: unless-stopped
|
||||
|
|
@ -65,7 +75,11 @@ services:
|
|||
- ./docker/docker-entrypoint-initdb.d:/docker-entrypoint-initdb.d
|
||||
|
||||
superset:
|
||||
env_file: docker/.env
|
||||
env_file:
|
||||
- path: docker/.env # default
|
||||
required: true
|
||||
- path: docker/.env-local # optional override
|
||||
required: false
|
||||
build:
|
||||
<<: *common-build
|
||||
container_name: superset_app
|
||||
|
|
@ -79,12 +93,11 @@ services:
|
|||
depends_on: *superset-depends-on
|
||||
volumes: *superset-volumes
|
||||
environment:
|
||||
CYPRESS_CONFIG: "${CYPRESS_CONFIG}"
|
||||
CYPRESS_CONFIG: "${CYPRESS_CONFIG:-}"
|
||||
|
||||
superset-websocket:
|
||||
container_name: superset_websocket
|
||||
build: ./superset-websocket
|
||||
image: superset-websocket
|
||||
ports:
|
||||
- 8080:8080
|
||||
extra_hosts:
|
||||
|
|
@ -105,6 +118,10 @@ services:
|
|||
- ./superset-websocket:/home/superset-websocket
|
||||
- /home/superset-websocket/node_modules
|
||||
- /home/superset-websocket/dist
|
||||
|
||||
# Mounting a config file that contains a dummy secret required to boot up.
|
||||
# do not use this docker-compose in production
|
||||
- ./docker/superset-websocket/config.json:/home/superset-websocket/config.json
|
||||
environment:
|
||||
- PORT=8080
|
||||
- REDIS_HOST=redis
|
||||
|
|
@ -116,12 +133,16 @@ services:
|
|||
<<: *common-build
|
||||
container_name: superset_init
|
||||
command: ["/app/docker/docker-init.sh"]
|
||||
env_file: docker/.env
|
||||
env_file:
|
||||
- path: docker/.env # default
|
||||
required: true
|
||||
- path: docker/.env-local # optional override
|
||||
required: false
|
||||
depends_on: *superset-depends-on
|
||||
user: *superset-user
|
||||
volumes: *superset-volumes
|
||||
environment:
|
||||
CYPRESS_CONFIG: "${CYPRESS_CONFIG}"
|
||||
CYPRESS_CONFIG: "${CYPRESS_CONFIG:-}"
|
||||
healthcheck:
|
||||
disable: true
|
||||
|
||||
|
|
@ -130,12 +151,14 @@ services:
|
|||
environment:
|
||||
# set this to false if you have perf issues running the npm i; npm run dev in-docker
|
||||
# if you do so, you have to run this manually on the host, which should perform better!
|
||||
BUILD_SUPERSET_FRONTEND_IN_DOCKER: ${BUILD_SUPERSET_FRONTEND_IN_DOCKER:-true}
|
||||
SCARF_ANALYTICS: "${SCARF_ANALYTICS}"
|
||||
PUPPETEER_SKIP_CHROMIUM_DOWNLOAD: ${BUILD_SUPERSET_FRONTEND_IN_DOCKER:-false}
|
||||
SCARF_ANALYTICS: "${SCARF_ANALYTICS:-}"
|
||||
container_name: superset_node
|
||||
command: ["/app/docker/docker-frontend.sh"]
|
||||
env_file: docker/.env
|
||||
env_file:
|
||||
- path: docker/.env # default
|
||||
required: true
|
||||
- path: docker/.env-local # optional override
|
||||
required: false
|
||||
depends_on: *superset-depends-on
|
||||
volumes: *superset-volumes
|
||||
|
||||
|
|
@ -144,7 +167,11 @@ services:
|
|||
<<: *common-build
|
||||
container_name: superset_worker
|
||||
command: ["/app/docker/docker-bootstrap.sh", "worker"]
|
||||
env_file: docker/.env
|
||||
env_file:
|
||||
- path: docker/.env # default
|
||||
required: true
|
||||
- path: docker/.env-local # optional override
|
||||
required: false
|
||||
restart: unless-stopped
|
||||
depends_on: *superset-depends-on
|
||||
user: *superset-user
|
||||
|
|
@ -162,7 +189,11 @@ services:
|
|||
<<: *common-build
|
||||
container_name: superset_worker_beat
|
||||
command: ["/app/docker/docker-bootstrap.sh", "beat"]
|
||||
env_file: docker/.env
|
||||
env_file:
|
||||
- path: docker/.env # default
|
||||
required: true
|
||||
- path: docker/.env-local # optional override
|
||||
required: false
|
||||
restart: unless-stopped
|
||||
depends_on: *superset-depends-on
|
||||
user: *superset-user
|
||||
|
|
@ -175,7 +206,11 @@ services:
|
|||
<<: *common-build
|
||||
container_name: superset_tests_worker
|
||||
command: ["/app/docker/docker-bootstrap.sh", "worker"]
|
||||
env_file: docker/.env
|
||||
env_file:
|
||||
- path: docker/.env # default
|
||||
required: true
|
||||
- path: docker/.env-local # optional override
|
||||
required: false
|
||||
environment:
|
||||
DATABASE_HOST: localhost
|
||||
DATABASE_DB: test
|
||||
|
|
|
|||
10
docker/.env
10
docker/.env
|
|
@ -14,17 +14,21 @@
|
|||
# See the License for the specific language governing permissions and
|
||||
# limitations under the License.
|
||||
#
|
||||
|
||||
|
||||
COMPOSE_PROJECT_NAME=superset
|
||||
|
||||
# database configurations (do not modify)
|
||||
DATABASE_DB=superset
|
||||
DATABASE_HOST=db
|
||||
# Make sure you set this to a unique secure random value on production
|
||||
DATABASE_PASSWORD=superset
|
||||
DATABASE_USER=superset
|
||||
|
||||
EXAMPLES_DB=examples
|
||||
EXAMPLES_HOST=db
|
||||
EXAMPLES_USER=examples
|
||||
# Make sure you set this to a unique secure random value on production
|
||||
EXAMPLES_PASSWORD=examples
|
||||
EXAMPLES_PORT=5432
|
||||
|
||||
|
|
@ -34,6 +38,7 @@ DATABASE_PORT=5432
|
|||
DATABASE_DIALECT=postgresql
|
||||
POSTGRES_DB=superset
|
||||
POSTGRES_USER=superset
|
||||
# Make sure you set this to a unique secure random value on production
|
||||
POSTGRES_PASSWORD=superset
|
||||
#MYSQL_DATABASE=superset
|
||||
#MYSQL_USER=superset
|
||||
|
|
@ -52,4 +57,9 @@ CYPRESS_CONFIG=false
|
|||
SUPERSET_PORT=8088
|
||||
MAPBOX_API_KEY=''
|
||||
|
||||
# Make sure you set this to a unique secure random value on production
|
||||
SUPERSET_SECRET_KEY=TEST_NON_DEV_SECRET
|
||||
|
||||
ENABLE_PLAYWRIGHT=false
|
||||
PUPPETEER_SKIP_CHROMIUM_DOWNLOAD=true
|
||||
BUILD_SUPERSET_FRONTEND_IN_DOCKER=true
|
||||
|
|
|
|||
|
|
@ -35,14 +35,6 @@ else
|
|||
echo "Skipping local overrides"
|
||||
fi
|
||||
|
||||
#
|
||||
# playwright is an optional package - run only if it is installed
|
||||
#
|
||||
if command -v playwright > /dev/null 2>&1; then
|
||||
playwright install-deps
|
||||
playwright install chromium
|
||||
fi
|
||||
|
||||
case "${1}" in
|
||||
worker)
|
||||
echo "Starting Celery worker..."
|
||||
|
|
|
|||
|
|
@ -18,8 +18,8 @@
|
|||
set -e
|
||||
|
||||
# Packages needed for puppeteer:
|
||||
apt update
|
||||
if [ "$PUPPETEER_SKIP_CHROMIUM_DOWNLOAD" = "false" ]; then
|
||||
apt update
|
||||
apt install -y chromium
|
||||
fi
|
||||
|
||||
|
|
|
|||
|
|
@ -0,0 +1,22 @@
|
|||
{
|
||||
"port": 8080,
|
||||
"logLevel": "info",
|
||||
"logToFile": false,
|
||||
"logFilename": "app.log",
|
||||
"statsd": {
|
||||
"host": "127.0.0.1",
|
||||
"port": 8125,
|
||||
"globalTags": []
|
||||
},
|
||||
"redis": {
|
||||
"port": 6379,
|
||||
"host": "127.0.0.1",
|
||||
"password": "",
|
||||
"db": 0,
|
||||
"ssl": false
|
||||
},
|
||||
"redisStreamPrefix": "async-events-",
|
||||
"jwtAlgorithms": ["HS256"],
|
||||
"jwtSecret": "CHANGE-ME-IN-PRODUCTION-GOTTA-BE-LONG-AND-SECRET",
|
||||
"jwtCookieName": "async-token"
|
||||
}
|
||||
|
|
@ -20,3 +20,6 @@ yarn-debug.log*
|
|||
yarn-error.log*
|
||||
|
||||
docs/.zshrc
|
||||
|
||||
# Gets copied from the root of the project at build time (yarn start / yarn build)
|
||||
docs/intro.md
|
||||
|
|
|
|||
|
|
@ -0,0 +1,102 @@
|
|||
{
|
||||
"countries": [
|
||||
"Afghanistan",
|
||||
"Albania",
|
||||
"Algeria",
|
||||
"Argentina",
|
||||
"Australia",
|
||||
"Austria",
|
||||
"Belgium",
|
||||
"Bolivia",
|
||||
"Brazil",
|
||||
"Bulgaria",
|
||||
"Burundi",
|
||||
"Canada",
|
||||
"Chile",
|
||||
"China",
|
||||
"Colombia",
|
||||
"Costa Rica",
|
||||
"Cuba",
|
||||
"Cyprus",
|
||||
"Czech Republic",
|
||||
"Denmark",
|
||||
"Dominican Republic",
|
||||
"Ecuador",
|
||||
"Egypt",
|
||||
"El Salvador",
|
||||
"Estonia",
|
||||
"Ethiopia",
|
||||
"France",
|
||||
"France (regions)",
|
||||
"Finland",
|
||||
"Germany",
|
||||
"Guatemala",
|
||||
"Haiti",
|
||||
"Honduras",
|
||||
"Iceland",
|
||||
"India",
|
||||
"Indonesia",
|
||||
"Iran",
|
||||
"Italy",
|
||||
"Italy (regions)",
|
||||
"Japan",
|
||||
"Jordan",
|
||||
"Kazakhstan",
|
||||
"Kenya",
|
||||
"Korea",
|
||||
"Kuwait",
|
||||
"Kyrgyzstan",
|
||||
"Latvia",
|
||||
"Liechtenstein",
|
||||
"Lithuania",
|
||||
"Malaysia",
|
||||
"Mexico",
|
||||
"Morocco",
|
||||
"Myanmar",
|
||||
"Netherlands",
|
||||
"Nicaragua",
|
||||
"Nigeria",
|
||||
"Norway",
|
||||
"Oman",
|
||||
"Pakistan",
|
||||
"Panama",
|
||||
"Papua New Guinea",
|
||||
"Paraguay",
|
||||
"Peru",
|
||||
"Philippines",
|
||||
"Philippines (regions)",
|
||||
"Portugal",
|
||||
"Poland",
|
||||
"Puerto Rico",
|
||||
"Qatar",
|
||||
"Russia",
|
||||
"Rwanda",
|
||||
"Saint Barthelemy",
|
||||
"Saint Martin",
|
||||
"Saudi Arabia",
|
||||
"Singapore",
|
||||
"Slovenia",
|
||||
"Spain",
|
||||
"Sri Lanka",
|
||||
"Sweden",
|
||||
"Switzerland",
|
||||
"Syria",
|
||||
"Tajikistan",
|
||||
"Tanzania",
|
||||
"Thailand",
|
||||
"Timorleste",
|
||||
"Turkey",
|
||||
"Turkey (regions)",
|
||||
"Turkmenistan",
|
||||
"Uganda",
|
||||
"UK",
|
||||
"Ukraine",
|
||||
"United Arab Emirates",
|
||||
"Uruguay",
|
||||
"USA",
|
||||
"Uzbekistan",
|
||||
"Venezuela",
|
||||
"Vietnam",
|
||||
"Zambia"
|
||||
]
|
||||
}
|
||||
|
|
@ -1,11 +1,11 @@
|
|||
---
|
||||
title: Alerts and Reports
|
||||
hide_title: true
|
||||
sidebar_position: 10
|
||||
sidebar_position: 2
|
||||
version: 2
|
||||
---
|
||||
|
||||
## Alerts and Reports
|
||||
# Alerts and Reports
|
||||
|
||||
Users can configure automated alerts and reports to send dashboards or charts to an email recipient or Slack channel.
|
||||
|
||||
|
|
@ -14,28 +14,28 @@ Users can configure automated alerts and reports to send dashboards or charts to
|
|||
|
||||
Alerts and reports are disabled by default. To turn them on, you need to do some setup, described here.
|
||||
|
||||
### Requirements
|
||||
## Requirements
|
||||
|
||||
#### Commons
|
||||
### Commons
|
||||
|
||||
##### In your `superset_config.py` or `superset_config_docker.py`
|
||||
#### In your `superset_config.py` or `superset_config_docker.py`
|
||||
|
||||
- `"ALERT_REPORTS"` [feature flag](/docs/installation/configuring-superset#feature-flags) must be turned to True.
|
||||
- `"ALERT_REPORTS"` [feature flag](/docs/configuration/configuring-superset#feature-flags) must be turned to True.
|
||||
- `beat_schedule` in CeleryConfig must contain schedule for `reports.scheduler`.
|
||||
- At least one of those must be configured, depending on what you want to use:
|
||||
- emails: `SMTP_*` settings
|
||||
- Slack messages: `SLACK_API_TOKEN`
|
||||
|
||||
###### Disable dry-run mode
|
||||
##### Disable dry-run mode
|
||||
|
||||
Screenshots will be taken but no messages actually sent as long as `ALERT_REPORTS_NOTIFICATION_DRY_RUN = True`, its default value in `docker/pythonpath_dev/superset_config.py`. To disable dry-run mode and start receiving email/Slack notifications, set `ALERT_REPORTS_NOTIFICATION_DRY_RUN` to `False` in [superset config](https://github.com/apache/superset/blob/master/docker/pythonpath_dev/superset_config.py).
|
||||
|
||||
##### In your `Dockerfile`
|
||||
#### In your `Dockerfile`
|
||||
|
||||
- You must install a headless browser, for taking screenshots of the charts and dashboards. Only Firefox and Chrome are currently supported.
|
||||
> If you choose Chrome, you must also change the value of `WEBDRIVER_TYPE` to `"chrome"` in your `superset_config.py`.
|
||||
|
||||
Note: All the components required (Firefox headless browser, Redis, Postgres db, celery worker and celery beat) are present in the *dev* docker image if you are following [Installing Superset Locally](/docs/installation/installing-superset-using-docker-compose/).
|
||||
Note: All the components required (Firefox headless browser, Redis, Postgres db, celery worker and celery beat) are present in the *dev* docker image if you are following [Installing Superset Locally](/docs/installation/docker-compose/).
|
||||
All you need to do is add the required config variables described in this guide (See `Detailed Config`).
|
||||
|
||||
If you are running a non-dev docker image, e.g., a stable release like `apache/superset:3.1.0`, that image does not include a headless browser. Only the `superset_worker` container needs this headless browser to browse to the target chart or dashboard.
|
||||
|
|
@ -43,11 +43,11 @@ You can either install and configure the headless browser - see "Custom Dockerfi
|
|||
|
||||
*Note*: In this context, a "dev image" is the same application software as its corresponding non-dev image, just bundled with additional tools. So an image like `3.1.0-dev` is identical to `3.1.0` when it comes to stability, functionality, and running in production. The actual "in-development" versions of Superset - cutting-edge and unstable - are not tagged with version numbers on Docker Hub and will display version `0.0.0-dev` within the Superset UI.
|
||||
|
||||
#### Slack integration
|
||||
### Slack integration
|
||||
|
||||
To send alerts and reports to Slack channels, you need to create a new Slack Application on your workspace.
|
||||
|
||||
1. Connect to your Slack workspace, then head to <https://api.slack.com/apps>.
|
||||
1. Connect to your Slack workspace, then head to [https://api.slack.com/apps].
|
||||
2. Create a new app.
|
||||
3. Go to "OAuth & Permissions" section, and give the following scopes to your app:
|
||||
- `incoming-webhook`
|
||||
|
|
@ -61,14 +61,14 @@ To send alerts and reports to Slack channels, you need to create a new Slack App
|
|||
|
||||
Note: when you configure an alert or a report, the Slack channel list takes channel names without the leading '#' e.g. use `alerts` instead of `#alerts`.
|
||||
|
||||
#### Kubernetes-specific
|
||||
### Kubernetes-specific
|
||||
|
||||
- You must have a `celery beat` pod running. If you're using the chart included in the GitHub repository under [helm/superset](https://github.com/apache/superset/tree/master/helm/superset), you need to put `supersetCeleryBeat.enabled = true` in your values override.
|
||||
- You can see the dedicated docs about [Kubernetes installation](/docs/installation/running-on-kubernetes) for more generic details.
|
||||
- You can see the dedicated docs about [Kubernetes installation](/docs/installation/kubernetes) for more details.
|
||||
|
||||
#### Docker Compose specific
|
||||
### Docker Compose specific
|
||||
|
||||
##### You must have in your `docker-compose.yml`
|
||||
#### You must have in your `docker-compose.yml`
|
||||
|
||||
- A Redis message broker
|
||||
- PostgreSQL DB instead of SQLlite
|
||||
|
|
@ -195,14 +195,14 @@ Please refer to `ExecutorType` in the codebase for other executor types.
|
|||
its default value of `http://0.0.0.0:8080/`.
|
||||
|
||||
|
||||
### Custom Dockerfile
|
||||
## Custom Dockerfile
|
||||
|
||||
If you're running the dev version of a released Superset image, like `apache/superset:3.1.0-dev`, you should be set with the above.
|
||||
|
||||
But if you're building your own image, or starting with a non-dev version, a webdriver (and headless browser) is needed to capture screenshots of the charts and dashboards which are then sent to the recipient.
|
||||
Here's how you can modify your Dockerfile to take the screenshots either with Firefox or Chrome.
|
||||
|
||||
#### Using Firefox
|
||||
### Using Firefox
|
||||
|
||||
```docker
|
||||
FROM apache/superset:3.1.0
|
||||
|
|
@ -223,7 +223,7 @@ RUN pip install --no-cache gevent psycopg2 redis
|
|||
USER superset
|
||||
```
|
||||
|
||||
#### Using Chrome
|
||||
### Using Chrome
|
||||
|
||||
```docker
|
||||
FROM apache/superset:3.1.0
|
||||
|
|
@ -248,21 +248,21 @@ USER superset
|
|||
|
||||
Don't forget to set `WEBDRIVER_TYPE` and `WEBDRIVER_OPTION_ARGS` in your config if you use Chrome.
|
||||
|
||||
### Troubleshooting
|
||||
## Troubleshooting
|
||||
|
||||
There are many reasons that reports might not be working. Try these steps to check for specific issues.
|
||||
|
||||
#### Confirm feature flag is enabled and you have sufficient permissions
|
||||
### Confirm feature flag is enabled and you have sufficient permissions
|
||||
|
||||
If you don't see "Alerts & Reports" under the *Manage* section of the Settings dropdown in the Superset UI, you need to enable the `ALERT_REPORTS` feature flag (see above). Enable another feature flag and check to see that it took effect, to verify that your config file is getting loaded.
|
||||
|
||||
Log in as an admin user to ensure you have adequate permissions.
|
||||
|
||||
#### Check the logs of your Celery worker
|
||||
### Check the logs of your Celery worker
|
||||
|
||||
This is the best source of information about the problem. In a docker compose deployment, you can do this with a command like `docker logs superset_worker --since 1h`.
|
||||
|
||||
#### Check web browser and webdriver installation
|
||||
### Check web browser and webdriver installation
|
||||
|
||||
To take a screenshot, the worker visits the dashboard or chart using a headless browser, then takes a screenshot. If you are able to send a chart as CSV or text but can't send as PNG, your problem may lie with the browser.
|
||||
|
||||
|
|
@ -270,7 +270,7 @@ Superset docker images that have a tag ending with `-dev` have the Firefox headl
|
|||
|
||||
If you are handling the installation of that software on your own, or wish to use Chromium instead, do your own verification to ensure that the headless browser opens successfully in the worker environment.
|
||||
|
||||
#### Send a test email
|
||||
### Send a test email
|
||||
|
||||
One symptom of an invalid connection to an email server is receiving an error of `[Errno 110] Connection timed out` in your logs when the report tries to send.
|
||||
|
||||
|
|
@ -301,7 +301,7 @@ Possible fixes:
|
|||
- Some cloud hosts disable outgoing unauthenticated SMTP email to prevent spam. For instance, [Azure blocks port 25 by default on some machines](https://learn.microsoft.com/en-us/azure/virtual-network/troubleshoot-outbound-smtp-connectivity). Enable that port or use another sending method.
|
||||
- Use another set of SMTP credentials that you verify works in this setup.
|
||||
|
||||
#### Browse to your report from the worker
|
||||
### Browse to your report from the worker
|
||||
|
||||
The worker may be unable to reach the report. It will use the value of `WEBDRIVER_BASEURL` to browse to the report. If that route is invalid, or presents an authentication challenge that the worker can't pass, the report screenshot will fail.
|
||||
|
||||
|
|
@ -309,7 +309,7 @@ Check this by attempting to `curl` the URL of a report that you see in the error
|
|||
|
||||
In a deployment with authentication measures enabled like HTTPS and Single Sign-On, it may make sense to have the worker navigate directly to the Superset application running in the same location, avoiding the need to sign in. For instance, you could use `WEBDRIVER_BASEURL="http://superset_app:8088"` for a docker compose deployment, and set `"force_https": False,` in your `TALISMAN_CONFIG`.
|
||||
|
||||
### Scheduling Queries as Reports
|
||||
## Scheduling Queries as Reports
|
||||
|
||||
You can optionally allow your users to schedule queries directly in SQL Lab. This is done by adding
|
||||
extra metadata to saved queries, which are then picked up by an external scheduled (like
|
||||
|
|
@ -1,13 +1,13 @@
|
|||
---
|
||||
title: Async Queries via Celery
|
||||
hide_title: true
|
||||
sidebar_position: 9
|
||||
sidebar_position: 4
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Async Queries via Celery
|
||||
# Async Queries via Celery
|
||||
|
||||
### Celery
|
||||
## Celery
|
||||
|
||||
On large analytic databases, it’s common to run queries that execute for minutes or hours. To enable
|
||||
support for long running queries that execute beyond the typical web request’s timeout (30-60
|
||||
|
|
@ -89,7 +89,7 @@ issues arise. Please clear your existing results cache store when upgrading an e
|
|||
- SQL Lab will _only run your queries asynchronously if_ you enable **Asynchronous Query Execution**
|
||||
in your database settings (Sources > Databases > Edit record).
|
||||
|
||||
### Celery Flower
|
||||
## Celery Flower
|
||||
|
||||
Flower is a web based tool for monitoring the Celery cluster which you can install from pip:
|
||||
|
||||
|
|
@ -1,11 +1,11 @@
|
|||
---
|
||||
title: Caching
|
||||
hide_title: true
|
||||
sidebar_position: 6
|
||||
sidebar_position: 3
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Caching
|
||||
# Caching
|
||||
|
||||
Superset uses [Flask-Caching](https://flask-caching.readthedocs.io/) for caching purposes.
|
||||
Flask-Caching supports various caching backends, including Redis (recommended), Memcached,
|
||||
|
|
@ -33,7 +33,7 @@ FILTER_STATE_CACHE_CONFIG = {
|
|||
}
|
||||
```
|
||||
|
||||
### Dependencies
|
||||
## Dependencies
|
||||
|
||||
In order to use dedicated cache stores, additional python libraries must be installed
|
||||
|
||||
|
|
@ -43,7 +43,7 @@ In order to use dedicated cache stores, additional python libraries must be inst
|
|||
|
||||
These libraries can be installed using pip.
|
||||
|
||||
### Fallback Metastore Cache
|
||||
## Fallback Metastore Cache
|
||||
|
||||
Note, that some form of Filter State and Explore caching are required. If either of these caches
|
||||
are undefined, Superset falls back to using a built-in cache that stores data in the metadata
|
||||
|
|
@ -60,7 +60,7 @@ DATA_CACHE_CONFIG = {
|
|||
}
|
||||
```
|
||||
|
||||
### Chart Cache Timeout
|
||||
## Chart Cache Timeout
|
||||
|
||||
The cache timeout for charts may be overridden by the settings for an individual chart, dataset, or
|
||||
database. Each of these configurations will be checked in order before falling back to the default
|
||||
|
|
@ -69,7 +69,7 @@ value defined in `DATA_CACHE_CONFIG`.
|
|||
Note, that by setting the cache timeout to `-1`, caching for charting data can be disabled, either
|
||||
per chart, dataset or database, or by default if set in `DATA_CACHE_CONFIG`.
|
||||
|
||||
### SQL Lab Query Results
|
||||
## SQL Lab Query Results
|
||||
|
||||
Caching for SQL Lab query results is used when async queries are enabled and is configured using
|
||||
`RESULTS_BACKEND`.
|
||||
|
|
@ -77,11 +77,11 @@ Caching for SQL Lab query results is used when async queries are enabled and is
|
|||
Note that this configuration does not use a flask-caching dictionary for its configuration, but
|
||||
instead requires a cachelib object.
|
||||
|
||||
See [Async Queries via Celery](/docs/installation/async-queries-celery) for details.
|
||||
See [Async Queries via Celery](/docs/configuration/async-queries-celery) for details.
|
||||
|
||||
### Caching Thumbnails
|
||||
## Caching Thumbnails
|
||||
|
||||
This is an optional feature that can be turned on by activating it’s [feature flag](/docs/installation/configuring-superset#feature-flags) on config:
|
||||
This is an optional feature that can be turned on by activating it’s [feature flag](/docs/configuration/configuring-superset#feature-flags) on config:
|
||||
|
||||
```
|
||||
FEATURE_FLAGS = {
|
||||
|
|
@ -1,32 +1,44 @@
|
|||
---
|
||||
title: Configuring Superset
|
||||
hide_title: true
|
||||
sidebar_position: 4
|
||||
sidebar_position: 1
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Configuring Superset
|
||||
# Configuring Superset
|
||||
|
||||
### Configuration
|
||||
## superset_config.py
|
||||
|
||||
To configure your application, you need to create a file `superset_config.py`. Add this file to your
|
||||
Superset exposes hundreds of configurable parameters through its
|
||||
[config.py module](https://github.com/apache/superset/blob/master/superset/config.py). The
|
||||
variables and objects exposed act as a public interface of the bulk of what you may want
|
||||
to configure, alter and interface with. In this python module, you'll find all these
|
||||
parameters, sensible defaults, as well as rich documentation in the form of comments
|
||||
|
||||
`PYTHONPATH` or create an environment variable `SUPERSET_CONFIG_PATH` specifying the full path of the `superset_config.py`.
|
||||
To configure your application, you need to create you own configuration module, which
|
||||
will allow you to override few or many of these parameters. Instead of altering the core module,
|
||||
You'll want to define your own module (typically a file named `superset_config.py`.
|
||||
Add this file to your `PYTHONPATH` or create an environment variable
|
||||
`SUPERSET_CONFIG_PATH` specifying the full path of the `superset_config.py`.
|
||||
|
||||
For example, if deploying on Superset directly on a Linux-based system where your `superset_config.py` is under `/app` directory, you can run:
|
||||
For example, if deploying on Superset directly on a Linux-based system where your
|
||||
`superset_config.py` is under `/app` directory, you can run:
|
||||
|
||||
```bash
|
||||
export SUPERSET_CONFIG_PATH=/app/superset_config.py
|
||||
```
|
||||
|
||||
If you are using your own custom Dockerfile with official Superset image as base image, then you can add your overrides as shown below:
|
||||
If you are using your own custom Dockerfile with official Superset image as base image,
|
||||
then you can add your overrides as shown below:
|
||||
|
||||
```bash
|
||||
COPY --chown=superset superset_config.py /app/
|
||||
ENV SUPERSET_CONFIG_PATH /app/superset_config.py
|
||||
```
|
||||
|
||||
Docker compose deployments handle application configuration differently. See [https://github.com/apache/superset/tree/master/docker#readme](https://github.com/apache/superset/tree/master/docker#readme) for details.
|
||||
Docker compose deployments handle application configuration differently using specific conventions..
|
||||
Refer to the [docker-compose tips & configuration](/docs/installation/docker-compose#docker-compose-tips--configuration)
|
||||
for details.
|
||||
|
||||
The following is an example of just a few of the parameters you can set in your `superset_config.py` file:
|
||||
|
||||
|
|
@ -63,33 +75,39 @@ WTF_CSRF_TIME_LIMIT = 60 * 60 * 24 * 365
|
|||
MAPBOX_API_KEY = ''
|
||||
```
|
||||
|
||||
All the parameters and default values defined in
|
||||
[https://github.com/apache/superset/blob/master/superset/config.py](https://github.com/apache/superset/blob/master/superset/config.py)
|
||||
:::tip
|
||||
Note that it is typical to copy and paste [only] the portions of the
|
||||
core [superset/config.py](https://github.com/apache/superset/blob/master/superset/config.py) that
|
||||
you want to alter, along with the related comments into your own `superset_config.py` file.
|
||||
:::
|
||||
|
||||
All the parameters and default values defined
|
||||
in [superset/config.py](https://github.com/apache/superset/blob/master/superset/config.py)
|
||||
can be altered in your local `superset_config.py`. Administrators will want to read through the file
|
||||
to understand what can be configured locally as well as the default values in place.
|
||||
|
||||
Since `superset_config.py` acts as a Flask configuration module, it can be used to alter the
|
||||
settings Flask itself, as well as Flask extensions like `flask-wtf`, `flask-caching`, `flask-migrate`,
|
||||
and `flask-appbuilder`. Flask App Builder, the web framework used by Superset, offers many
|
||||
settings Flask itself, as well as Flask extensions that Superset bundles like
|
||||
`flask-wtf`, `flask-caching`, `flask-migrate`,
|
||||
and `flask-appbuilder`. Each one of these extensions offers intricate configurability.
|
||||
Flask App Builder, the web framework used by Superset, also offers many
|
||||
configuration settings. Please consult the
|
||||
[Flask App Builder Documentation](https://flask-appbuilder.readthedocs.org/en/latest/config.html)
|
||||
for more information on how to configure it.
|
||||
|
||||
Make sure to change:
|
||||
You'll want to change:
|
||||
|
||||
- `SQLALCHEMY_DATABASE_URI`: by default it is stored at ~/.superset/superset.db
|
||||
- `SECRET_KEY`: to a long random string
|
||||
|
||||
If you need to exempt endpoints from CSRF (e.g. if you are running a custom auth postback endpoint),
|
||||
you can add the endpoints to `WTF_CSRF_EXEMPT_LIST`:
|
||||
- `SQLALCHEMY_DATABASE_URI`: that by default points to sqlite database located at
|
||||
~/.superset/superset.db
|
||||
|
||||
```
|
||||
WTF_CSRF_EXEMPT_LIST = [‘’]
|
||||
```
|
||||
|
||||
### Specifying a SECRET_KEY
|
||||
## Specifying a SECRET_KEY
|
||||
|
||||
#### Adding an initial SECRET_KEY
|
||||
### Adding an initial SECRET_KEY
|
||||
|
||||
Superset requires a user-specified SECRET_KEY to start up. This requirement was [added in version 2.1.0 to force secure configurations](https://preset.io/blog/superset-security-update-default-secret_key-vulnerability/). Add a strong SECRET_KEY to your `superset_config.py` file like:
|
||||
|
||||
|
|
@ -99,7 +117,12 @@ SECRET_KEY = 'YOUR_OWN_RANDOM_GENERATED_SECRET_KEY'
|
|||
|
||||
You can generate a strong secure key with `openssl rand -base64 42`.
|
||||
|
||||
#### Rotating to a newer SECRET_KEY
|
||||
:::caution Use a strong secret key
|
||||
This key will be used for securely signing session cookies and encrypting sensitive information stored in Superset's application metadata database.
|
||||
Your deployment must use a complex, unique key.
|
||||
:::
|
||||
|
||||
### Rotating to a newer SECRET_KEY
|
||||
|
||||
If you wish to change your existing SECRET_KEY, add the existing SECRET_KEY to your `superset_config.py` file as
|
||||
`PREVIOUS_SECRET_KEY = `and provide your new key as `SECRET_KEY =`. You can find your current SECRET_KEY with these
|
||||
|
|
@ -112,9 +135,13 @@ from flask import current_app; print(current_app.config["SECRET_KEY"])
|
|||
|
||||
Save your `superset_config.py` with these values and then run `superset re-encrypt-secrets`.
|
||||
|
||||
### Using a production metastore
|
||||
## Setting up a production metadata database
|
||||
|
||||
By default, Superset is configured to use SQLite, which is a simple and fast way to get started
|
||||
Superset needs a database to store the information it manages, like the definitions of
|
||||
charts, dashboards, and many other things.
|
||||
|
||||
By default, Superset is configured to use [SQLite](https://www.sqlite.org/),
|
||||
a self-contained, single-file database that offers a simple and fast way to get started
|
||||
(without requiring any installation). However, for production environments,
|
||||
using SQLite is highly discouraged due to security, scalability, and data integrity reasons.
|
||||
It's important to use only the supported database engines and consider using a different
|
||||
|
|
@ -134,10 +161,17 @@ Use the following database drivers and connection strings:
|
|||
| [PostgreSQL](https://www.postgresql.org/) | `pip install psycopg2` | `postgresql://<UserName>:<DBPassword>@<Database Host>/<Database Name>` |
|
||||
| [MySQL](https://www.mysql.com/) | `pip install mysqlclient` | `mysql://<UserName>:<DBPassword>@<Database Host>/<Database Name>` |
|
||||
|
||||
:::tip
|
||||
Properly setting up metadata store is beyond the scope of this documentation. We recommend
|
||||
using a hosted managed service such as [Amazon RDS](https://aws.amazon.com/rds/) or
|
||||
[Google Cloud Databases](https://cloud.google.com/products/databases?hl=en) to handle
|
||||
service and supporting infrastructure and backup strategy.
|
||||
:::
|
||||
|
||||
To configure Superset metastore set `SQLALCHEMY_DATABASE_URI` config key on `superset_config`
|
||||
to the appropriate connection string.
|
||||
|
||||
### Running on a WSGI HTTP Server
|
||||
## Running on a WSGI HTTP Server
|
||||
|
||||
While you can run Superset on NGINX or Apache, we recommend using Gunicorn in async mode. This
|
||||
enables impressive concurrency even and is fairly easy to install and configure. Please refer to the
|
||||
|
|
@ -166,12 +200,12 @@ If you're not using Gunicorn, you may want to disable the use of `flask-compress
|
|||
Currently, Google BigQuery python sdk is not compatible with `gevent`, due to some dynamic monkeypatching on python core library by `gevent`.
|
||||
So, when you use `BigQuery` datasource on Superset, you have to use `gunicorn` worker type except `gevent`.
|
||||
|
||||
### HTTPS Configuration
|
||||
## HTTPS Configuration
|
||||
|
||||
You can configure HTTPS upstream via a load balancer or a reverse proxy (such as nginx) and do SSL/TLS Offloading before traffic reaches the Superset application. In this setup, local traffic from a Celery worker taking a snapshot of a chart for Alerts & Reports can access Superset at a `http://` URL, from behind the ingress point.
|
||||
You can also configure [SSL in Gunicorn](https://docs.gunicorn.org/en/stable/settings.html#ssl) (the Python webserver) if you are using an official Superset Docker image.
|
||||
|
||||
### Configuration Behind a Load Balancer
|
||||
## Configuration Behind a Load Balancer
|
||||
|
||||
If you are running superset behind a load balancer or reverse proxy (e.g. NGINX or ELB on AWS), you
|
||||
may need to utilize a healthcheck endpoint so that your load balancer knows if your superset
|
||||
|
|
@ -189,7 +223,7 @@ In case the reverse proxy is used for providing SSL encryption, an explicit defi
|
|||
RequestHeader set X-Forwarded-Proto "https"
|
||||
```
|
||||
|
||||
### Custom OAuth2 Configuration
|
||||
## Custom OAuth2 Configuration
|
||||
|
||||
Superset is built on Flask-AppBuilder (FAB), which supports many providers out of the box
|
||||
(GitHub, Twitter, LinkedIn, Google, Azure, etc). Beyond those, Superset can be configured to connect
|
||||
|
|
@ -288,43 +322,45 @@ CUSTOM_SECURITY_MANAGER = CustomSsoSecurityManager
|
|||
]
|
||||
```
|
||||
|
||||
### LDAP Authentication
|
||||
## LDAP Authentication
|
||||
|
||||
FAB supports authenticating user credentials against an LDAP server.
|
||||
To use LDAP you must install the [python-ldap](https://www.python-ldap.org/en/latest/installing.html) package.
|
||||
See [FAB's LDAP documentation](https://flask-appbuilder.readthedocs.io/en/latest/security.html#authentication-ldap)
|
||||
for details.
|
||||
|
||||
### Mapping LDAP or OAUTH groups to Superset roles
|
||||
## Mapping LDAP or OAUTH groups to Superset roles
|
||||
|
||||
AUTH_ROLES_MAPPING in Flask-AppBuilder is a dictionary that maps from LDAP/OAUTH group names to FAB roles.
|
||||
It is used to assign roles to users who authenticate using LDAP or OAuth.
|
||||
|
||||
#### Mapping OAUTH groups to Superset roles
|
||||
### Mapping OAUTH groups to Superset roles
|
||||
|
||||
The following AUTH_ROLES_MAPPING dictionary would map the OAUTH group "superset_users" to the Superset roles "Gamma" as well as "Alpha", and the OAUTH group "superset_admins" to the Superset role "Admin".
|
||||
The following `AUTH_ROLES_MAPPING` dictionary would map the OAUTH group "superset_users" to the Superset roles "Gamma" as well as "Alpha", and the OAUTH group "superset_admins" to the Superset role "Admin".
|
||||
|
||||
```python
|
||||
AUTH_ROLES_MAPPING = {
|
||||
"superset_users": ["Gamma","Alpha"],
|
||||
"superset_admins": ["Admin"],
|
||||
}
|
||||
```
|
||||
### Mapping LDAP groups to Superset roles
|
||||
|
||||
#### Mapping LDAP groups to Superset roles
|
||||
|
||||
The following AUTH_ROLES_MAPPING dictionary would map the LDAP DN "cn=superset_users,ou=groups,dc=example,dc=com" to the Superset roles "Gamma" as well as "Alpha", and the LDAP DN "cn=superset_admins,ou=groups,dc=example,dc=com" to the Superset role "Admin".
|
||||
The following `AUTH_ROLES_MAPPING` dictionary would map the LDAP DN "cn=superset_users,ou=groups,dc=example,dc=com" to the Superset roles "Gamma" as well as "Alpha", and the LDAP DN "cn=superset_admins,ou=groups,dc=example,dc=com" to the Superset role "Admin".
|
||||
|
||||
```python
|
||||
AUTH_ROLES_MAPPING = {
|
||||
"cn=superset_users,ou=groups,dc=example,dc=com": ["Gamma","Alpha"],
|
||||
"cn=superset_admins,ou=groups,dc=example,dc=com": ["Admin"],
|
||||
}
|
||||
```
|
||||
Note: This requires `AUTH_LDAP_SEARCH` to be set. For more details, please see the [FAB Security documentation](https://flask-appbuilder.readthedocs.io/en/latest/security.html).
|
||||
|
||||
Note: This requires AUTH_LDAP_SEARCH to be set. For more details, Please refer (FAB Security documentation)[https://flask-appbuilder.readthedocs.io/en/latest/security.html].
|
||||
### Syncing roles at login
|
||||
|
||||
#### Syncing roles at login
|
||||
You can also use the `AUTH_ROLES_SYNC_AT_LOGIN` configuration variable to control how often Flask-AppBuilder syncs the user's roles with the LDAP/OAUTH groups. If `AUTH_ROLES_SYNC_AT_LOGIN` is set to True, Flask-AppBuilder will sync the user's roles each time they log in. If `AUTH_ROLES_SYNC_AT_LOGIN` is set to False, Flask-AppBuilder will only sync the user's roles when they first register.
|
||||
|
||||
You can also use the AUTH_ROLES_SYNC_AT_LOGIN configuration variable to control how often Flask-AppBuilder syncs the user's roles with the LDAP/OAUTH groups. If AUTH_ROLES_SYNC_AT_LOGIN is set to True, Flask-AppBuilder will sync the user's roles each time they log in. If AUTH_ROLES_SYNC_AT_LOGIN is set to False, Flask-AppBuilder will only sync the user's roles when they first register.
|
||||
|
||||
### Flask app Configuration Hook
|
||||
## Flask app Configuration Hook
|
||||
|
||||
`FLASK_APP_MUTATOR` is a configuration function that can be provided in your environment, receives
|
||||
the app object and can alter it in any way. For example, add `FLASK_APP_MUTATOR` into your
|
||||
|
|
@ -347,7 +383,7 @@ def FLASK_APP_MUTATOR(app: Flask) -> None:
|
|||
app.before_request_funcs.setdefault(None, []).append(make_session_permanent)
|
||||
```
|
||||
|
||||
### Feature Flags
|
||||
## Feature Flags
|
||||
|
||||
To support a diverse set of users, Superset has some features that are not enabled by default. For
|
||||
example, some users have stronger security restrictions, while some others may not. So Superset
|
||||
|
|
@ -1,11 +1,12 @@
|
|||
---
|
||||
title: Country Map Tools
|
||||
hide_title: true
|
||||
sidebar_position: 1
|
||||
sidebar_position: 10
|
||||
version: 1
|
||||
---
|
||||
|
||||
## The Country Map Visualization
|
||||
import countriesData from '../../data/countries.json';
|
||||
|
||||
# The Country Map Visualization
|
||||
|
||||
The Country Map visualization allows you to plot lightweight choropleth maps of
|
||||
your countries by province, states, or other subdivision types. It does not rely
|
||||
|
|
@ -21,102 +22,11 @@ The current list of countries can be found in the src
|
|||
|
||||
The Country Maps visualization already ships with the maps for the following countries:
|
||||
|
||||
- Afghanistan
|
||||
- Albania
|
||||
- Algeria
|
||||
- Argentina
|
||||
- Australia
|
||||
- Austria
|
||||
- Belgium
|
||||
- Bolivia
|
||||
- Brazil
|
||||
- Bulgaria
|
||||
- Burundi
|
||||
- Canada
|
||||
- Chile
|
||||
- China
|
||||
- Colombia
|
||||
- Costa Rica
|
||||
- Cuba
|
||||
- Cyprus
|
||||
- Denmark
|
||||
- Dominican Republic
|
||||
- Ecuador
|
||||
- Egypt
|
||||
- El_salvador
|
||||
- Estonia
|
||||
- Ethiopia
|
||||
- France
|
||||
- France Regions
|
||||
- Finland
|
||||
- Germany
|
||||
- Guatemala
|
||||
- Haiti
|
||||
- Honduras
|
||||
- Iceland
|
||||
- India
|
||||
- Indonesia
|
||||
- Iran
|
||||
- Italy
|
||||
- Italy Regions
|
||||
- Japan
|
||||
- Jordan
|
||||
- Kazakhstan
|
||||
- Kenya
|
||||
- Korea
|
||||
- Kuwait
|
||||
- Kyrgyzstan
|
||||
- Latvia
|
||||
- Liechtenstein
|
||||
- Lithuania
|
||||
- Malaysia
|
||||
- Mexico
|
||||
- Morocco
|
||||
- Myanmar
|
||||
- Netherlands
|
||||
- Nicaragua
|
||||
- Nigeria
|
||||
- Norway
|
||||
- Oman
|
||||
- Pakistan
|
||||
- Panama
|
||||
- Papua New Guinea
|
||||
- Paraguay
|
||||
- Peru
|
||||
- Philippines
|
||||
- Portugal
|
||||
- Poland
|
||||
- Puerto_rico
|
||||
- Qatar
|
||||
- Russia
|
||||
- Rwanda
|
||||
- Saint Barthelemy
|
||||
- Saint Martin
|
||||
- Saudi Arabia
|
||||
- Singapore
|
||||
- Slovenia
|
||||
- Spain
|
||||
- Sri Lanka
|
||||
- Sweden
|
||||
- Switzerland
|
||||
- Syria
|
||||
- Tajikistan
|
||||
- Tanzania
|
||||
- Thailand
|
||||
- Timorleste
|
||||
- Turkey
|
||||
- Turkey Regions
|
||||
- Turkmenistan
|
||||
- Uganda
|
||||
- Uk
|
||||
- Ukraine
|
||||
- United Arab Emirates
|
||||
- Uruguay
|
||||
- USA
|
||||
- Uzbekistan
|
||||
- Venezuela
|
||||
- Vietnam
|
||||
- Zambia
|
||||
<ul style={{columns: 3}}>
|
||||
{countriesData.countries.map((country, index) => (
|
||||
<li key={index}>{country}</li>
|
||||
))}
|
||||
</ul>
|
||||
|
||||
## Adding a New Country
|
||||
|
||||
File diff suppressed because it is too large
Load Diff
|
|
@ -1,18 +1,18 @@
|
|||
---
|
||||
title: Event Logging
|
||||
hide_title: true
|
||||
sidebar_position: 7
|
||||
sidebar_position: 9
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Logging
|
||||
# Logging
|
||||
|
||||
### Event Logging
|
||||
## Event Logging
|
||||
|
||||
Superset by default logs special action events in its internal database (DBEventLogger). These logs can be accessed
|
||||
on the UI by navigating to **Security > Action Log**. You can freely customize these logs by
|
||||
implementing your own event log class.
|
||||
**When custom log class is enabled DBEventLogger is disabled and logs stop being populated in UI logs view.**
|
||||
**When custom log class is enabled DBEventLogger is disabled and logs
|
||||
stop being populated in UI logs view.**
|
||||
To achieve both, custom log class should extend built-in DBEventLogger log class.
|
||||
|
||||
Here's an example of a simple JSON-to-stdout class:
|
||||
|
|
@ -44,9 +44,10 @@ End by updating your config to pass in an instance of the logger you want to use
|
|||
EVENT_LOGGER = JSONStdOutEventLogger()
|
||||
```
|
||||
|
||||
### StatsD Logging
|
||||
## StatsD Logging
|
||||
|
||||
Superset can be instrumented to log events to StatsD if desired. Most endpoints hit are logged as
|
||||
Superset can be configured to log events to [StatsD](https://github.com/statsd/statsd)
|
||||
if desired. Most endpoints hit are logged as
|
||||
well as key events like query start and end in SQL Lab.
|
||||
|
||||
To setup StatsD logging, it’s a matter of configuring the logger in your `superset_config.py`.
|
||||
|
|
@ -1,11 +1,11 @@
|
|||
---
|
||||
title: Importing and Exporting Datasources
|
||||
hide_title: true
|
||||
sidebar_position: 2
|
||||
sidebar_position: 11
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Importing and Exporting Datasources
|
||||
# Importing and Exporting Datasources
|
||||
|
||||
The superset cli allows you to import and export datasources from and to YAML. Datasources include
|
||||
databases. The data is expected to be organized in the following hierarchy:
|
||||
|
|
@ -26,7 +26,7 @@ databases. The data is expected to be organized in the following hierarchy:
|
|||
| └── ... (more databases)
|
||||
```
|
||||
|
||||
### Exporting Datasources to YAML
|
||||
## Exporting Datasources to YAML
|
||||
|
||||
You can print your current datasources to stdout by running:
|
||||
|
||||
|
|
@ -61,7 +61,7 @@ superset export_datasource_schema
|
|||
|
||||
As a reminder, you can use the `-b` flag to include back references.
|
||||
|
||||
### Importing Datasources
|
||||
## Importing Datasources
|
||||
|
||||
In order to import datasources from a ZIP file, run:
|
||||
|
||||
|
|
@ -75,9 +75,9 @@ The optional username flag **-u** sets the user used for the datasource import.
|
|||
superset import_datasources -p <path / filename> -u 'admin'
|
||||
```
|
||||
|
||||
### Legacy Importing Datasources
|
||||
## Legacy Importing Datasources
|
||||
|
||||
#### From older versions of Superset to current version
|
||||
### From older versions of Superset to current version
|
||||
|
||||
When using Superset version 4.x.x to import from an older version (2.x.x or 3.x.x) importing is supported as the command `legacy_import_datasources` and expects a JSON or directory of JSONs. The options are `-r` for recursive and `-u` for specifying a user. Example of legacy import without options:
|
||||
|
||||
|
|
@ -85,7 +85,7 @@ When using Superset version 4.x.x to import from an older version (2.x.x or 3.x.
|
|||
superset legacy_import_datasources -p <path or filename>
|
||||
```
|
||||
|
||||
#### From older versions of Superset to older versions
|
||||
### From older versions of Superset to older versions
|
||||
|
||||
When using an older Superset version (2.x.x & 3.x.x) of Superset, the command is `import_datasources`. ZIP and YAML files are supported and to switch between them the feature flag `VERSIONED_EXPORT` is used. When `VERSIONED_EXPORT` is `True`, `import_datasources` expects a ZIP file, otherwise YAML. Example:
|
||||
|
||||
|
|
@ -1,13 +1,12 @@
|
|||
---
|
||||
title: Additional Networking Settings
|
||||
hide_title: true
|
||||
sidebar_position: 5
|
||||
title: Network and Security Settings
|
||||
sidebar_position: 7
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Additional Networking Settings
|
||||
# Network and Security Settings
|
||||
|
||||
### CORS
|
||||
## CORS
|
||||
|
||||
To configure CORS, or cross-origin resource sharing, the following dependency must be installed:
|
||||
|
||||
|
|
@ -21,7 +20,37 @@ The following keys in `superset_config.py` can be specified to configure CORS:
|
|||
- `CORS_OPTIONS`: options passed to Flask-CORS
|
||||
([documentation](https://flask-cors.corydolphin.com/en/latest/api.html#extension))
|
||||
|
||||
### Domain Sharding
|
||||
|
||||
## HTTP headers
|
||||
|
||||
Note that Superset bundles [flask-talisman](https://pypi.org/project/talisman/)
|
||||
Self-descried as a small Flask extension that handles setting HTTP headers that can help
|
||||
protect against a few common web application security issues.
|
||||
|
||||
## CSRF settings
|
||||
|
||||
Similarly, [flask-wtf](https://flask-wtf.readthedocs.io/en/0.15.x/config/) is used manage
|
||||
some CSRF configurations. If you need to exempt endpoints from CSRF (e.g. if you are
|
||||
running a custom auth postback endpoint), you can add the endpoints to `WTF_CSRF_EXEMPT_LIST`:
|
||||
|
||||
|
||||
## SSH Tunneling
|
||||
|
||||
1. Turn on feature flag
|
||||
- Change [`SSH_TUNNELING`](https://github.com/apache/superset/blob/eb8386e3f0647df6d1bbde8b42073850796cc16f/superset/config.py#L489) to `True`
|
||||
- If you want to add more security when establishing the tunnel we allow users to overwrite the `SSHTunnelManager` class [here](https://github.com/apache/superset/blob/eb8386e3f0647df6d1bbde8b42073850796cc16f/superset/config.py#L507)
|
||||
- You can also set the [`SSH_TUNNEL_LOCAL_BIND_ADDRESS`](https://github.com/apache/superset/blob/eb8386e3f0647df6d1bbde8b42073850796cc16f/superset/config.py#L508) this the host address where the tunnel will be accessible on your VPC
|
||||
|
||||
2. Create database w/ ssh tunnel enabled
|
||||
- With the feature flag enabled you should now see ssh tunnel toggle.
|
||||
- Click the toggle to enables ssh tunneling and add your credentials accordingly.
|
||||
- Superset allows for 2 different type authentication (Basic + Private Key). These credentials should come from your service provider.
|
||||
|
||||
3. Verify data is flowing
|
||||
- Once SSH tunneling has been enabled, go to SQL Lab and write a query to verify data is properly flowing.
|
||||
|
||||
|
||||
## Domain Sharding
|
||||
|
||||
Chrome allows up to 6 open connections per domain at a time. When there are more than 6 slices in
|
||||
dashboard, a lot of time fetch requests are queued up and wait for next available socket.
|
||||
|
|
@ -42,7 +71,7 @@ or add the following setting in your `superset_config.py` file if domain shards
|
|||
|
||||
- `SESSION_COOKIE_DOMAIN = '.mydomain.com'`
|
||||
|
||||
### Middleware
|
||||
## Middleware
|
||||
|
||||
Superset allows you to add your own middleware. To add your own middleware, update the
|
||||
`ADDITIONAL_MIDDLEWARE` key in your `superset_config.py`. `ADDITIONAL_MIDDLEWARE` should be a list
|
||||
|
|
@ -0,0 +1,6 @@
|
|||
---
|
||||
title: Setup SSH Tunneling
|
||||
hide_title: true
|
||||
sidebar_position: 8
|
||||
version: 1
|
||||
---
|
||||
|
|
@ -1,16 +1,16 @@
|
|||
---
|
||||
title: SQL Templating
|
||||
hide_title: true
|
||||
sidebar_position: 11
|
||||
sidebar_position: 5
|
||||
version: 1
|
||||
---
|
||||
|
||||
## SQL Templating
|
||||
# SQL Templating
|
||||
|
||||
### Jinja Templates
|
||||
## Jinja Templates
|
||||
|
||||
SQL Lab and Explore supports [Jinja templating](https://jinja.palletsprojects.com/en/2.11.x/) in queries.
|
||||
To enable templating, the `ENABLE_TEMPLATE_PROCESSING` [feature flag](/docs/installation/configuring-superset#feature-flags) needs to be enabled in
|
||||
To enable templating, the `ENABLE_TEMPLATE_PROCESSING` [feature flag](/docs/configuration/configuring-superset#feature-flags) needs to be enabled in
|
||||
`superset_config.py`. When templating is enabled, python code can be embedded in virtual datasets and
|
||||
in Custom SQL in the filter and metric controls in Explore. By default, the following variables are
|
||||
made available in the Jinja context:
|
||||
|
|
@ -168,7 +168,7 @@ FEATURE_FLAGS = {
|
|||
The available validators and names can be found in
|
||||
[sql_validators](https://github.com/apache/superset/tree/master/superset/sql_validators).
|
||||
|
||||
### Available Macros
|
||||
## Available Macros
|
||||
|
||||
In this section, we'll walkthrough the pre-defined Jinja macros in Superset.
|
||||
|
||||
|
|
@ -1,11 +1,11 @@
|
|||
---
|
||||
title: Timezones
|
||||
hide_title: true
|
||||
sidebar_position: 1
|
||||
sidebar_position: 6
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Timezones
|
||||
# Timezones
|
||||
|
||||
There are four distinct timezone components which relate to Apache Superset,
|
||||
|
||||
|
|
@ -20,7 +20,7 @@ To help make the problem somewhat tractable—given that Apache Superset has no
|
|||
|
||||
To strive for data consistency (regardless of the timezone of the client) the Apache Superset backend tries to ensure that any timestamp sent to the client has an explicit (or semi-explicit as in the case with [Epoch time](https://en.wikipedia.org/wiki/Unix_time) which is always in reference to UTC) timezone encoded within.
|
||||
|
||||
The challenge however lies with the slew of [database engines](/docs/databases/installing-database-drivers#install-database-drivers) which Apache Superset supports and various inconsistencies between their [Python Database API (DB-API)](https://www.python.org/dev/peps/pep-0249/) implementations combined with the fact that we use [Pandas](https://pandas.pydata.org/) to read SQL into a DataFrame prior to serializing to JSON. Regrettably Pandas ignores the DB-API [type_code](https://www.python.org/dev/peps/pep-0249/#type-objects) relying by default on the underlying Python type returned by the DB-API. Currently only a subset of the supported database engines work correctly with Pandas, i.e., ensuring timestamps without an explicit timestamp are serializd to JSON with the server timezone, thus guaranteeing the client will display timestamps in a consistent manner irrespective of the client's timezone.
|
||||
The challenge however lies with the slew of [database engines](/docs/configuration/databases#installing-drivers-in-docker-images) which Apache Superset supports and various inconsistencies between their [Python Database API (DB-API)](https://www.python.org/dev/peps/pep-0249/) implementations combined with the fact that we use [Pandas](https://pandas.pydata.org/) to read SQL into a DataFrame prior to serializing to JSON. Regrettably Pandas ignores the DB-API [type_code](https://www.python.org/dev/peps/pep-0249/#type-objects) relying by default on the underlying Python type returned by the DB-API. Currently only a subset of the supported database engines work correctly with Pandas, i.e., ensuring timestamps without an explicit timestamp are serializd to JSON with the server timezone, thus guaranteeing the client will display timestamps in a consistent manner irrespective of the client's timezone.
|
||||
|
||||
For example the following is a comparison of MySQL and Presto,
|
||||
|
||||
|
|
@ -1,4 +0,0 @@
|
|||
{
|
||||
"label": "Contributing",
|
||||
"position": 7
|
||||
}
|
||||
|
|
@ -1,24 +0,0 @@
|
|||
---
|
||||
title: Contributing to Superset
|
||||
hide_title: true
|
||||
sidebar_position: 1
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Contributing to Superset
|
||||
|
||||
Superset is an [Apache Software foundation](https://www.apache.org/theapacheway/index.html) project.
|
||||
The core contributors (or committers) to Superset communicate primarily in the following channels (
|
||||
which can be joined by anyone):
|
||||
|
||||
- [Mailing list](https://lists.apache.org/list.html?dev@superset.apache.org)
|
||||
- [Apache Superset Slack community](http://bit.ly/join-superset-slack)
|
||||
- [GitHub issues](https://github.com/apache/superset/issues)
|
||||
- [GitHub pull requests](https://github.com/apache/superset/pulls)
|
||||
- [GitHub discussions](https://github.com/apache/superset/discussions)
|
||||
- [Superset Community Calendar](https://superset.apache.org/community)
|
||||
|
||||
More references:
|
||||
- [Comprehensive Tutorial for Contributing Code to Apache Superset](https://preset.io/blog/tutorial-contributing-code-to-apache-superset/)
|
||||
- [CONTRIBUTING Guide on GitHub](https://github.com/apache/superset/blob/master/CONTRIBUTING.md)
|
||||
- [Superset Wiki (code guidelines and additional resources)](https://github.com/apache/superset/wiki)
|
||||
|
|
@ -0,0 +1,140 @@
|
|||
---
|
||||
title: Contributing to Superset
|
||||
sidebar_position: 1
|
||||
version: 1
|
||||
---
|
||||
|
||||
# Contributing to Superset
|
||||
|
||||
Superset is an [Apache Software foundation](https://www.apache.org/theapacheway/index.html) project.
|
||||
The core contributors (or committers) to Superset communicate primarily in the following channels (
|
||||
which can be joined by anyone):
|
||||
|
||||
- [Mailing list](https://lists.apache.org/list.html?dev@superset.apache.org)
|
||||
- [Apache Superset Slack community](http://bit.ly/join-superset-slack)
|
||||
- [GitHub issues](https://github.com/apache/superset/issues)
|
||||
- [GitHub pull requests](https://github.com/apache/superset/pulls)
|
||||
- [GitHub discussions](https://github.com/apache/superset/discussions)
|
||||
- [Superset Community Calendar](https://superset.apache.org/community)
|
||||
|
||||
More references:
|
||||
- [Comprehensive Tutorial for Contributing Code to Apache Superset](https://preset.io/blog/tutorial-contributing-code-to-apache-superset/)
|
||||
- [Superset Wiki (code guidelines and additional resources)](https://github.com/apache/superset/wiki)
|
||||
|
||||
|
||||
## Orientation
|
||||
|
||||
Here's a list of repositories that contain Superset-related packages:
|
||||
|
||||
- [apache/superset](https://github.com/apache/superset)
|
||||
is the main repository containing the `apache-superset` Python package
|
||||
distributed on
|
||||
[pypi](https://pypi.org/project/apache-superset/). This repository
|
||||
also includes Superset's main TypeScript/JavaScript bundles and react apps under
|
||||
the [superset-frontend](https://github.com/apache/superset/tree/master/superset-frontend)
|
||||
folder.
|
||||
- [github.com/apache-superset](https://github.com/apache-superset) is the
|
||||
GitHub organization under which we manage Superset-related
|
||||
small tools, forks and Superset-related experimental ideas.
|
||||
|
||||
|
||||
## Types of Contributions
|
||||
|
||||
### Report Bug
|
||||
|
||||
The best way to report a bug is to file an issue on GitHub. Please include:
|
||||
|
||||
- Your operating system name and version.
|
||||
- Superset version.
|
||||
- Detailed steps to reproduce the bug.
|
||||
- Any details about your local setup that might be helpful in troubleshooting.
|
||||
|
||||
When posting Python stack traces, please quote them using
|
||||
[Markdown blocks](https://help.github.com/articles/creating-and-highlighting-code-blocks/).
|
||||
|
||||
_Please note that feature requests opened as GitHub Issues will be moved to Discussions._
|
||||
|
||||
### Submit Ideas or Feature Requests
|
||||
|
||||
The best way is to start an ["Ideas" Discussion thread](https://github.com/apache/superset/discussions/categories/ideas) on GitHub:
|
||||
|
||||
- Explain in detail how it would work.
|
||||
- Keep the scope as narrow as possible, to make it easier to implement.
|
||||
- Remember that this is a volunteer-driven project, and that your contributions are as welcome as anyone's :)
|
||||
|
||||
To propose large features or major changes to codebase, and help usher in those changes, please create a **Superset Improvement Proposal (SIP)**. See template from [SIP-0](https://github.com/apache/superset/issues/5602)
|
||||
|
||||
### Fix Bugs
|
||||
|
||||
Look through the GitHub issues. Issues tagged with `#bug` are
|
||||
open to whoever wants to implement them.
|
||||
|
||||
### Implement Features
|
||||
|
||||
Look through the GitHub issues. Issues tagged with
|
||||
`#feature` are open to whoever wants to implement them.
|
||||
|
||||
### Improve Documentation
|
||||
|
||||
Superset could always use better documentation,
|
||||
whether as part of the official Superset docs,
|
||||
in docstrings, `docs/*.rst` or even on the web as blog posts or
|
||||
articles. See [Documentation](#documentation) for more details.
|
||||
|
||||
### Add Translations
|
||||
|
||||
If you are proficient in a non-English language, you can help translate
|
||||
text strings from Superset's UI. You can jump into the existing
|
||||
language dictionaries at
|
||||
`superset/translations/<language_code>/LC_MESSAGES/messages.po`, or
|
||||
even create a dictionary for a new language altogether.
|
||||
See [Translating](howtos#contribute-translations) for more details.
|
||||
|
||||
### Ask Questions
|
||||
|
||||
There is a dedicated [`apache-superset` tag](https://stackoverflow.com/questions/tagged/apache-superset) on [StackOverflow](https://stackoverflow.com/). Please use it when asking questions.
|
||||
|
||||
## Types of Contributors
|
||||
|
||||
Following the project governance model of the Apache Software Foundation (ASF), Apache Superset has a specific set of contributor roles:
|
||||
|
||||
### PMC Member
|
||||
|
||||
A Project Management Committee (PMC) member is a person who has been elected by the PMC to help manage the project. PMC members are responsible for the overall health of the project, including community development, release management, and project governance. PMC members are also responsible for the technical direction of the project.
|
||||
|
||||
For more information about Apache Project PMCs, please refer to https://www.apache.org/foundation/governance/pmcs.html
|
||||
|
||||
### Committer
|
||||
|
||||
A committer is a person who has been elected by the PMC to have write access (commit access) to the code repository. They can modify the code, documentation, and website and accept contributions from others.
|
||||
|
||||
The official list of committers and PMC members can be found [here](https://projects.apache.org/committee.html?superset).
|
||||
|
||||
### Contributor
|
||||
|
||||
A contributor is a person who has contributed to the project in any way, including but not limited to code, tests, documentation, issues, and discussions.
|
||||
|
||||
> You can also review the Superset project's guidelines for PMC member promotion here: https://github.com/apache/superset/wiki/Guidelines-for-promoting-Superset-Committers-to-the-Superset-PMC
|
||||
|
||||
### Security Team
|
||||
|
||||
The security team is a selected subset of PMC members, committers and non-committers who are responsible for handling security issues.
|
||||
|
||||
New members of the security team are selected by the PMC members in a vote. You can request to be added to the team by sending a message to private@superset.apache.org. However, the team should be small and focused on solving security issues, so the requests will be evaluated on a case-by-case basis and the team size will be kept relatively small, limited to only actively security-focused contributors.
|
||||
|
||||
This security team must follow the [ASF vulnerability handling process](https://apache.org/security/committers.html#asf-project-security-for-committers).
|
||||
|
||||
Each new security issue is tracked as a JIRA ticket on the [ASF's JIRA Superset security project](https://issues.apache.org/jira/secure/RapidBoard.jspa?rapidView=588&projectKey=SUPERSETSEC)
|
||||
|
||||
Security team members must:
|
||||
|
||||
- Have an [ICLA](https://www.apache.org/licenses/contributor-agreements.html) signed with Apache Software Foundation.
|
||||
- Not reveal information about pending and unfixed security issues to anyone (including their employers) unless specifically authorised by the security team members, e.g., if the security team agrees that diagnosing and solving an issue requires the involvement of external experts.
|
||||
|
||||
A release manager, the contributor overseeing the release of a specific version of Apache Superset, is by default a member of the security team. However, they are not expected to be active in assessing, discussing, and fixing security issues.
|
||||
|
||||
Security team members should also follow these general expectations:
|
||||
|
||||
- Actively participate in assessing, discussing, fixing, and releasing security issues in Superset.
|
||||
- Avoid discussing security fixes in public forums. Pull request (PR) descriptions should not contain any information about security issues. The corresponding JIRA ticket should contain a link to the PR.
|
||||
- Security team members who contribute to a fix may be listed as remediation developers in the CVE report, along with their job affiliation (if they choose to include it).
|
||||
|
|
@ -1,57 +0,0 @@
|
|||
---
|
||||
title: Conventions and Typing
|
||||
hide_title: true
|
||||
sidebar_position: 7
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Conventions
|
||||
|
||||
### Python
|
||||
|
||||
Parameters in the `config.py` (which are accessible via the Flask app.config dictionary) are assumed to always be defined and thus should be accessed directly via,
|
||||
|
||||
```python
|
||||
blueprints = app.config["BLUEPRINTS"]
|
||||
```
|
||||
|
||||
rather than,
|
||||
|
||||
```python
|
||||
blueprints = app.config.get("BLUEPRINTS")
|
||||
```
|
||||
|
||||
or similar as the later will cause typing issues. The former is of type `List[Callable]` whereas the later is of type `Optional[List[Callable]]`.
|
||||
|
||||
## Typing
|
||||
|
||||
### Python
|
||||
|
||||
To ensure clarity, consistency, all readability, _all_ new functions should use
|
||||
[type hints](https://docs.python.org/3/library/typing.html) and include a
|
||||
docstring.
|
||||
|
||||
Note per [PEP-484](https://www.python.org/dev/peps/pep-0484/#exceptions) no
|
||||
syntax for listing explicitly raised exceptions is proposed and thus the
|
||||
recommendation is to put this information in a docstring, i.e.,
|
||||
|
||||
```python
|
||||
import math
|
||||
from typing import Union
|
||||
|
||||
|
||||
def sqrt(x: Union[float, int]) -> Union[float, int]:
|
||||
"""
|
||||
Return the square root of x.
|
||||
|
||||
:param x: A number
|
||||
:returns: The square root of the given number
|
||||
:raises ValueError: If the number is negative
|
||||
"""
|
||||
|
||||
return math.sqrt(x)
|
||||
```
|
||||
|
||||
### TypeScript
|
||||
|
||||
TypeScript is fully supported and is the recommended language for writing all new frontend components. When modifying existing functions/components, migrating to TypeScript is appreciated, but not required. Examples of migrating functions/components to TypeScript can be found in [#9162](https://github.com/apache/superset/pull/9162) and [#9180](https://github.com/apache/superset/pull/9180).
|
||||
|
|
@ -1,136 +0,0 @@
|
|||
---
|
||||
title: Creating Visualization Plugins
|
||||
hide_title: true
|
||||
sidebar_position: 10
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Creating Visualization Plugins
|
||||
|
||||
Visualizations in Superset are implemented in JavaScript or TypeScript. Superset
|
||||
comes preinstalled with several visualizations types (hereafter "viz plugins") that
|
||||
can be found under the `superset-frontend/plugins` directory. Viz plugins are added to
|
||||
the application in the `superset-frontend/src/visualizations/presets/MainPreset.js`.
|
||||
The Superset project is always happy to review proposals for new high quality viz
|
||||
plugins. However, for highly custom viz types it is recommended to maintain a fork
|
||||
of Superset, and add the custom built viz plugins by hand.
|
||||
|
||||
**Note:** Additional community-generated resources about creating and deploying custom visualization plugins can be found on the [Superset Wiki](https://github.com/apache/superset/wiki/Community-Resource-Library#creating-custom-data-visualizations)
|
||||
|
||||
### Prerequisites
|
||||
|
||||
In order to create a new viz plugin, you need the following:
|
||||
|
||||
- Run MacOS or Linux (Windows is not officially supported, but may work)
|
||||
- Node.js 16
|
||||
- npm 7 or 8
|
||||
|
||||
A general familiarity with [React](https://reactjs.org/) and the npm/Node system is
|
||||
also recommended.
|
||||
|
||||
### Creating a simple Hello World viz plugin
|
||||
|
||||
To get started, you need the Superset Yeoman Generator. It is recommended to use the
|
||||
version of the template that ships with the version of Superset you are using. This
|
||||
can be installed by doing the following:
|
||||
|
||||
```bash
|
||||
npm i -g yo
|
||||
cd superset-frontend/packages/generator-superset
|
||||
npm i
|
||||
npm link
|
||||
```
|
||||
|
||||
After this you can proceed to create your viz plugin. Create a new directory for your
|
||||
viz plugin with the prefix `superset-plugin-chart` and run the Yeoman generator:
|
||||
|
||||
```bash
|
||||
mkdir /tmp/superset-plugin-chart-hello-world
|
||||
cd /tmp/superset-plugin-chart-hello-world
|
||||
```
|
||||
|
||||
Initialize the viz plugin:
|
||||
|
||||
```bash
|
||||
yo @superset-ui/superset
|
||||
```
|
||||
|
||||
After that the generator will ask a few questions (the defaults should be fine):
|
||||
|
||||
```
|
||||
$ yo @superset-ui/superset
|
||||
_-----_ ╭──────────────────────────╮
|
||||
| | │ Welcome to the │
|
||||
|--(o)--| │ generator-superset │
|
||||
`---------´ │ generator! │
|
||||
( _´U`_ ) ╰──────────────────────────╯
|
||||
/___A___\ /
|
||||
| ~ |
|
||||
__'.___.'__
|
||||
´ ` |° ´ Y `
|
||||
? Package name: superset-plugin-chart-hello-world
|
||||
? Description: Hello World
|
||||
? What type of chart would you like? Time-series chart
|
||||
create package.json
|
||||
create .gitignore
|
||||
create babel.config.js
|
||||
create jest.config.js
|
||||
create README.md
|
||||
create tsconfig.json
|
||||
create src/index.ts
|
||||
create src/plugin/buildQuery.ts
|
||||
create src/plugin/controlPanel.ts
|
||||
create src/plugin/index.ts
|
||||
create src/plugin/transformProps.ts
|
||||
create src/types.ts
|
||||
create src/SupersetPluginChartHelloWorld.tsx
|
||||
create test/index.test.ts
|
||||
create test/__mocks__/mockExportString.js
|
||||
create test/plugin/buildQuery.test.ts
|
||||
create test/plugin/transformProps.test.ts
|
||||
create types/external.d.ts
|
||||
create src/images/thumbnail.png
|
||||
```
|
||||
|
||||
To build the viz plugin, run the following commands:
|
||||
|
||||
```
|
||||
npm i --force
|
||||
npm run build
|
||||
```
|
||||
|
||||
Alternatively, to run the viz plugin in development mode (=rebuilding whenever changes
|
||||
are made), start the dev server with the following command:
|
||||
|
||||
```
|
||||
npm run dev
|
||||
```
|
||||
|
||||
To add the package to Superset, go to the `superset-frontend` subdirectory in your
|
||||
Superset source folder run
|
||||
|
||||
```bash
|
||||
npm i -S /tmp/superset-plugin-chart-hello-world
|
||||
```
|
||||
|
||||
If you publish your package to npm, you can naturally install directly from there, too.
|
||||
After this edit the `superset-frontend/src/visualizations/presets/MainPreset.js`
|
||||
and make the following changes:
|
||||
|
||||
```js
|
||||
import { SupersetPluginChartHelloWorld } from 'superset-plugin-chart-hello-world';
|
||||
```
|
||||
|
||||
to import the viz plugin and later add the following to the array that's passed to the
|
||||
`plugins` property:
|
||||
|
||||
```js
|
||||
new SupersetPluginChartHelloWorld().configure({ key: 'ext-hello-world' }),
|
||||
```
|
||||
|
||||
After that the viz plugin should show up when you run Superset, e.g. the development
|
||||
server:
|
||||
|
||||
```bash
|
||||
npm run dev-server
|
||||
```
|
||||
|
|
@ -0,0 +1,983 @@
|
|||
---
|
||||
title: Setting up a Development Environment
|
||||
sidebar_position: 3
|
||||
version: 1
|
||||
---
|
||||
# Setting up a Development Envrionment
|
||||
|
||||
The documentation in this section is a bit of a patchwork of knowledge representing the
|
||||
multitude of ways that exist to run Superset (`docker-compose`, just "docker", on "metal", using
|
||||
a Makefile).
|
||||
|
||||
:::note
|
||||
Now we have evolved to recommend and support `docker-compose` more actively as the main way
|
||||
to run Superset for development and preserve your sanity. **Most people should stick to
|
||||
the first few sections - ("Fork & Clone", "docker-compose" and "Installing Dev Tools")**
|
||||
:::
|
||||
|
||||
## Fork and Clone
|
||||
|
||||
First, [fork the repository on GitHub](https://help.github.com/articles/about-forks/),
|
||||
then clone it.
|
||||
|
||||
Second, you can clone the main repository directly, but you won't be able to send pull requests.
|
||||
|
||||
```bash
|
||||
git clone git@github.com:your-username/superset.git
|
||||
cd superset
|
||||
```
|
||||
|
||||
## docker-compose (recommended!)
|
||||
|
||||
Setting things up to squeeze an "hello world" into any part of Superset should be as simple as
|
||||
|
||||
```bash
|
||||
docker-compose up
|
||||
```
|
||||
Note that:
|
||||
- this will pull/build docker images and run a cluster of services, including:
|
||||
- A Superset **Flask web server**, mounting the local python repo/code
|
||||
- A Superset **Celery worker**, also mounting the local python repo/code
|
||||
- A Superset **Node service**, mounting, compiling and bundling the JS/TS assets
|
||||
- A Superset **Node websocket service** to power the async backend
|
||||
- **Postgres** as the metadata database and to store example datasets, charts and dashboards whic
|
||||
should be populated upon startup
|
||||
- **Redis** as the message queue for our async backend and caching backend
|
||||
- It'll load up examples into the database upon first startup
|
||||
- all other details and pointers available in
|
||||
[docker-compose.yml](https://github.com/apache/superset/blob/master/docker-compose.yml)
|
||||
- The local repository is mounted withing the services, meaning updating
|
||||
the code on the host will be reflected in the docker images
|
||||
- Superset is served at localhost:8088/
|
||||
- You can login with admin/admin
|
||||
|
||||
:::caution
|
||||
Since `docker-compose` is primarily designed to run a set of containers on **a single host**
|
||||
and can't credibly support **high availability** as a result, we do not support nor recommend
|
||||
using our `docker-compose` constructs to support production-type use-cases. For single host
|
||||
environments, we recommend using [minikube](https://minikube.sigs.k8s.io/docs/start/) along
|
||||
our [installing on k8s](https://superset.apache.org/docs/installation/running-on-kubernetes)
|
||||
documentation.
|
||||
configured to be secure.
|
||||
:::
|
||||
|
||||
## Installing Development Tools
|
||||
|
||||
:::note
|
||||
While docker-compose simplifies a lot of the setup, there are still
|
||||
many things you'll want to set up locally to power your IDE, and things like
|
||||
**commit hooks**, **linters**, and **test-runners**. Note that you can do these
|
||||
things inside docker images with commands like `docker-compose exec superset_app bash` for
|
||||
instance, but many people like to run that tooling from their host.
|
||||
:::
|
||||
|
||||
### Python environment
|
||||
|
||||
Assuming you already have a way to setup your python environments
|
||||
like `pyenv`, `virtualenv` or something else, all you should have to
|
||||
do is to install our dev, pinned python requirements bundle
|
||||
|
||||
```bash
|
||||
pip install -r requirements/development.txt
|
||||
```
|
||||
|
||||
### Git Hooks
|
||||
|
||||
Superset uses Git pre-commit hooks courtesy of [pre-commit](https://pre-commit.com/).
|
||||
To install run the following:
|
||||
|
||||
```bash
|
||||
pre-commit install
|
||||
```
|
||||
|
||||
A series of checks will now run when you make a git commit.
|
||||
|
||||
## Alternatives to docker-compose
|
||||
|
||||
:::caution
|
||||
This part of the documentation is a patchwork of information related to setting up
|
||||
development environments without `docker-compose` and are documented/supported to varying
|
||||
degrees. It's been difficult to maintain this wide array of methods and insure they're
|
||||
functioning across environments.
|
||||
:::
|
||||
|
||||
### Flask server
|
||||
|
||||
#### OS Dependencies
|
||||
|
||||
Make sure your machine meets the [OS dependencies](https://superset.apache.org/docs/installation/pypi#os-dependencies) before following these steps.
|
||||
You also need to install MySQL or [MariaDB](https://mariadb.com/downloads).
|
||||
|
||||
Ensure that you are using Python version 3.9, 3.10 or 3.11, then proceed with:
|
||||
|
||||
```bash
|
||||
# Create a virtual environment and activate it (recommended)
|
||||
python3 -m venv venv # setup a python3 virtualenv
|
||||
source venv/bin/activate
|
||||
|
||||
# Install external dependencies
|
||||
pip install -r requirements/development.txt
|
||||
|
||||
# Install Superset in editable (development) mode
|
||||
pip install -e .
|
||||
|
||||
# Initialize the database
|
||||
superset db upgrade
|
||||
|
||||
# Create an admin user in your metadata database (use `admin` as username to be able to load the examples)
|
||||
superset fab create-admin
|
||||
|
||||
# Create default roles and permissions
|
||||
superset init
|
||||
|
||||
# Load some data to play with.
|
||||
# Note: you MUST have previously created an admin user with the username `admin` for this command to work.
|
||||
superset load-examples
|
||||
|
||||
# Start the Flask dev web server from inside your virtualenv.
|
||||
# Note that your page may not have CSS at this point.
|
||||
# See instructions below how to build the front-end assets.
|
||||
superset run -p 8088 --with-threads --reload --debugger --debug
|
||||
```
|
||||
|
||||
Or you can install via our Makefile
|
||||
|
||||
```bash
|
||||
# Create a virtual environment and activate it (recommended)
|
||||
$ python3 -m venv venv # setup a python3 virtualenv
|
||||
$ source venv/bin/activate
|
||||
|
||||
# install pip packages + pre-commit
|
||||
$ make install
|
||||
|
||||
# Install superset pip packages and setup env only
|
||||
$ make superset
|
||||
|
||||
# Setup pre-commit only
|
||||
$ make pre-commit
|
||||
```
|
||||
|
||||
**Note: the FLASK_APP env var should not need to be set, as it's currently controlled
|
||||
via `.flaskenv`, however if needed, it should be set to `superset.app:create_app()`**
|
||||
|
||||
If you have made changes to the FAB-managed templates, which are not built the same way as the newer, React-powered front-end assets, you need to start the app without the `--with-threads` argument like so:
|
||||
`superset run -p 8088 --reload --debugger --debug`
|
||||
|
||||
#### Dependencies
|
||||
|
||||
If you add a new requirement or update an existing requirement (per the `install_requires` section in `setup.py`) you must recompile (freeze) the Python dependencies to ensure that for CI, testing, etc. the build is deterministic. This can be achieved via,
|
||||
|
||||
```bash
|
||||
$ python3 -m venv venv
|
||||
$ source venv/bin/activate
|
||||
$ python3 -m pip install -r requirements/development.txt
|
||||
$ pip-compile-multi --no-upgrade
|
||||
```
|
||||
|
||||
When upgrading the version number of a single package, you should run `pip-compile-multi` with the `-P` flag:
|
||||
|
||||
```bash
|
||||
$ pip-compile-multi -P my-package
|
||||
```
|
||||
|
||||
To bring all dependencies up to date as per the restrictions defined in `setup.py` and `requirements/*.in`, run pip-compile-multi` without any flags:
|
||||
|
||||
```bash
|
||||
$ pip-compile-multi
|
||||
```
|
||||
|
||||
This should be done periodically, but it is recommended to do thorough manual testing of the application to ensure no breaking changes have been introduced that aren't caught by the unit and integration tests.
|
||||
|
||||
#### Logging to the browser console
|
||||
|
||||
This feature is only available on Python 3. When debugging your application, you can have the server logs sent directly to the browser console using the [ConsoleLog](https://github.com/betodealmeida/consolelog) package. You need to mutate the app, by adding the following to your `config.py` or `superset_config.py`:
|
||||
|
||||
```python
|
||||
from console_log import ConsoleLog
|
||||
|
||||
def FLASK_APP_MUTATOR(app):
|
||||
app.wsgi_app = ConsoleLog(app.wsgi_app, app.logger)
|
||||
```
|
||||
|
||||
Then make sure you run your WSGI server using the right worker type:
|
||||
|
||||
```bash
|
||||
gunicorn "superset.app:create_app()" -k "geventwebsocket.gunicorn.workers.GeventWebSocketWorker" -b 127.0.0.1:8088 --reload
|
||||
```
|
||||
|
||||
You can log anything to the browser console, including objects:
|
||||
|
||||
```python
|
||||
from superset import app
|
||||
app.logger.error('An exception occurred!')
|
||||
app.logger.info(form_data)
|
||||
```
|
||||
|
||||
### Frontend
|
||||
|
||||
Frontend assets (TypeScript, JavaScript, CSS, and images) must be compiled in order to properly display the web UI. The `superset-frontend` directory contains all NPM-managed frontend assets. Note that for some legacy pages there are additional frontend assets bundled with Flask-Appbuilder (e.g. jQuery and bootstrap). These are not managed by NPM and may be phased out in the future.
|
||||
|
||||
#### Prerequisite
|
||||
|
||||
##### nvm and node
|
||||
|
||||
First, be sure you are using the following versions of Node.js and npm:
|
||||
|
||||
- `Node.js`: Version 18
|
||||
- `npm`: Version 10
|
||||
|
||||
We recommend using [nvm](https://github.com/nvm-sh/nvm) to manage your node environment:
|
||||
|
||||
```bash
|
||||
curl -o- https://raw.githubusercontent.com/nvm-sh/nvm/v0.37.0/install.sh | bash
|
||||
|
||||
incase it shows '-bash: nvm: command not found'
|
||||
export NVM_DIR="$HOME/.nvm"
|
||||
[ -s "$NVM_DIR/nvm.sh" ] && \. "$NVM_DIR/nvm.sh" # This loads nvm
|
||||
[ -s "$NVM_DIR/bash_completion" ] && \. "$NVM_DIR/bash_completion" # This loads nvm bash_completion
|
||||
|
||||
cd superset-frontend
|
||||
nvm install --lts
|
||||
nvm use --lts
|
||||
```
|
||||
|
||||
Or if you use the default macOS starting with Catalina shell `zsh`, try:
|
||||
|
||||
```zsh
|
||||
sh -c "$(curl -fsSL https://raw.githubusercontent.com/nvm-sh/nvm/v0.37.0/install.sh)"
|
||||
```
|
||||
|
||||
For those interested, you may also try out [avn](https://github.com/nvm-sh/nvm#deeper-shell-integration) to automatically switch to the node version that is required to run Superset frontend.
|
||||
|
||||
#### Install dependencies
|
||||
|
||||
Install third-party dependencies listed in `package.json` via:
|
||||
|
||||
```bash
|
||||
# From the root of the repository
|
||||
cd superset-frontend
|
||||
|
||||
# Install dependencies from `package-lock.json`
|
||||
npm ci
|
||||
```
|
||||
|
||||
Note that Superset uses [Scarf](https://docs.scarf.sh) to capture telemetry/analytics about versions being installed, including the `scarf-js` npm package and an analytics pixel. As noted elsewhere in this documentation, Scarf gathers aggregated stats for the sake of security/release strategy, and does not capture/retain PII. [You can read here](https://docs.scarf.sh/package-analytics/) about the `scarf-js` package, and various means to opt out of it, but you can opt out of the npm package _and_ the pixel by setting the `SCARF_ANALYTICS` envinronment variable to `false` or opt out of the pixel by adding this setting in `superset-frontent/package.json`:
|
||||
|
||||
```json
|
||||
// your-package/package.json
|
||||
{
|
||||
// ...
|
||||
"scarfSettings": {
|
||||
"enabled": false
|
||||
}
|
||||
// ...
|
||||
}
|
||||
```
|
||||
|
||||
#### Build assets
|
||||
|
||||
There are three types of assets you can build:
|
||||
|
||||
1. `npm run build`: the production assets, CSS/JSS minified and optimized
|
||||
2. `npm run dev-server`: local development assets, with sourcemaps and hot refresh support
|
||||
3. `npm run build-instrumented`: instrumented application code for collecting code coverage from Cypress tests
|
||||
|
||||
If while using the above commands you encounter an error related to the limit of file watchers:
|
||||
|
||||
```bash
|
||||
Error: ENOSPC: System limit for number of file watchers reached
|
||||
```
|
||||
The error is thrown because the number of files monitored by the system has reached the limit.
|
||||
You can address this this error by increasing the number of inotify watchers.
|
||||
|
||||
The current value of max watches can be checked with:
|
||||
```bash
|
||||
cat /proc/sys/fs/inotify/max_user_watches
|
||||
```
|
||||
Edit the file /etc/sysctl.conf to increase this value.
|
||||
The value needs to be decided based on the system memory [(see this StackOverflow answer for more context)](https://stackoverflow.com/questions/535768/what-is-a-reasonable-amount-of-inotify-watches-with-linux).
|
||||
|
||||
Open the file in editor and add a line at the bottom specifying the max watches values.
|
||||
```bash
|
||||
fs.inotify.max_user_watches=524288
|
||||
```
|
||||
Save the file and exit editor.
|
||||
To confirm that the change succeeded, run the following command to load the updated value of max_user_watches from sysctl.conf:
|
||||
```bash
|
||||
sudo sysctl -p
|
||||
```
|
||||
|
||||
#### Webpack dev server
|
||||
|
||||
The dev server by default starts at `http://localhost:9000` and proxies the backend requests to `http://localhost:8088`.
|
||||
|
||||
So a typical development workflow is the following:
|
||||
|
||||
1. [run Superset locally](#flask-server) using Flask, on port `8088` — but don't access it directly,<br/>
|
||||
```bash
|
||||
# Install Superset and dependencies, plus load your virtual environment first, as detailed above.
|
||||
superset run -p 8088 --with-threads --reload --debugger --debug
|
||||
```
|
||||
2. in parallel, run the Webpack dev server locally on port `9000`,<br/>
|
||||
```bash
|
||||
npm run dev-server
|
||||
```
|
||||
3. access `http://localhost:9000` (the Webpack server, _not_ Flask) in your web browser. This will use the hot-reloading front-end assets from the Webpack development server while redirecting back-end queries to Flask/Superset: your changes on Superset codebase — either front or back-end — will then be reflected live in the browser.
|
||||
|
||||
It's possible to change the Webpack server settings:
|
||||
|
||||
```bash
|
||||
# Start the dev server at http://localhost:9000
|
||||
npm run dev-server
|
||||
|
||||
# Run the dev server on a non-default port
|
||||
npm run dev-server -- --port=9001
|
||||
|
||||
# Proxy backend requests to a Flask server running on a non-default port
|
||||
npm run dev-server -- --env=--supersetPort=8081
|
||||
|
||||
# Proxy to a remote backend but serve local assets
|
||||
npm run dev-server -- --env=--superset=https://superset-dev.example.com
|
||||
```
|
||||
|
||||
The `--superset=` option is useful in case you want to debug a production issue or have to setup Superset behind a firewall. It allows you to run Flask server in another environment while keep assets building locally for the best developer experience.
|
||||
|
||||
#### Other npm commands
|
||||
|
||||
Alternatively, there are other NPM commands you may find useful:
|
||||
|
||||
1. `npm run build-dev`: build assets in development mode.
|
||||
2. `npm run dev`: built dev assets in watch mode, will automatically rebuild when a file changes
|
||||
|
||||
#### Docker (docker compose)
|
||||
|
||||
See docs [here](https://superset.apache.org/docs/installation/docker-compose)
|
||||
|
||||
#### Updating NPM packages
|
||||
|
||||
Use npm in the prescribed way, making sure that
|
||||
`superset-frontend/package-lock.json` is updated according to `npm`-prescribed
|
||||
best practices.
|
||||
|
||||
#### Feature flags
|
||||
|
||||
Superset supports a server-wide feature flag system, which eases the incremental development of features. To add a new feature flag, simply modify `superset_config.py` with something like the following:
|
||||
|
||||
```python
|
||||
FEATURE_FLAGS = {
|
||||
'SCOPED_FILTER': True,
|
||||
}
|
||||
```
|
||||
|
||||
If you want to use the same flag in the client code, also add it to the FeatureFlag TypeScript enum in [@superset-ui/core](https://github.com/apache/superset/blob/master/superset-frontend/packages/superset-ui-core/src/utils/featureFlags.ts). For example,
|
||||
|
||||
```typescript
|
||||
export enum FeatureFlag {
|
||||
SCOPED_FILTER = "SCOPED_FILTER",
|
||||
}
|
||||
```
|
||||
|
||||
`superset/config.py` contains `DEFAULT_FEATURE_FLAGS` which will be overwritten by
|
||||
those specified under FEATURE_FLAGS in `superset_config.py`. For example, `DEFAULT_FEATURE_FLAGS = { 'FOO': True, 'BAR': False }` in `superset/config.py` and `FEATURE_FLAGS = { 'BAR': True, 'BAZ': True }` in `superset_config.py` will result
|
||||
in combined feature flags of `{ 'FOO': True, 'BAR': True, 'BAZ': True }`.
|
||||
|
||||
The current status of the usability of each flag (stable vs testing, etc) can be found in `RESOURCES/FEATURE_FLAGS.md`.
|
||||
|
||||
## Git Hooks
|
||||
|
||||
Superset uses Git pre-commit hooks courtesy of [pre-commit](https://pre-commit.com/). To install run the following:
|
||||
|
||||
```bash
|
||||
pip3 install -r requirements/development.txt
|
||||
pre-commit install
|
||||
```
|
||||
|
||||
A series of checks will now run when you make a git commit.
|
||||
|
||||
Alternatively it is possible to run pre-commit via tox:
|
||||
|
||||
```bash
|
||||
tox -e pre-commit
|
||||
```
|
||||
|
||||
Or by running pre-commit manually:
|
||||
|
||||
```bash
|
||||
pre-commit run --all-files
|
||||
```
|
||||
|
||||
## Linting
|
||||
|
||||
### Python
|
||||
|
||||
We use [Pylint](https://pylint.org/) for linting which can be invoked via:
|
||||
|
||||
```bash
|
||||
# for python
|
||||
tox -e pylint
|
||||
```
|
||||
|
||||
In terms of best practices please avoid blanket disabling of Pylint messages globally (via `.pylintrc`) or top-level within the file header, albeit there being a few exceptions. Disabling should occur inline as it prevents masking issues and provides context as to why said message is disabled.
|
||||
|
||||
Additionally, the Python code is auto-formatted using [Black](https://github.com/python/black) which
|
||||
is configured as a pre-commit hook. There are also numerous [editor integrations](https://black.readthedocs.io/en/stable/integrations/editors.html)
|
||||
|
||||
### TypeScript
|
||||
|
||||
```bash
|
||||
cd superset-frontend
|
||||
npm ci
|
||||
# run eslint checks
|
||||
npm run eslint -- .
|
||||
# run tsc (typescript) checks
|
||||
npm run type
|
||||
```
|
||||
|
||||
If using the eslint extension with vscode, put the following in your workspace `settings.json` file:
|
||||
|
||||
```json
|
||||
"eslint.workingDirectories": [
|
||||
"superset-frontend"
|
||||
]
|
||||
```
|
||||
|
||||
## Testing
|
||||
|
||||
### Python Testing
|
||||
|
||||
All python tests are carried out in [tox](https://tox.readthedocs.io/en/latest/index.html)
|
||||
a standardized testing framework.
|
||||
All python tests can be run with any of the tox [environments](https://tox.readthedocs.io/en/latest/example/basic.html#a-simple-tox-ini-default-environments), via,
|
||||
|
||||
```bash
|
||||
tox -e <environment>
|
||||
```
|
||||
|
||||
For example,
|
||||
|
||||
```bash
|
||||
tox -e py38
|
||||
```
|
||||
|
||||
Alternatively, you can run all tests in a single file via,
|
||||
|
||||
```bash
|
||||
tox -e <environment> -- tests/test_file.py
|
||||
```
|
||||
|
||||
or for a specific test via,
|
||||
|
||||
```bash
|
||||
tox -e <environment> -- tests/test_file.py::TestClassName::test_method_name
|
||||
```
|
||||
|
||||
Note that the test environment uses a temporary directory for defining the
|
||||
SQLite databases which will be cleared each time before the group of test
|
||||
commands are invoked.
|
||||
|
||||
There is also a utility script included in the Superset codebase to run python integration tests. The [readme can be
|
||||
found here](https://github.com/apache/superset/tree/master/scripts/tests)
|
||||
|
||||
To run all integration tests for example, run this script from the root directory:
|
||||
|
||||
```bash
|
||||
scripts/tests/run.sh
|
||||
```
|
||||
|
||||
You can run unit tests found in './tests/unit_tests' for example with pytest. It is a simple way to run an isolated test that doesn't need any database setup
|
||||
|
||||
```bash
|
||||
pytest ./link_to_test.py
|
||||
```
|
||||
|
||||
### Frontend Testing
|
||||
|
||||
We use [Jest](https://jestjs.io/) and [Enzyme](https://airbnb.io/enzyme/) to test TypeScript/JavaScript. Tests can be run with:
|
||||
|
||||
```bash
|
||||
cd superset-frontend
|
||||
npm run test
|
||||
```
|
||||
|
||||
To run a single test file:
|
||||
|
||||
```bash
|
||||
npm run test -- path/to/file.js
|
||||
```
|
||||
|
||||
### Integration Testing
|
||||
|
||||
We use [Cypress](https://www.cypress.io/) for integration tests. Tests can be run by `tox -e cypress`. To open Cypress and explore tests first setup and run test server:
|
||||
|
||||
```bash
|
||||
export SUPERSET_CONFIG=tests.integration_tests.superset_test_config
|
||||
export SUPERSET_TESTENV=true
|
||||
export CYPRESS_BASE_URL="http://localhost:8081"
|
||||
superset db upgrade
|
||||
superset load_test_users
|
||||
superset load-examples --load-test-data
|
||||
superset init
|
||||
superset run --port 8081
|
||||
```
|
||||
|
||||
Run Cypress tests:
|
||||
|
||||
```bash
|
||||
cd superset-frontend
|
||||
npm run build-instrumented
|
||||
|
||||
cd cypress-base
|
||||
npm install
|
||||
|
||||
# run tests via headless Chrome browser (requires Chrome 64+)
|
||||
npm run cypress-run-chrome
|
||||
|
||||
# run tests from a specific file
|
||||
npm run cypress-run-chrome -- --spec cypress/e2e/explore/link.test.ts
|
||||
|
||||
# run specific file with video capture
|
||||
npm run cypress-run-chrome -- --spec cypress/e2e/dashboard/index.test.js --config video=true
|
||||
|
||||
# to open the cypress ui
|
||||
npm run cypress-debug
|
||||
|
||||
# to point cypress to a url other than the default (http://localhost:8088) set the environment variable before running the script
|
||||
# e.g., CYPRESS_BASE_URL="http://localhost:9000"
|
||||
CYPRESS_BASE_URL=<your url> npm run cypress open
|
||||
```
|
||||
|
||||
See [`superset-frontend/cypress_build.sh`](https://github.com/apache/superset/blob/master/superset-frontend/cypress_build.sh).
|
||||
|
||||
As an alternative you can use docker compose environment for testing:
|
||||
|
||||
Make sure you have added below line to your /etc/hosts file:
|
||||
`127.0.0.1 db`
|
||||
|
||||
If you already have launched Docker environment please use the following command to assure a fresh database instance:
|
||||
`docker compose down -v`
|
||||
|
||||
Launch environment:
|
||||
|
||||
`CYPRESS_CONFIG=true docker compose up`
|
||||
|
||||
It will serve backend and frontend on port 8088.
|
||||
|
||||
Run Cypress tests:
|
||||
|
||||
```bash
|
||||
cd cypress-base
|
||||
npm install
|
||||
npm run cypress open
|
||||
```
|
||||
|
||||
### Debugging Server App
|
||||
|
||||
#### Local
|
||||
|
||||
For debugging locally using VSCode, you can configure a launch configuration file .vscode/launch.json such as
|
||||
|
||||
```json
|
||||
{
|
||||
"version": "0.2.0",
|
||||
"configurations": [
|
||||
{
|
||||
"name": "Python: Flask",
|
||||
"type": "python",
|
||||
"request": "launch",
|
||||
"module": "flask",
|
||||
"env": {
|
||||
"FLASK_APP": "superset",
|
||||
"SUPERSET_ENV": "development"
|
||||
},
|
||||
"args": ["run", "-p 8088", "--with-threads", "--reload", "--debugger"],
|
||||
"jinja": true,
|
||||
"justMyCode": true
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
#### Raw Docker (without docker-compose)
|
||||
|
||||
Follow these instructions to debug the Flask app running inside a docker container. Note that
|
||||
this will run a barebones Superset web server,
|
||||
|
||||
First add the following to the ./docker-compose.yaml file
|
||||
|
||||
```diff
|
||||
superset:
|
||||
env_file: docker/.env
|
||||
image: *superset-image
|
||||
container_name: superset_app
|
||||
command: ["/app/docker/docker-bootstrap.sh", "app"]
|
||||
restart: unless-stopped
|
||||
+ cap_add:
|
||||
+ - SYS_PTRACE
|
||||
ports:
|
||||
- 8088:8088
|
||||
+ - 5678:5678
|
||||
user: "root"
|
||||
depends_on: *superset-depends-on
|
||||
volumes: *superset-volumes
|
||||
environment:
|
||||
CYPRESS_CONFIG: "${CYPRESS_CONFIG}"
|
||||
```
|
||||
|
||||
Start Superset as usual
|
||||
|
||||
```bash
|
||||
docker compose up
|
||||
```
|
||||
|
||||
Install the required libraries and packages to the docker container
|
||||
|
||||
Enter the superset_app container
|
||||
|
||||
```bash
|
||||
docker exec -it superset_app /bin/bash
|
||||
root@39ce8cf9d6ab:/app#
|
||||
```
|
||||
|
||||
Run the following commands inside the container
|
||||
|
||||
```bash
|
||||
apt update
|
||||
apt install -y gdb
|
||||
apt install -y net-tools
|
||||
pip install debugpy
|
||||
```
|
||||
|
||||
Find the PID for the Flask process. Make sure to use the first PID. The Flask app will re-spawn a sub-process every time you change any of the python code. So it's important to use the first PID.
|
||||
|
||||
```bash
|
||||
ps -ef
|
||||
|
||||
UID PID PPID C STIME TTY TIME CMD
|
||||
root 1 0 0 14:09 ? 00:00:00 bash /app/docker/docker-bootstrap.sh app
|
||||
root 6 1 4 14:09 ? 00:00:04 /usr/local/bin/python /usr/bin/flask run -p 8088 --with-threads --reload --debugger --host=0.0.0.0
|
||||
root 10 6 7 14:09 ? 00:00:07 /usr/local/bin/python /usr/bin/flask run -p 8088 --with-threads --reload --debugger --host=0.0.0.0
|
||||
```
|
||||
|
||||
Inject debugpy into the running Flask process. In this case PID 6.
|
||||
|
||||
```bash
|
||||
python3 -m debugpy --listen 0.0.0.0:5678 --pid 6
|
||||
```
|
||||
|
||||
Verify that debugpy is listening on port 5678
|
||||
|
||||
```bash
|
||||
netstat -tunap
|
||||
|
||||
Active Internet connections (servers and established)
|
||||
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
|
||||
tcp 0 0 0.0.0.0:5678 0.0.0.0:* LISTEN 462/python
|
||||
tcp 0 0 0.0.0.0:8088 0.0.0.0:* LISTEN 6/python
|
||||
```
|
||||
|
||||
You are now ready to attach a debugger to the process. Using VSCode you can configure a launch configuration file .vscode/launch.json like so.
|
||||
|
||||
```json
|
||||
{
|
||||
"version": "0.2.0",
|
||||
"configurations": [
|
||||
{
|
||||
"name": "Attach to Superset App in Docker Container",
|
||||
"type": "python",
|
||||
"request": "attach",
|
||||
"connect": {
|
||||
"host": "127.0.0.1",
|
||||
"port": 5678
|
||||
},
|
||||
"pathMappings": [
|
||||
{
|
||||
"localRoot": "${workspaceFolder}",
|
||||
"remoteRoot": "/app"
|
||||
}
|
||||
]
|
||||
}
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
VSCode will not stop on breakpoints right away. We've attached to PID 6 however it does not yet know of any sub-processes. In order to "wake up" the debugger you need to modify a python file. This will trigger Flask to reload the code and create a new sub-process. This new sub-process will be detected by VSCode and breakpoints will be activated.
|
||||
|
||||
### Debugging Server App in Kubernetes Environment
|
||||
|
||||
To debug Flask running in POD inside kubernetes cluster. You'll need to make sure the pod runs as root and is granted the SYS_TRACE capability.These settings should not be used in production environments.
|
||||
|
||||
```
|
||||
securityContext:
|
||||
capabilities:
|
||||
add: ["SYS_PTRACE"]
|
||||
```
|
||||
|
||||
See (set capabilities for a container)[https://kubernetes.io/docs/tasks/configure-pod-container/security-context/#set-capabilities-for-a-container] for more details.
|
||||
|
||||
Once the pod is running as root and has the SYS_PTRACE capability it will be able to debug the Flask app.
|
||||
|
||||
You can follow the same instructions as in the docker-compose. Enter the pod and install the required library and packages; gdb, netstat and debugpy.
|
||||
|
||||
Often in a Kubernetes environment nodes are not addressable from outside the cluster. VSCode will thus be unable to remotely connect to port 5678 on a Kubernetes node. In order to do this you need to create a tunnel that port forwards 5678 to your local machine.
|
||||
|
||||
```
|
||||
kubectl port-forward pod/superset-<some random id> 5678:5678
|
||||
```
|
||||
|
||||
You can now launch your VSCode debugger with the same config as above. VSCode will connect to to 127.0.0.1:5678 which is forwarded by kubectl to your remote kubernetes POD.
|
||||
|
||||
### Storybook
|
||||
|
||||
Superset includes a [Storybook](https://storybook.js.org/) to preview the layout/styling of various Superset components, and variations thereof. To open and view the Storybook:
|
||||
|
||||
```bash
|
||||
cd superset-frontend
|
||||
npm run storybook
|
||||
```
|
||||
|
||||
When contributing new React components to Superset, please try to add a Story alongside the component's `jsx/tsx` file.
|
||||
|
||||
## Translating
|
||||
|
||||
We use [Flask-Babel](https://python-babel.github.io/flask-babel/) to translate Superset.
|
||||
In Python files, we import the magic `_` function using:
|
||||
|
||||
```python
|
||||
from flask_babel import lazy_gettext as _
|
||||
```
|
||||
|
||||
then wrap our translatable strings with it, e.g. `_('Translate me')`.
|
||||
During extraction, string literals passed to `_` will be added to the
|
||||
generated `.po` file for each language for later translation.
|
||||
|
||||
At runtime, the `_` function will return the translation of the given
|
||||
string for the current language, or the given string itself
|
||||
if no translation is available.
|
||||
|
||||
In TypeScript/JavaScript, the technique is similar:
|
||||
we import `t` (simple translation), `tn` (translation containing a number).
|
||||
|
||||
```javascript
|
||||
import { t, tn } from "@superset-ui/translation";
|
||||
```
|
||||
|
||||
### Enabling language selection
|
||||
|
||||
Add the `LANGUAGES` variable to your `superset_config.py`. Having more than one
|
||||
option inside will add a language selection dropdown to the UI on the right side
|
||||
of the navigation bar.
|
||||
|
||||
```python
|
||||
LANGUAGES = {
|
||||
'en': {'flag': 'us', 'name': 'English'},
|
||||
'fr': {'flag': 'fr', 'name': 'French'},
|
||||
'zh': {'flag': 'cn', 'name': 'Chinese'},
|
||||
}
|
||||
```
|
||||
|
||||
### Updating language files
|
||||
|
||||
```bash
|
||||
./scripts/babel_update.sh
|
||||
```
|
||||
|
||||
This script will
|
||||
|
||||
1. update the template file `superset/translations/messages.pot` with current application strings.
|
||||
2. update language files with the new extracted strings.
|
||||
|
||||
You can then translate the strings gathered in files located under
|
||||
`superset/translation`, where there's one per language. You can use [Poedit](https://poedit.net/features)
|
||||
to translate the `po` file more conveniently.
|
||||
There are some [tutorials in the wiki](https://wiki.lxde.org/en/Translate_*.po_files_with_Poedit).
|
||||
|
||||
In the case of JS translation, we need to convert the PO file into a JSON file, and we need the global download of the npm package po2json.
|
||||
|
||||
```bash
|
||||
npm install -g po2json
|
||||
```
|
||||
|
||||
To convert all PO files to formatted JSON files you can use the `po2json.sh` script.
|
||||
|
||||
```bash
|
||||
./scripts/po2json.sh
|
||||
```
|
||||
|
||||
If you get errors running `po2json`, you might be running the Ubuntu package with the same
|
||||
name, rather than the Node.js package (they have a different format for the arguments). If
|
||||
there is a conflict, you may need to update your `PATH` environment variable or fully qualify
|
||||
the executable path (e.g. `/usr/local/bin/po2json` instead of `po2json`).
|
||||
If you get a lot of `[null,***]` in `messages.json`, just delete all the `null,`.
|
||||
For example, `"year":["年"]` is correct while `"year":[null,"年"]`is incorrect.
|
||||
|
||||
For the translations to take effect we need to compile translation catalogs into binary MO files.
|
||||
|
||||
```bash
|
||||
pybabel compile -d superset/translations
|
||||
```
|
||||
|
||||
### Creating a new language dictionary
|
||||
|
||||
To create a dictionary for a new language, run the following, where `LANGUAGE_CODE` is replaced with
|
||||
the language code for your target language, e.g. `es` (see [Flask AppBuilder i18n documentation](https://flask-appbuilder.readthedocs.io/en/latest/i18n.html) for more details):
|
||||
|
||||
```bash
|
||||
pip install -r superset/translations/requirements.txt
|
||||
pybabel init -i superset/translations/messages.pot -d superset/translations -l LANGUAGE_CODE
|
||||
```
|
||||
|
||||
Then, [Updating language files](#updating-language-files).
|
||||
|
||||
## Tips
|
||||
|
||||
### Adding a new datasource
|
||||
|
||||
1. Create Models and Views for the datasource, add them under superset folder, like a new my_models.py
|
||||
with models for cluster, datasources, columns and metrics and my_views.py with clustermodelview
|
||||
and datasourcemodelview.
|
||||
|
||||
1. Create DB migration files for the new models
|
||||
|
||||
1. Specify this variable to add the datasource model and from which module it is from in config.py:
|
||||
|
||||
For example:
|
||||
|
||||
```python
|
||||
ADDITIONAL_MODULE_DS_MAP = {'superset.my_models': ['MyDatasource', 'MyOtherDatasource']}
|
||||
```
|
||||
|
||||
This means it'll register MyDatasource and MyOtherDatasource in superset.my_models module in the source registry.
|
||||
|
||||
### Visualization Plugins
|
||||
|
||||
The topic of authoring new plugins, whether you'd like to contribute
|
||||
it back or not has been well documented in the
|
||||
[the documentation](https://superset.apache.org/docs/contributing/creating-viz-plugins), and in [this blog post](https://preset.io/blog/building-custom-viz-plugins-in-superset-v2).
|
||||
|
||||
To contribute a plugin to Superset, your plugin must meet the following criteria:
|
||||
|
||||
- The plugin should be applicable to the community at large, not a particularly specialized use case
|
||||
- The plugin should be written with TypeScript
|
||||
- The plugin should contain sufficient unit/e2e tests
|
||||
- The plugin should use appropriate namespacing, e.g. a folder name of `plugin-chart-whatever` and a package name of `@superset-ui/plugin-chart-whatever`
|
||||
- The plugin should use them variables via Emotion, as passed in by the ThemeProvider
|
||||
- The plugin should provide adequate error handling (no data returned, malformed data, invalid controls, etc.)
|
||||
- The plugin should contain documentation in the form of a populated `README.md` file
|
||||
- The plugin should have a meaningful and unique icon
|
||||
- Above all else, the plugin should come with a _commitment to maintenance_ from the original author(s)
|
||||
|
||||
Submissions will be considered for submission (or removal) on a case-by-case basis.
|
||||
|
||||
### Adding a DB migration
|
||||
|
||||
1. Alter the model you want to change. This example will add a `Column` Annotations model.
|
||||
|
||||
[Example commit](https://github.com/apache/superset/commit/6c25f549384d7c2fc288451222e50493a7b14104)
|
||||
|
||||
1. Generate the migration file
|
||||
|
||||
```bash
|
||||
superset db migrate -m 'add_metadata_column_to_annotation_model'
|
||||
```
|
||||
|
||||
This will generate a file in `migrations/version/{SHA}_this_will_be_in_the_migration_filename.py`.
|
||||
|
||||
[Example commit](https://github.com/apache/superset/commit/d3e83b0fd572c9d6c1297543d415a332858e262)
|
||||
|
||||
1. Upgrade the DB
|
||||
|
||||
```bash
|
||||
superset db upgrade
|
||||
```
|
||||
|
||||
The output should look like this:
|
||||
|
||||
```
|
||||
INFO [alembic.runtime.migration] Context impl SQLiteImpl.
|
||||
INFO [alembic.runtime.migration] Will assume transactional DDL.
|
||||
INFO [alembic.runtime.migration] Running upgrade 1a1d627ebd8e -> 40a0a483dd12, add_metadata_column_to_annotation_model.py
|
||||
```
|
||||
|
||||
1. Add column to view
|
||||
|
||||
Since there is a new column, we need to add it to the AppBuilder Model view.
|
||||
|
||||
[Example commit](https://github.com/apache/superset/pull/5745/commits/6220966e2a0a0cf3e6d87925491f8920fe8a3458)
|
||||
|
||||
1. Test the migration's `down` method
|
||||
|
||||
```bash
|
||||
superset db downgrade
|
||||
```
|
||||
|
||||
The output should look like this:
|
||||
|
||||
```
|
||||
INFO [alembic.runtime.migration] Context impl SQLiteImpl.
|
||||
INFO [alembic.runtime.migration] Will assume transactional DDL.
|
||||
INFO [alembic.runtime.migration] Running downgrade 40a0a483dd12 -> 1a1d627ebd8e, add_metadata_column_to_annotation_model.py
|
||||
```
|
||||
|
||||
### Merging DB migrations
|
||||
|
||||
When two DB migrations collide, you'll get an error message like this one:
|
||||
|
||||
```text
|
||||
alembic.util.exc.CommandError: Multiple head revisions are present for
|
||||
given argument 'head'; please specify a specific target
|
||||
revision, '<branchname>@head' to narrow to a specific head,
|
||||
or 'heads' for all heads`
|
||||
```
|
||||
|
||||
To fix it:
|
||||
|
||||
1. Get the migration heads
|
||||
|
||||
```bash
|
||||
superset db heads
|
||||
```
|
||||
|
||||
This should list two or more migration hashes. E.g.
|
||||
|
||||
```bash
|
||||
1412ec1e5a7b (head)
|
||||
67da9ef1ef9c (head)
|
||||
```
|
||||
|
||||
2. Pick one of them as the parent revision, open the script for the other revision
|
||||
and update `Revises` and `down_revision` to the new parent revision. E.g.:
|
||||
|
||||
```diff
|
||||
--- a/67da9ef1ef9c_add_hide_left_bar_to_tabstate.py
|
||||
+++ b/67da9ef1ef9c_add_hide_left_bar_to_tabstate.py
|
||||
@@ -17,14 +17,14 @@
|
||||
"""add hide_left_bar to tabstate
|
||||
|
||||
Revision ID: 67da9ef1ef9c
|
||||
-Revises: c501b7c653a3
|
||||
+Revises: 1412ec1e5a7b
|
||||
Create Date: 2021-02-22 11:22:10.156942
|
||||
|
||||
"""
|
||||
|
||||
# revision identifiers, used by Alembic.
|
||||
revision = "67da9ef1ef9c"
|
||||
-down_revision = "c501b7c653a3"
|
||||
+down_revision = "1412ec1e5a7b"
|
||||
|
||||
import sqlalchemy as sa
|
||||
from alembic import op
|
||||
```
|
||||
|
||||
Alternatively you may also run `superset db merge` to create a migration script
|
||||
just for merging the heads.
|
||||
|
||||
```bash
|
||||
superset db merge {HASH1} {HASH2}
|
||||
```
|
||||
|
||||
3. Upgrade the DB to the new checkpoint
|
||||
|
||||
```bash
|
||||
superset db upgrade
|
||||
```
|
||||
|
|
@ -0,0 +1,258 @@
|
|||
---
|
||||
title: Guidelines
|
||||
sidebar_position: 2
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Pull Request Guidelines
|
||||
|
||||
A philosophy we would like to strongly encourage is
|
||||
|
||||
> Before creating a PR, create an issue.
|
||||
|
||||
The purpose is to separate problem from possible solutions.
|
||||
|
||||
**Bug fixes:** If you’re only fixing a small bug, it’s fine to submit a pull request right away but we highly recommend to file an issue detailing what you’re fixing. This is helpful in case we don’t accept that specific fix but want to keep track of the issue. Please keep in mind that the project maintainers reserve the rights to accept or reject incoming PRs, so it is better to separate the issue and the code to fix it from each other. In some cases, project maintainers may request you to create a separate issue from PR before proceeding.
|
||||
|
||||
**Refactor:** For small refactors, it can be a standalone PR itself detailing what you are refactoring and why. If there are concerns, project maintainers may request you to create a `#SIP` for the PR before proceeding.
|
||||
|
||||
**Feature/Large changes:** If you intend to change the public API, or make any non-trivial changes to the implementation, we require you to file a new issue as `#SIP` (Superset Improvement Proposal). This lets us reach an agreement on your proposal before you put significant effort into it. You are welcome to submit a PR along with the SIP (sometimes necessary for demonstration), but we will not review/merge the code until the SIP is approved.
|
||||
|
||||
In general, small PRs are always easier to review than large PRs. The best practice is to break your work into smaller independent PRs and refer to the same issue. This will greatly reduce turnaround time.
|
||||
|
||||
If you wish to share your work which is not ready to merge yet, create a [Draft PR](https://github.blog/2019-02-14-introducing-draft-pull-requests/). This will enable maintainers and the CI runner to prioritize mature PR's.
|
||||
|
||||
Finally, never submit a PR that will put master branch in broken state. If the PR is part of multiple PRs to complete a large feature and cannot work on its own, you can create a feature branch and merge all related PRs into the feature branch before creating a PR from feature branch to master.
|
||||
|
||||
### Protocol
|
||||
|
||||
#### Authoring
|
||||
|
||||
- Fill in all sections of the PR template.
|
||||
- Title the PR with one of the following semantic prefixes (inspired by [Karma](http://karma-runner.github.io/0.10/dev/git-commit-msg.html])):
|
||||
|
||||
- `feat` (new feature)
|
||||
- `fix` (bug fix)
|
||||
- `docs` (changes to the documentation)
|
||||
- `style` (formatting, missing semi colons, etc; no application logic change)
|
||||
- `refactor` (refactoring code)
|
||||
- `test` (adding missing tests, refactoring tests; no application logic change)
|
||||
- `chore` (updating tasks etc; no application logic change)
|
||||
- `perf` (performance-related change)
|
||||
- `build` (build tooling, Docker configuration change)
|
||||
- `ci` (test runner, GitHub Actions workflow changes)
|
||||
- `other` (changes that don't correspond to the above -- should be rare!)
|
||||
- Examples:
|
||||
- `feat: export charts as ZIP files`
|
||||
- `perf(api): improve API info performance`
|
||||
- `fix(chart-api): cached-indicator always shows value is cached`
|
||||
|
||||
- Add prefix `[WIP]` to title if not ready for review (WIP = work-in-progress). We recommend creating a PR with `[WIP]` first and remove it once you have passed CI test and read through your code changes at least once.
|
||||
- If you believe your PR contributes a potentially breaking change, put a `!` after the semantic prefix but before the colon in the PR title, like so: `feat!: Added foo functionality to bar`
|
||||
- **Screenshots/GIFs:** Changes to user interface require before/after screenshots, or GIF for interactions
|
||||
- Recommended capture tools ([Kap](https://getkap.co/), [LICEcap](https://www.cockos.com/licecap/), [Skitch](https://download.cnet.com/Skitch/3000-13455_4-189876.html))
|
||||
- If no screenshot is provided, the committers will mark the PR with `need:screenshot` label and will not review until screenshot is provided.
|
||||
- **Dependencies:** Be careful about adding new dependency and avoid unnecessary dependencies.
|
||||
- For Python, include it in `pyproject.toml` denoting any specific restrictions and
|
||||
in `requirements.txt` pinned to a specific version which ensures that the application
|
||||
build is deterministic.
|
||||
- For TypeScript/JavaScript, include new libraries in `package.json`
|
||||
- **Tests:** The pull request should include tests, either as doctests, unit tests, or both. Make sure to resolve all errors and test failures. See [Testing](#testing) for how to run tests.
|
||||
- **Documentation:** If the pull request adds functionality, the docs should be updated as part of the same PR.
|
||||
- **CI:** Reviewers will not review the code until all CI tests are passed. Sometimes there can be flaky tests. You can close and open PR to re-run CI test. Please report if the issue persists. After the CI fix has been deployed to `master`, please rebase your PR.
|
||||
- **Code coverage:** Please ensure that code coverage does not decrease.
|
||||
- Remove `[WIP]` when ready for review. Please note that it may be merged soon after approved so please make sure the PR is ready to merge and do not expect more time for post-approval edits.
|
||||
- If the PR was not ready for review and inactive for > 30 days, we will close it due to inactivity. The author is welcome to re-open and update.
|
||||
|
||||
#### Reviewing
|
||||
|
||||
- Use constructive tone when writing reviews.
|
||||
- If there are changes required, state clearly what needs to be done before the PR can be approved.
|
||||
- If you are asked to update your pull request with some changes there's no need to create a new one. Push your changes to the same branch.
|
||||
- The committers reserve the right to reject any PR and in some cases may request the author to file an issue.
|
||||
|
||||
#### Test Environments
|
||||
|
||||
- Members of the Apache GitHub org can launch an ephemeral test environment directly on a pull request by creating a comment containing (only) the command `/testenv up`.
|
||||
- Note that org membership must be public in order for this validation to function properly.
|
||||
- Feature flags may be set for a test environment by specifying the flag name (prefixed with `FEATURE_`) and value after the command.
|
||||
- Format: `/testenv up FEATURE_<feature flag name>=true|false`
|
||||
- Example: `/testenv up FEATURE_DASHBOARD_NATIVE_FILTERS=true`
|
||||
- Multiple feature flags may be set in single command, separated by whitespace
|
||||
- A comment will be created by the workflow script with the address and login information for the ephemeral environment.
|
||||
- Test environments may be created once the Docker build CI workflow for the PR has completed successfully.
|
||||
- Test environments do not currently update automatically when new commits are added to a pull request.
|
||||
- Test environments do not currently support async workers, though this is planned.
|
||||
- Running test environments will be shutdown upon closing the pull request.
|
||||
|
||||
#### Merging
|
||||
|
||||
- At least one approval is required for merging a PR.
|
||||
- PR is usually left open for at least 24 hours before merging.
|
||||
- After the PR is merged, [close the corresponding issue(s)](https://help.github.com/articles/closing-issues-using-keywords/).
|
||||
|
||||
#### Post-merge Responsibility
|
||||
|
||||
- Project maintainers may contact the PR author if new issues are introduced by the PR.
|
||||
- Project maintainers may revert your changes if a critical issue is found, such as breaking master branch CI.
|
||||
|
||||
|
||||
## Managing Issues and PRs
|
||||
|
||||
To handle issues and PRs that are coming in, committers read issues/PRs and flag them with labels to categorize and help contributors spot where to take actions, as contributors usually have different expertises.
|
||||
|
||||
Triaging goals
|
||||
|
||||
- **For issues:** Categorize, screen issues, flag required actions from authors.
|
||||
- **For PRs:** Categorize, flag required actions from authors. If PR is ready for review, flag required actions from reviewers.
|
||||
|
||||
First, add **Category labels (a.k.a. hash labels)**. Every issue/PR must have one hash label (except spam entry). Labels that begin with `#` defines issue/PR type:
|
||||
|
||||
| Label | for Issue | for PR |
|
||||
| --------------- | ----------------------------------------------------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------------------------------------------------------------- |
|
||||
| `#bug` | Bug report | Bug fix |
|
||||
| `#code-quality` | Describe problem with code, architecture or productivity | Refactor, tests, tooling |
|
||||
| `#feature` | New feature request | New feature implementation |
|
||||
| `#refine` | Propose improvement such as adjusting padding or refining UI style, excluding new features, bug fixes, and refactoring. | Implementation of improvement such as adjusting padding or refining UI style, excluding new features, bug fixes, and refactoring. |
|
||||
| `#doc` | Documentation | Documentation |
|
||||
| `#question` | Troubleshooting: Installation, Running locally, Ask how to do something. Can be changed to `#bug` later. | N/A |
|
||||
| `#SIP` | Superset Improvement Proposal | N/A |
|
||||
| `#ASF` | Tasks related to Apache Software Foundation policy | Tasks related to Apache Software Foundation policy |
|
||||
|
||||
Then add other types of labels as appropriate.
|
||||
|
||||
- **Descriptive labels (a.k.a. dot labels):** These labels that begin with `.` describe the details of the issue/PR, such as `.ui`, `.js`, `.install`, `.backend`, etc. Each issue/PR can have zero or more dot labels.
|
||||
- **Need labels:** These labels have pattern `need:xxx`, which describe the work required to progress, such as `need:rebase`, `need:update`, `need:screenshot`.
|
||||
- **Risk labels:** These labels have pattern `risk:xxx`, which describe the potential risk on adopting the work, such as `risk:db-migration`. The intention was to better understand the impact and create awareness for PRs that need more rigorous testing.
|
||||
- **Status labels:** These labels describe the status (`abandoned`, `wontfix`, `cant-reproduce`, etc.) Issue/PRs that are rejected or closed without completion should have one or more status labels.
|
||||
- **Version labels:** These have the pattern `vx.x` such as `v0.28`. Version labels on issues describe the version the bug was reported on. Version labels on PR describe the first release that will include the PR.
|
||||
|
||||
Committers may also update title to reflect the issue/PR content if the author-provided title is not descriptive enough.
|
||||
|
||||
If the PR passes CI tests and does not have any `need:` labels, it is ready for review, add label `review` and/or `design-review`.
|
||||
|
||||
If an issue/PR has been inactive for >=30 days, it will be closed. If it does not have any status label, add `inactive`.
|
||||
|
||||
When creating a PR, if you're aiming to have it included in a specific release, please tag it with the version label. For example, to have a PR considered for inclusion in Superset 1.1 use the label `v1.1`.
|
||||
|
||||
## Revert Guidelines
|
||||
|
||||
Reverting changes that are causing issues in the master branch is a normal and expected part of the development process. In an open source community, the ramifications of a change cannot always be fully understood. With that in mind, here are some considerations to keep in mind when considering a revert:
|
||||
|
||||
- **Availability of the PR author:** If the original PR author or the engineer who merged the code is highly available and can provide a fix in a reasonable time frame, this would counter-indicate reverting.
|
||||
- **Severity of the issue:** How severe is the problem on master? Is it keeping the project from moving forward? Is there user impact? What percentage of users will experience a problem?
|
||||
- **Size of the change being reverted:** Reverting a single small PR is a much lower-risk proposition than reverting a massive, multi-PR change.
|
||||
- **Age of the change being reverted:** Reverting a recently-merged PR will be more acceptable than reverting an older PR. A bug discovered in an older PR is unlikely to be causing widespread serious issues.
|
||||
- **Risk inherent in reverting:** Will the reversion break critical functionality? Is the medicine more dangerous than the disease?
|
||||
- **Difficulty of crafting a fix:** In the case of issues with a clear solution, it may be preferable to implement and merge a fix rather than a revert.
|
||||
|
||||
Should you decide that reverting is desirable, it is the responsibility of the Contributor performing the revert to:
|
||||
|
||||
- **Contact the interested parties:** The PR's author and the engineer who merged the work should both be contacted and informed of the revert.
|
||||
- **Provide concise reproduction steps:** Ensure that the issue can be clearly understood and duplicated by the original author of the PR.
|
||||
- **Put the revert through code review:** The revert must be approved by another committer.
|
||||
|
||||
|
||||
|
||||
|
||||
## Design Guidelines
|
||||
### Capitalization guidelines
|
||||
|
||||
#### Sentence case
|
||||
|
||||
Use sentence-case capitalization for everything in the UI (except these \*\*).
|
||||
|
||||
Sentence case is predominantly lowercase. Capitalize only the initial character of the first word, and other words that require capitalization, like:
|
||||
|
||||
- **Proper nouns.** Objects in the product _are not_ considered proper nouns e.g. dashboards, charts, saved queries etc. Proprietary feature names eg. SQL Lab, Preset Manager _are_ considered proper nouns
|
||||
- **Acronyms** (e.g. CSS, HTML)
|
||||
- When referring to **UI labels that are themselves capitalized** from sentence case (e.g. page titles - Dashboards page, Charts page, Saved queries page, etc.)
|
||||
- User input that is reflected in the UI. E.g. a user-named a dashboard tab
|
||||
|
||||
**Sentence case vs. Title case:**
|
||||
Title case: "A Dog Takes a Walk in Paris"
|
||||
Sentence case: "A dog takes a walk in Paris"
|
||||
|
||||
**Why sentence case?**
|
||||
|
||||
- It’s generally accepted as the quickest to read
|
||||
- It’s the easiest form to distinguish between common and proper nouns
|
||||
|
||||
#### How to refer to UI elements
|
||||
|
||||
When writing about a UI element, use the same capitalization as used in the UI.
|
||||
|
||||
For example, if an input field is labeled “Name” then you refer to this as the “Name input field”. Similarly, if a button has the label “Save” in it, then it is correct to refer to the “Save button”.
|
||||
|
||||
Where a product page is titled “Settings”, you refer to this in writing as follows:
|
||||
“Edit your personal information on the Settings page”.
|
||||
|
||||
Often a product page will have the same title as the objects it contains. In this case, refer to the page as it appears in the UI, and the objects as common nouns:
|
||||
|
||||
- Upload a dashboard on the Dashboards page
|
||||
- Go to Dashboards
|
||||
- View dashboard
|
||||
- View all dashboards
|
||||
- Upload CSS templates on the CSS templates page
|
||||
- Queries that you save will appear on the Saved queries page
|
||||
- Create custom queries in SQL Lab then create dashboards
|
||||
|
||||
#### \*\*Exceptions to sentence case:
|
||||
|
||||
- Input labels, buttons and UI tabs are all caps
|
||||
- User input values (e.g. column names, SQL Lab tab names) should be in their original case
|
||||
|
||||
|
||||
## Programming Language Conventions
|
||||
|
||||
### Python
|
||||
|
||||
Parameters in the `config.py` (which are accessible via the Flask app.config dictionary) are
|
||||
assumed to always be defined and thus should be accessed directly via,
|
||||
|
||||
```python
|
||||
blueprints = app.config["BLUEPRINTS"]
|
||||
```
|
||||
|
||||
rather than,
|
||||
|
||||
```python
|
||||
blueprints = app.config.get("BLUEPRINTS")
|
||||
```
|
||||
|
||||
or similar as the later will cause typing issues. The former is of type `List[Callable]`
|
||||
whereas the later is of type `Optional[List[Callable]]`.
|
||||
|
||||
#### Typing / Types Hints
|
||||
|
||||
To ensure clarity, consistency, all readability, _all_ new functions should use
|
||||
[type hints](https://docs.python.org/3/library/typing.html) and include a
|
||||
docstring.
|
||||
|
||||
Note per [PEP-484](https://www.python.org/dev/peps/pep-0484/#exceptions) no
|
||||
syntax for listing explicitly raised exceptions is proposed and thus the
|
||||
recommendation is to put this information in a docstring, i.e.,
|
||||
|
||||
```python
|
||||
import math
|
||||
from typing import Union
|
||||
|
||||
|
||||
def sqrt(x: Union[float, int]) -> Union[float, int]:
|
||||
"""
|
||||
Return the square root of x.
|
||||
|
||||
:param x: A number
|
||||
:returns: The square root of the given number
|
||||
:raises ValueError: If the number is negative
|
||||
"""
|
||||
|
||||
return math.sqrt(x)
|
||||
```
|
||||
|
||||
### TypeScript
|
||||
|
||||
TypeScript is fully supported and is the recommended language for writing all new frontend
|
||||
components. When modifying existing functions/components, migrating to TypeScript is
|
||||
appreciated, but not required. Examples of migrating functions/components to TypeScript can be
|
||||
found in [#9162](https://github.com/apache/superset/pull/9162) and [#9180](https://github.com/apache/superset/pull/9180).
|
||||
|
|
@ -1,64 +0,0 @@
|
|||
---
|
||||
title: Pre-commit Hooks and Linting
|
||||
hide_title: true
|
||||
sidebar_position: 6
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Git Hooks
|
||||
|
||||
Superset uses Git pre-commit hooks courtesy of [pre-commit](https://pre-commit.com/). To install run the following:
|
||||
|
||||
```bash
|
||||
pip3 install -r requirements/development.txt
|
||||
pre-commit install
|
||||
```
|
||||
|
||||
A series of checks will now run when you make a git commit.
|
||||
|
||||
Alternatively it is possible to run pre-commit via tox:
|
||||
|
||||
```bash
|
||||
tox -e pre-commit
|
||||
```
|
||||
|
||||
Or by running pre-commit manually:
|
||||
|
||||
```bash
|
||||
pre-commit run --all-files
|
||||
```
|
||||
|
||||
## Linting
|
||||
|
||||
### Python
|
||||
|
||||
We use [Pylint](https://pylint.org/) for linting which can be invoked via:
|
||||
|
||||
```bash
|
||||
# for python
|
||||
tox -e pylint
|
||||
```
|
||||
|
||||
In terms of best practices please avoid blanket disabling of Pylint messages globally (via `.pylintrc`) or top-level within the file header, albeit there being a few exceptions. Disabling should occur inline as it prevents masking issues and provides context as to why said message is disabled.
|
||||
|
||||
Additionally, the Python code is auto-formatted using [Black](https://github.com/python/black) which
|
||||
is configured as a pre-commit hook. There are also numerous [editor integrations](https://black.readthedocs.io/en/stable/integrations/editors.html)
|
||||
|
||||
### TypeScript
|
||||
|
||||
```bash
|
||||
cd superset-frontend
|
||||
npm ci
|
||||
# run eslint checks
|
||||
npm run eslint -- .
|
||||
# run tsc (typescript) checks
|
||||
npm run type
|
||||
```
|
||||
|
||||
If using the eslint extension with vscode, put the following in your workspace `settings.json` file:
|
||||
|
||||
```json
|
||||
"eslint.workingDirectories": [
|
||||
"superset-frontend"
|
||||
]
|
||||
```
|
||||
|
|
@ -0,0 +1,637 @@
|
|||
---
|
||||
title: Development How-tos
|
||||
hide_title: true
|
||||
sidebar_position: 4
|
||||
version: 1
|
||||
---
|
||||
# Development How-tos
|
||||
|
||||
## Contributing to Documentation
|
||||
|
||||
The latest documentation and tutorial are available at https://superset.apache.org/.
|
||||
|
||||
The documentation site is built using [Docusaurus 2](https://docusaurus.io/), a modern
|
||||
static website generator, the source for which resides in `./docs`.
|
||||
|
||||
### Local Development
|
||||
|
||||
To set up a local development environment with hot reloading for the documentation site:
|
||||
|
||||
```shell
|
||||
cd docs
|
||||
yarn install # Installs NPM dependencies
|
||||
yarn start # Starts development server at http://localhost:3000
|
||||
```
|
||||
|
||||
### Build
|
||||
|
||||
To create and serve a production build of the documentation site:
|
||||
|
||||
```shell
|
||||
yarn build
|
||||
yarn serve
|
||||
```
|
||||
|
||||
### Deployment
|
||||
|
||||
Commits to `master` trigger a rebuild and redeploy of the documentation site. Submit pull requests that modify the documentation with the `docs:` prefix.
|
||||
|
||||
## Creating Visualization Plugins
|
||||
|
||||
Visualizations in Superset are implemented in JavaScript or TypeScript. Superset
|
||||
comes preinstalled with several visualizations types (hereafter "viz plugins") that
|
||||
can be found under the `superset-frontend/plugins` directory. Viz plugins are added to
|
||||
the application in the `superset-frontend/src/visualizations/presets/MainPreset.js`.
|
||||
The Superset project is always happy to review proposals for new high quality viz
|
||||
plugins. However, for highly custom viz types it is recommended to maintain a fork
|
||||
of Superset, and add the custom built viz plugins by hand.
|
||||
|
||||
**Note:** Additional community-generated resources about creating and deploying custom visualization plugins can be found on the [Superset Wiki](https://github.com/apache/superset/wiki/Community-Resource-Library#creating-custom-data-visualizations)
|
||||
|
||||
### Prerequisites
|
||||
|
||||
In order to create a new viz plugin, you need the following:
|
||||
|
||||
- Run MacOS or Linux (Windows is not officially supported, but may work)
|
||||
- Node.js 16
|
||||
- npm 7 or 8
|
||||
|
||||
A general familiarity with [React](https://reactjs.org/) and the npm/Node system is
|
||||
also recommended.
|
||||
|
||||
### Creating a simple Hello World viz plugin
|
||||
|
||||
To get started, you need the Superset Yeoman Generator. It is recommended to use the
|
||||
version of the template that ships with the version of Superset you are using. This
|
||||
can be installed by doing the following:
|
||||
|
||||
```bash
|
||||
npm i -g yo
|
||||
cd superset-frontend/packages/generator-superset
|
||||
npm i
|
||||
npm link
|
||||
```
|
||||
|
||||
After this you can proceed to create your viz plugin. Create a new directory for your
|
||||
viz plugin with the prefix `superset-plugin-chart` and run the Yeoman generator:
|
||||
|
||||
```bash
|
||||
mkdir /tmp/superset-plugin-chart-hello-world
|
||||
cd /tmp/superset-plugin-chart-hello-world
|
||||
```
|
||||
|
||||
Initialize the viz plugin:
|
||||
|
||||
```bash
|
||||
yo @superset-ui/superset
|
||||
```
|
||||
|
||||
After that the generator will ask a few questions (the defaults should be fine):
|
||||
|
||||
```
|
||||
$ yo @superset-ui/superset
|
||||
_-----_ ╭──────────────────────────╮
|
||||
| | │ Welcome to the │
|
||||
|--(o)--| │ generator-superset │
|
||||
`---------´ │ generator! │
|
||||
( _´U`_ ) ╰──────────────────────────╯
|
||||
/___A___\ /
|
||||
| ~ |
|
||||
__'.___.'__
|
||||
´ ` |° ´ Y `
|
||||
? Package name: superset-plugin-chart-hello-world
|
||||
? Description: Hello World
|
||||
? What type of chart would you like? Time-series chart
|
||||
create package.json
|
||||
create .gitignore
|
||||
create babel.config.js
|
||||
create jest.config.js
|
||||
create README.md
|
||||
create tsconfig.json
|
||||
create src/index.ts
|
||||
create src/plugin/buildQuery.ts
|
||||
create src/plugin/controlPanel.ts
|
||||
create src/plugin/index.ts
|
||||
create src/plugin/transformProps.ts
|
||||
create src/types.ts
|
||||
create src/SupersetPluginChartHelloWorld.tsx
|
||||
create test/index.test.ts
|
||||
create test/__mocks__/mockExportString.js
|
||||
create test/plugin/buildQuery.test.ts
|
||||
create test/plugin/transformProps.test.ts
|
||||
create types/external.d.ts
|
||||
create src/images/thumbnail.png
|
||||
```
|
||||
|
||||
To build the viz plugin, run the following commands:
|
||||
|
||||
```
|
||||
npm i --force
|
||||
npm run build
|
||||
```
|
||||
|
||||
Alternatively, to run the viz plugin in development mode (=rebuilding whenever changes
|
||||
are made), start the dev server with the following command:
|
||||
|
||||
```
|
||||
npm run dev
|
||||
```
|
||||
|
||||
To add the package to Superset, go to the `superset-frontend` subdirectory in your
|
||||
Superset source folder run
|
||||
|
||||
```bash
|
||||
npm i -S /tmp/superset-plugin-chart-hello-world
|
||||
```
|
||||
|
||||
If you publish your package to npm, you can naturally install directly from there, too.
|
||||
After this edit the `superset-frontend/src/visualizations/presets/MainPreset.js`
|
||||
and make the following changes:
|
||||
|
||||
```js
|
||||
import { SupersetPluginChartHelloWorld } from 'superset-plugin-chart-hello-world';
|
||||
```
|
||||
|
||||
to import the viz plugin and later add the following to the array that's passed to the
|
||||
`plugins` property:
|
||||
|
||||
```js
|
||||
new SupersetPluginChartHelloWorld().configure({ key: 'ext-hello-world' }),
|
||||
```
|
||||
|
||||
After that the viz plugin should show up when you run Superset, e.g. the development
|
||||
server:
|
||||
|
||||
```bash
|
||||
npm run dev-server
|
||||
```
|
||||
|
||||
## Testing
|
||||
|
||||
### Python Testing
|
||||
|
||||
All python tests are carried out in [tox](https://tox.readthedocs.io/en/latest/index.html)
|
||||
a standardized testing framework.
|
||||
All python tests can be run with any of the tox [environments](https://tox.readthedocs.io/en/latest/example/basic.html#a-simple-tox-ini-default-environments), via,
|
||||
|
||||
```bash
|
||||
tox -e <environment>
|
||||
```
|
||||
|
||||
For example,
|
||||
|
||||
```bash
|
||||
tox -e py38
|
||||
```
|
||||
|
||||
Alternatively, you can run all tests in a single file via,
|
||||
|
||||
```bash
|
||||
tox -e <environment> -- tests/test_file.py
|
||||
```
|
||||
|
||||
or for a specific test via,
|
||||
|
||||
```bash
|
||||
tox -e <environment> -- tests/test_file.py::TestClassName::test_method_name
|
||||
```
|
||||
|
||||
Note that the test environment uses a temporary directory for defining the
|
||||
SQLite databases which will be cleared each time before the group of test
|
||||
commands are invoked.
|
||||
|
||||
There is also a utility script included in the Superset codebase to run python integration tests. The [readme can be
|
||||
found here](https://github.com/apache/superset/tree/master/scripts/tests)
|
||||
|
||||
To run all integration tests for example, run this script from the root directory:
|
||||
|
||||
```bash
|
||||
scripts/tests/run.sh
|
||||
```
|
||||
|
||||
You can run unit tests found in './tests/unit_tests' for example with pytest. It is a simple way to run an isolated test that doesn't need any database setup
|
||||
|
||||
```bash
|
||||
pytest ./link_to_test.py
|
||||
```
|
||||
|
||||
#### Testing with local Presto connections
|
||||
|
||||
If you happen to change db engine spec for Presto/Trino, you can run a local Presto cluster with Docker:
|
||||
|
||||
```bash
|
||||
docker run -p 15433:15433 starburstdata/presto:350-e.6
|
||||
```
|
||||
|
||||
Then update `SUPERSET__SQLALCHEMY_EXAMPLES_URI` to point to local Presto cluster:
|
||||
|
||||
```bash
|
||||
export SUPERSET__SQLALCHEMY_EXAMPLES_URI=presto://localhost:15433/memory/default
|
||||
```
|
||||
|
||||
### Frontend Testing
|
||||
|
||||
We use [Jest](https://jestjs.io/) and [Enzyme](https://airbnb.io/enzyme/) to test TypeScript/JavaScript. Tests can be run with:
|
||||
|
||||
```bash
|
||||
cd superset-frontend
|
||||
npm run test
|
||||
```
|
||||
|
||||
To run a single test file:
|
||||
|
||||
```bash
|
||||
npm run test -- path/to/file.js
|
||||
```
|
||||
|
||||
### e2e Integration Testing
|
||||
|
||||
We use [Cypress](https://www.cypress.io/) for end-to-end integration
|
||||
tests. One easy option to get started quickly is to leverage `tox` to
|
||||
run the whole suite in an isolated environment.
|
||||
|
||||
```bash
|
||||
tox -e cypress
|
||||
```
|
||||
|
||||
Alternatively, you can go lower level and set things up in your
|
||||
development environment by following these steps:
|
||||
|
||||
First set up a python/flask backend:
|
||||
|
||||
```bash
|
||||
export SUPERSET_CONFIG=tests.integration_tests.superset_test_config
|
||||
export SUPERSET_TESTENV=true
|
||||
export CYPRESS_BASE_URL="http://localhost:8081"
|
||||
superset db upgrade
|
||||
superset load_test_users
|
||||
superset init
|
||||
superset load-examples --load-test-data
|
||||
superset run --port 8081
|
||||
```
|
||||
|
||||
In another terminal, prepare the frontend and run Cypress tests:
|
||||
|
||||
```bash
|
||||
cd superset-frontend
|
||||
npm run build-instrumented
|
||||
|
||||
cd cypress-base
|
||||
npm install
|
||||
|
||||
# run tests via headless Chrome browser (requires Chrome 64+)
|
||||
npm run cypress-run-chrome
|
||||
|
||||
# run tests from a specific file
|
||||
npm run cypress-run-chrome -- --spec cypress/e2e/explore/link.test.ts
|
||||
|
||||
# run specific file with video capture
|
||||
npm run cypress-run-chrome -- --spec cypress/e2e/dashboard/index.test.js --config video=true
|
||||
|
||||
# to open the cypress ui
|
||||
npm run cypress-debug
|
||||
|
||||
# to point cypress to a url other than the default (http://localhost:8088) set the environment variable before running the script
|
||||
# e.g., CYPRESS_BASE_URL="http://localhost:9000"
|
||||
CYPRESS_BASE_URL=<your url> npm run cypress open
|
||||
```
|
||||
|
||||
See [`superset-frontend/cypress_build.sh`](https://github.com/apache/superset/blob/master/superset-frontend/cypress_build.sh).
|
||||
|
||||
As an alternative you can use docker compose environment for testing:
|
||||
|
||||
Make sure you have added below line to your /etc/hosts file:
|
||||
`127.0.0.1 db`
|
||||
|
||||
If you already have launched Docker environment please use the following command to assure a fresh database instance:
|
||||
`docker compose down -v`
|
||||
|
||||
Launch environment:
|
||||
|
||||
`CYPRESS_CONFIG=true docker compose up`
|
||||
|
||||
It will serve backend and frontend on port 8088.
|
||||
|
||||
Run Cypress tests:
|
||||
|
||||
```bash
|
||||
cd cypress-base
|
||||
npm install
|
||||
npm run cypress open
|
||||
```
|
||||
|
||||
### Debugging Server App
|
||||
|
||||
Follow these instructions to debug the Flask app running inside a docker container.
|
||||
|
||||
First add the following to the ./docker-compose.yaml file
|
||||
|
||||
```diff
|
||||
superset:
|
||||
env_file: docker/.env
|
||||
image: *superset-image
|
||||
container_name: superset_app
|
||||
command: ["/app/docker/docker-bootstrap.sh", "app"]
|
||||
restart: unless-stopped
|
||||
+ cap_add:
|
||||
+ - SYS_PTRACE
|
||||
ports:
|
||||
- 8088:8088
|
||||
+ - 5678:5678
|
||||
user: "root"
|
||||
depends_on: *superset-depends-on
|
||||
volumes: *superset-volumes
|
||||
environment:
|
||||
CYPRESS_CONFIG: "${CYPRESS_CONFIG}"
|
||||
```
|
||||
|
||||
Start Superset as usual
|
||||
|
||||
```bash
|
||||
docker compose up
|
||||
```
|
||||
|
||||
Install the required libraries and packages to the docker container
|
||||
|
||||
Enter the superset_app container
|
||||
|
||||
```bash
|
||||
docker exec -it superset_app /bin/bash
|
||||
root@39ce8cf9d6ab:/app#
|
||||
```
|
||||
|
||||
Run the following commands inside the container
|
||||
|
||||
```bash
|
||||
apt update
|
||||
apt install -y gdb
|
||||
apt install -y net-tools
|
||||
pip install debugpy
|
||||
```
|
||||
|
||||
Find the PID for the Flask process. Make sure to use the first PID. The Flask app will re-spawn a sub-process every time you change any of the python code. So it's important to use the first PID.
|
||||
|
||||
```bash
|
||||
ps -ef
|
||||
|
||||
UID PID PPID C STIME TTY TIME CMD
|
||||
root 1 0 0 14:09 ? 00:00:00 bash /app/docker/docker-bootstrap.sh app
|
||||
root 6 1 4 14:09 ? 00:00:04 /usr/local/bin/python /usr/bin/flask run -p 8088 --with-threads --reload --debugger --host=0.0.0.0
|
||||
root 10 6 7 14:09 ? 00:00:07 /usr/local/bin/python /usr/bin/flask run -p 8088 --with-threads --reload --debugger --host=0.0.0.0
|
||||
```
|
||||
|
||||
Inject debugpy into the running Flask process. In this case PID 6.
|
||||
|
||||
```bash
|
||||
python3 -m debugpy --listen 0.0.0.0:5678 --pid 6
|
||||
```
|
||||
|
||||
Verify that debugpy is listening on port 5678
|
||||
|
||||
```bash
|
||||
netstat -tunap
|
||||
|
||||
Active Internet connections (servers and established)
|
||||
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
|
||||
tcp 0 0 0.0.0.0:5678 0.0.0.0:* LISTEN 462/python
|
||||
tcp 0 0 0.0.0.0:8088 0.0.0.0:* LISTEN 6/python
|
||||
```
|
||||
|
||||
You are now ready to attach a debugger to the process. Using VSCode you can configure a launch configuration file .vscode/launch.json like so.
|
||||
|
||||
```
|
||||
{
|
||||
"version": "0.2.0",
|
||||
"configurations": [
|
||||
{
|
||||
"name": "Attach to Superset App in Docker Container",
|
||||
"type": "python",
|
||||
"request": "attach",
|
||||
"connect": {
|
||||
"host": "127.0.0.1",
|
||||
"port": 5678
|
||||
},
|
||||
"pathMappings": [
|
||||
{
|
||||
"localRoot": "${workspaceFolder}",
|
||||
"remoteRoot": "/app"
|
||||
}
|
||||
]
|
||||
},
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
VSCode will not stop on breakpoints right away. We've attached to PID 6 however it does not yet know of any sub-processes. In order to "wakeup" the debugger you need to modify a python file. This will trigger Flask to reload the code and create a new sub-process. This new sub-process will be detected by VSCode and breakpoints will be activated.
|
||||
|
||||
### Debugging Server App in Kubernetes Environment
|
||||
|
||||
To debug Flask running in POD inside kubernetes cluster. You'll need to make sure the pod runs as root and is granted the SYS_TRACE capability.These settings should not be used in production environments.
|
||||
|
||||
```
|
||||
securityContext:
|
||||
capabilities:
|
||||
add: ["SYS_PTRACE"]
|
||||
```
|
||||
|
||||
See (set capabilities for a container)[https://kubernetes.io/docs/tasks/configure-pod-container/security-context/#set-capabilities-for-a-container] for more details.
|
||||
|
||||
Once the pod is running as root and has the SYS_PTRACE capability it will be able to debug the Flask app.
|
||||
|
||||
You can follow the same instructions as in the docker-compose. Enter the pod and install the required library and packages; gdb, netstat and debugpy.
|
||||
|
||||
Often in a Kubernetes environment nodes are not addressable from outside the cluster. VSCode will thus be unable to remotely connect to port 5678 on a Kubernetes node. In order to do this you need to create a tunnel that port forwards 5678 to your local machine.
|
||||
|
||||
```
|
||||
kubectl port-forward pod/superset-<some random id> 5678:5678
|
||||
```
|
||||
|
||||
You can now launch your VSCode debugger with the same config as above. VSCode will connect to to 127.0.0.1:5678 which is forwarded by kubectl to your remote kubernetes POD.
|
||||
|
||||
### Storybook
|
||||
|
||||
Superset includes a [Storybook](https://storybook.js.org/) to preview the layout/styling of various Superset components, and variations thereof. To open and view the Storybook:
|
||||
|
||||
```bash
|
||||
cd superset-frontend
|
||||
npm run storybook
|
||||
```
|
||||
|
||||
When contributing new React components to Superset, please try to add a Story alongside the component's `jsx/tsx` file.
|
||||
|
||||
## Contribute Translations
|
||||
|
||||
We use [Flask-Babel](https://python-babel.github.io/flask-babel/) to translate Superset.
|
||||
In Python files, we use the following
|
||||
[translation functions](https://python-babel.github.io/flask-babel/#using-translations)
|
||||
from `Flask-Babel`:
|
||||
- `gettext` and `lazy_gettext` (usually aliased to `_`): for translating singular
|
||||
strings.
|
||||
- `ngettext`: for translating strings that might become plural.
|
||||
|
||||
```python
|
||||
from flask_babel import lazy_gettext as _
|
||||
```
|
||||
|
||||
then wrap the translatable strings with it, e.g. `_('Translate me')`.
|
||||
During extraction, string literals passed to `_` will be added to the
|
||||
generated `.po` file for each language for later translation.
|
||||
|
||||
At runtime, the `_` function will return the translation of the given
|
||||
string for the current language, or the given string itself
|
||||
if no translation is available.
|
||||
|
||||
In TypeScript/JavaScript, the technique is similar:
|
||||
we import `t` (simple translation), `tn` (translation containing a number).
|
||||
|
||||
```javascript
|
||||
import { t, tn } from "@superset-ui/translation";
|
||||
```
|
||||
|
||||
### Enabling language selection
|
||||
|
||||
Add the `LANGUAGES` variable to your `superset_config.py`. Having more than one
|
||||
option inside will add a language selection dropdown to the UI on the right side
|
||||
of the navigation bar.
|
||||
|
||||
```python
|
||||
LANGUAGES = {
|
||||
'en': {'flag': 'us', 'name': 'English'},
|
||||
'fr': {'flag': 'fr', 'name': 'French'},
|
||||
'zh': {'flag': 'cn', 'name': 'Chinese'},
|
||||
}
|
||||
```
|
||||
|
||||
### Creating a new language dictionary
|
||||
|
||||
First check if the language code for your target language already exists. Check if the
|
||||
[two letter ISO 639-1 code](https://en.wikipedia.org/wiki/List_of_ISO_639-1_codes)
|
||||
for your target language already exists in the `superset/translations` directory:
|
||||
|
||||
```bash
|
||||
ls superset/translations | grep -E "^[a-z]{2}\/"
|
||||
```
|
||||
|
||||
If your language already has a preexisting translation, skip to the next section
|
||||
|
||||
The following languages are already supported by Flask AppBuilder, and will make it
|
||||
easier to translate the application to your target language:
|
||||
[Flask AppBuilder i18n documentation](https://flask-appbuilder.readthedocs.io/en/latest/i18n.html)
|
||||
|
||||
To create a dictionary for a new language, first make sure the necessary dependencies are installed:
|
||||
```bash
|
||||
pip install -r superset/translations/requirements.txt
|
||||
```
|
||||
|
||||
Then run the following, where `LANGUAGE_CODE` is replaced with the language code for your target
|
||||
language:
|
||||
|
||||
```bash
|
||||
pybabel init -i superset/translations/messages.pot -d superset/translations -l LANGUAGE_CODE
|
||||
```
|
||||
|
||||
For instance, to add a translation for Finnish (language code `fi`), run the following:
|
||||
|
||||
```bash
|
||||
pybabel init -i superset/translations/messages.pot -d superset/translations -l fi
|
||||
```
|
||||
|
||||
### Extracting new strings for translation
|
||||
|
||||
This step needs to be done every time application strings change. This happens fairly
|
||||
frequently, so if you want to ensure that your translation has good coverage, this
|
||||
step needs to be run fairly frequently and the updated strings merged to the upstream
|
||||
codebase via PRs. To update the template file `superset/translations/messages.pot`
|
||||
with current application strings, run the following command:
|
||||
|
||||
```bash
|
||||
pybabel extract -F superset/translations/babel.cfg -o superset/translations/messages.pot -k _ -k __ -k t -k tn -k tct .
|
||||
```
|
||||
|
||||
Do not forget to update this file with the appropriate license information.
|
||||
|
||||
### Updating language files
|
||||
|
||||
Run the following command to update the language files with the new extracted strings.
|
||||
|
||||
```bash
|
||||
pybabel update -i superset/translations/messages.pot -d superset/translations --ignore-obsolete
|
||||
```
|
||||
|
||||
You can then translate the strings gathered in files located under
|
||||
`superset/translation`, where there's one folder per language. You can use [Poedit](https://poedit.net/features)
|
||||
to translate the `po` file more conveniently.
|
||||
Here is [a tutorial](https://web.archive.org/web/20220517065036/https://wiki.lxde.org/en/Translate_*.po_files_with_Poedit).
|
||||
|
||||
To perform the translation on MacOS, you can install `poedit` via Homebrew:
|
||||
|
||||
```bash
|
||||
brew install poedit
|
||||
```
|
||||
|
||||
After this, just start the `poedit` application and open the `messages.po` file. In the
|
||||
case of the Finnish translation, this would be `superset/translations/fi/LC_MESSAGES/messages.po`.
|
||||
|
||||
### Applying translations
|
||||
|
||||
To make the translations available on the frontend, we need to convert the PO file into
|
||||
a JSON file. To do this, we need to globally install the npm package `po2json`.
|
||||
|
||||
```bash
|
||||
npm install -g po2json
|
||||
```
|
||||
|
||||
To convert all PO files to formatted JSON files you can use the `po2json.sh` script.
|
||||
|
||||
```bash
|
||||
./scripts/po2json.sh
|
||||
```
|
||||
|
||||
If you get errors running `po2json`, you might be running the Ubuntu package with the same
|
||||
name, rather than the Node.js package (they have a different format for the arguments). If
|
||||
there is a conflict, you may need to update your `PATH` environment variable or fully qualify
|
||||
the executable path (e.g. `/usr/local/bin/po2json` instead of `po2json`).
|
||||
If you get a lot of `[null,***]` in `messages.json`, just delete all the `null,`.
|
||||
For example, `"year":["年"]` is correct while `"year":[null,"年"]`is incorrect.
|
||||
|
||||
Finally, for the translations to take effect we need to compile translation catalogs into
|
||||
binary MO files.
|
||||
|
||||
```bash
|
||||
pybabel compile -d superset/translations
|
||||
```
|
||||
|
||||
## Linting
|
||||
|
||||
### Python
|
||||
|
||||
We use [Pylint](https://pylint.org/) for linting which can be invoked via:
|
||||
|
||||
```bash
|
||||
# for python
|
||||
tox -e pylint
|
||||
```
|
||||
|
||||
In terms of best practices please avoid blanket disabling of Pylint messages globally (via `.pylintrc`) or top-level within the file header, albeit there being a few exceptions. Disabling should occur inline as it prevents masking issues and provides context as to why said message is disabled.
|
||||
|
||||
Additionally, the Python code is auto-formatted using [Black](https://github.com/python/black) which
|
||||
is configured as a pre-commit hook. There are also numerous [editor integrations](https://black.readthedocs.io/en/stable/integrations/editors.html)
|
||||
|
||||
### TypeScript
|
||||
|
||||
```bash
|
||||
cd superset-frontend
|
||||
npm ci
|
||||
# run eslint checks
|
||||
npm run eslint -- .
|
||||
# run tsc (typescript) checks
|
||||
npm run type
|
||||
```
|
||||
|
||||
If using the eslint extension with vscode, put the following in your workspace `settings.json` file:
|
||||
|
||||
```json
|
||||
"eslint.workingDirectories": [
|
||||
"superset-frontend"
|
||||
]
|
||||
```
|
||||
|
|
@ -1,109 +0,0 @@
|
|||
---
|
||||
title: Running a Local Flask Backend
|
||||
hide_title: true
|
||||
sidebar_position: 5
|
||||
version: 1
|
||||
---
|
||||
|
||||
### Flask server
|
||||
|
||||
#### OS Dependencies
|
||||
|
||||
Make sure your machine meets the [OS dependencies](/docs/installation/installing-superset-from-pypi#os-dependencies) before following these steps.
|
||||
You also need to install MySQL or [MariaDB](https://mariadb.com/downloads).
|
||||
|
||||
Ensure that you are using Python version 3.10 or 3.11, then proceed with:
|
||||
|
||||
```bash
|
||||
# Create a virtual environment and activate it (recommended)
|
||||
python3 -m venv venv # setup a python3 virtualenv
|
||||
source venv/bin/activate
|
||||
|
||||
# Install external dependencies
|
||||
pip install -r requirements/development.txt
|
||||
|
||||
# Install Superset in editable (development) mode
|
||||
pip install -e .
|
||||
|
||||
# Initialize the database
|
||||
# Note: For generating a SECRET_KEY if you haven't done already, you can use the command:
|
||||
# echo "SECRET_KEY='$(openssl rand -base64 42)'" | tee -a superset_config.py
|
||||
superset db upgrade
|
||||
|
||||
# Create an admin user in your metadata database (use `admin` as username to be able to load the examples)
|
||||
superset fab create-admin
|
||||
|
||||
# Create default roles and permissions
|
||||
superset init
|
||||
|
||||
# Load some data to play with.
|
||||
# Note: you MUST have previously created an admin user with the username `admin` for this command to work.
|
||||
superset load-examples
|
||||
|
||||
# Start the Flask dev web server from inside your virtualenv.
|
||||
# Note that your page may not have CSS at this point.
|
||||
superset run -p 8088 --with-threads --reload --debugger --debug
|
||||
```
|
||||
|
||||
Or you can install via our Makefile
|
||||
|
||||
```bash
|
||||
# Create a virtual environment and activate it (recommended)
|
||||
python3 -m venv venv # setup a python3 virtualenv
|
||||
source venv/bin/activate
|
||||
|
||||
# install pip packages + pre-commit
|
||||
make install
|
||||
|
||||
# Install superset pip packages and setup env only
|
||||
make superset
|
||||
|
||||
# Setup pre-commit only
|
||||
make pre-commit
|
||||
```
|
||||
|
||||
**Note: the FLASK_APP env var should not need to be set, as it's currently controlled
|
||||
via `.flaskenv`, however if needed, it should be set to `superset.app:create_app()`**
|
||||
|
||||
If you have made changes to the FAB-managed templates, which are not built the same way as the newer, React-powered front-end assets, you need to start the app without the `--with-threads` argument like so:
|
||||
`superset run -p 8088 --reload --debugger --debug`
|
||||
|
||||
#### Dependencies
|
||||
|
||||
If you add a new requirement or update an existing requirement (per the `install_requires` section in `setup.py`) you must recompile (freeze) the Python dependencies to ensure that for CI, testing, etc. the build is deterministic. This can be achieved via,
|
||||
|
||||
```bash
|
||||
$ python3 -m venv venv
|
||||
$ source venv/bin/activate
|
||||
$ python3 -m pip install -r requirements/development.txt
|
||||
$ pip-compile-multi --no-upgrade
|
||||
```
|
||||
|
||||
#### Logging to the browser console
|
||||
|
||||
This feature is only available on Python 3. When debugging your application, you can have the server logs sent directly to the browser console using the [ConsoleLog](https://github.com/betodealmeida/consolelog) package. You need to mutate the app, by adding the following to your `config.py` or `superset_config.py`:
|
||||
|
||||
```python
|
||||
from console_log import ConsoleLog
|
||||
|
||||
def FLASK_APP_MUTATOR(app):
|
||||
app.wsgi_app = ConsoleLog(app.wsgi_app, app.logger)
|
||||
```
|
||||
|
||||
Then make sure you run your WSGI server using the right worker type:
|
||||
|
||||
```bash
|
||||
SUPERSET_ENV=development gunicorn "superset.app:create_app()" -k "geventwebsocket.gunicorn.workers.GeventWebSocketWorker" -b 127.0.0.1:8088 --reload
|
||||
```
|
||||
|
||||
You can log anything to the browser console, including objects:
|
||||
|
||||
```python
|
||||
from superset import app
|
||||
app.logger.error('An exception occurred!')
|
||||
app.logger.info(form_data)
|
||||
```
|
||||
|
||||
### Frontend Assets
|
||||
|
||||
See [Building Frontend Assets Locally](https://github.com/apache/superset/blob/master/CONTRIBUTING.md#frontend)
|
||||
|
|
@ -0,0 +1,55 @@
|
|||
---
|
||||
sidebar_position: 6
|
||||
version: 1
|
||||
---
|
||||
|
||||
# Misc.
|
||||
|
||||
## Reporting a Security Vulnerability
|
||||
|
||||
Please report security vulnerabilities to private@superset.apache.org.
|
||||
|
||||
In the event a community member discovers a security flaw in Superset, it is important to follow the [Apache Security Guidelines](https://www.apache.org/security/committers.html) and release a fix as quickly as possible before public disclosure. Reporting security vulnerabilities through the usual GitHub Issues channel is not ideal as it will publicize the flaw before a fix can be applied.
|
||||
|
||||
### SQL Lab Async
|
||||
|
||||
It's possible to configure a local database to operate in `async` mode,
|
||||
to work on `async` related features.
|
||||
|
||||
To do this, you'll need to:
|
||||
|
||||
- Add an additional database entry. We recommend you copy the connection
|
||||
string from the database labeled `main`, and then enable `SQL Lab` and the
|
||||
features you want to use. Don't forget to check the `Async` box
|
||||
- Configure a results backend, here's a local `FileSystemCache` example,
|
||||
not recommended for production,
|
||||
but perfect for testing (stores cache in `/tmp`)
|
||||
|
||||
```python
|
||||
from flask_caching.backends.filesystemcache import FileSystemCache
|
||||
RESULTS_BACKEND = FileSystemCache('/tmp/sqllab')
|
||||
```
|
||||
|
||||
- Start up a celery worker
|
||||
|
||||
```shell script
|
||||
celery --app=superset.tasks.celery_app:app worker -O fair
|
||||
```
|
||||
|
||||
Note that:
|
||||
|
||||
- for changes that affect the worker logic, you'll have to
|
||||
restart the `celery worker` process for the changes to be reflected.
|
||||
- The message queue used is a `sqlite` database using the `SQLAlchemy`
|
||||
experimental broker. Ok for testing, but not recommended in production
|
||||
- In some cases, you may want to create a context that is more aligned
|
||||
to your production environment, and use the similar broker as well as
|
||||
results backend configuration
|
||||
|
||||
### Async Chart Queries
|
||||
|
||||
It's possible to configure database queries for charts to operate in `async` mode. This is especially useful for dashboards with many charts that may otherwise be affected by browser connection limits. To enable async queries for dashboards and Explore, the following dependencies are required:
|
||||
|
||||
- Redis 5.0+ (the feature utilizes [Redis Streams](https://redis.io/topics/streams-intro))
|
||||
- Cache backends enabled via the `CACHE_CONFIG` and `DATA_CACHE_CONFIG` config settings
|
||||
- Celery workers configured and running to process async tasks
|
||||
|
|
@ -1,96 +0,0 @@
|
|||
---
|
||||
title: Pull Request Guidelines
|
||||
hide_title: true
|
||||
sidebar_position: 3
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Pull Request Guidelines
|
||||
|
||||
A philosophy we would like to strongly encourage is
|
||||
|
||||
> Before creating a PR, create an issue.
|
||||
|
||||
The purpose is to separate problem from possible solutions.
|
||||
|
||||
**Bug fixes:** If you’re only fixing a small bug, it’s fine to submit a pull request right away but we highly recommend to file an issue detailing what you’re fixing. This is helpful in case we don’t accept that specific fix but want to keep track of the issue. Please keep in mind that the project maintainers reserve the rights to accept or reject incoming PRs, so it is better to separate the issue and the code to fix it from each other. In some cases, project maintainers may request you to create a separate issue from PR before proceeding.
|
||||
|
||||
**Refactor:** For small refactors, it can be a standalone PR itself detailing what you are refactoring and why. If there are concerns, project maintainers may request you to create a `#SIP` for the PR before proceeding.
|
||||
|
||||
**Feature/Large changes:** If you intend to change the public API, or make any non-trivial changes to the implementation, we require you to file a new issue as `#SIP` (Superset Improvement Proposal). This lets us reach an agreement on your proposal before you put significant effort into it. You are welcome to submit a PR along with the SIP (sometimes necessary for demonstration), but we will not review/merge the code until the SIP is approved.
|
||||
|
||||
In general, small PRs are always easier to review than large PRs. The best practice is to break your work into smaller independent PRs and refer to the same issue. This will greatly reduce turnaround time.
|
||||
|
||||
If you wish to share your work which is not ready to merge yet, create a [Draft PR](https://github.blog/2019-02-14-introducing-draft-pull-requests/). This will enable maintainers and the CI runner to prioritize mature PR's.
|
||||
|
||||
Finally, never submit a PR that will put master branch in broken state. If the PR is part of multiple PRs to complete a large feature and cannot work on its own, you can create a feature branch and merge all related PRs into the feature branch before creating a PR from feature branch to master.
|
||||
|
||||
### Protocol
|
||||
|
||||
#### Authoring
|
||||
|
||||
- Fill in all sections of the PR template.
|
||||
- Title the PR with one of the following semantic prefixes (inspired by [Karma](http://karma-runner.github.io/0.10/dev/git-commit-msg.html])):
|
||||
|
||||
- `feat` (new feature)
|
||||
- `fix` (bug fix)
|
||||
- `docs` (changes to the documentation)
|
||||
- `style` (formatting, missing semi colons, etc; no application logic change)
|
||||
- `refactor` (refactoring code)
|
||||
- `test` (adding missing tests, refactoring tests; no application logic change)
|
||||
- `chore` (updating tasks etc; no application logic change)
|
||||
- `perf` (performance-related change)
|
||||
- `build` (build tooling, Docker configuration change)
|
||||
- `ci` (test runner, GitHub Actions workflow changes)
|
||||
- `other` (changes that don't correspond to the above -- should be rare!)
|
||||
- Examples:
|
||||
- `feat: export charts as ZIP files`
|
||||
- `perf(api): improve API info performance`
|
||||
- `fix(chart-api): cached-indicator always shows value is cached`
|
||||
|
||||
- Add prefix `[WIP]` to title if not ready for review (WIP = work-in-progress). We recommend creating a PR with `[WIP]` first and remove it once you have passed CI test and read through your code changes at least once.
|
||||
- If you believe your PR contributes a potentially breaking change, put a `!` after the semantic prefix but before the colon in the PR title, like so: `feat!: Added foo functionality to bar`
|
||||
- **Screenshots/GIFs:** Changes to user interface require before/after screenshots, or GIF for interactions
|
||||
- Recommended capture tools ([Kap](https://getkap.co/), [LICEcap](https://www.cockos.com/licecap/), [Skitch](https://download.cnet.com/Skitch/3000-13455_4-189876.html))
|
||||
- If no screenshot is provided, the committers will mark the PR with `need:screenshot` label and will not review until screenshot is provided.
|
||||
- **Dependencies:** Be careful about adding new dependency and avoid unnecessary dependencies.
|
||||
- For Python, include it in `setup.py` denoting any specific restrictions and in `requirements.txt` pinned to a specific version which ensures that the application build is deterministic.
|
||||
- For TypeScript/JavaScript, include new libraries in `package.json`
|
||||
- **Tests:** The pull request should include tests, either as doctests, unit tests, or both. Make sure to resolve all errors and test failures. See [Testing](#testing) for how to run tests.
|
||||
- **Documentation:** If the pull request adds functionality, the docs should be updated as part of the same PR.
|
||||
- **CI:** Reviewers will not review the code until all CI tests are passed. Sometimes there can be flaky tests. You can close and open PR to re-run CI test. Please report if the issue persists. After the CI fix has been deployed to `master`, please rebase your PR.
|
||||
- **Code coverage:** Please ensure that code coverage does not decrease.
|
||||
- Remove `[WIP]` when ready for review. Please note that it may be merged soon after approved so please make sure the PR is ready to merge and do not expect more time for post-approval edits.
|
||||
- If the PR was not ready for review and inactive for > 30 days, we will close it due to inactivity. The author is welcome to re-open and update.
|
||||
|
||||
#### Reviewing
|
||||
|
||||
- Use constructive tone when writing reviews.
|
||||
- If there are changes required, state clearly what needs to be done before the PR can be approved.
|
||||
- If you are asked to update your pull request with some changes there's no need to create a new one. Push your changes to the same branch.
|
||||
- The committers reserve the right to reject any PR and in some cases may request the author to file an issue.
|
||||
|
||||
#### Test Environments
|
||||
|
||||
- Members of the Apache GitHub org can launch an ephemeral test environment directly on a pull request by creating a comment containing (only) the command `/testenv up`.
|
||||
- Note that org membership must be public in order for this validation to function properly.
|
||||
- Feature flags may be set for a test environment by specifying the flag name (prefixed with `FEATURE_`) and value after the command.
|
||||
- Format: `/testenv up FEATURE_<feature flag name>=true|false`
|
||||
- Example: `/testenv up FEATURE_DASHBOARD_NATIVE_FILTERS=true`
|
||||
- Multiple feature flags may be set in single command, separated by whitespace
|
||||
- A comment will be created by the workflow script with the address and login information for the ephemeral environment.
|
||||
- Test environments may be created once the Docker build CI workflow for the PR has completed successfully.
|
||||
- Test environments do not currently update automatically when new commits are added to a pull request.
|
||||
- Test environments do not currently support async workers, though this is planned.
|
||||
- Running test environments will be shutdown upon closing the pull request.
|
||||
|
||||
#### Merging
|
||||
|
||||
- At least one approval is required for merging a PR.
|
||||
- PR is usually left open for at least 24 hours before merging.
|
||||
- After the PR is merged, [close the corresponding issue(s)](https://help.github.com/articles/closing-issues-using-keywords/).
|
||||
|
||||
#### Post-merge Responsibility
|
||||
|
||||
- Project maintainers may contact the PR author if new issues are introduced by the PR.
|
||||
- Project maintainers may revert your changes if a critical issue is found, such as breaking master branch CI.
|
||||
|
|
@ -0,0 +1,18 @@
|
|||
---
|
||||
sidebar_position: 5
|
||||
version: 1
|
||||
---
|
||||
|
||||
import InteractiveSVG from '../../src/components/InteractiveERDSVG';
|
||||
|
||||
# Resources
|
||||
|
||||
## Entity-Relationship Diagram
|
||||
|
||||
Here is our interactive ERD:
|
||||
|
||||
<InteractiveSVG />
|
||||
|
||||
<br />
|
||||
|
||||
[Download the .svg](https://github.com/apache/superset/tree/master/docs/static/img/erd.svg)
|
||||
|
|
@ -1,54 +0,0 @@
|
|||
---
|
||||
title: Style Guide
|
||||
hide_title: true
|
||||
sidebar_position: 4
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Design Guidelines
|
||||
|
||||
### Capitalization guidelines
|
||||
|
||||
#### Sentence case
|
||||
|
||||
Use sentence-case capitalization for everything in the UI (except these \*\*).
|
||||
|
||||
Sentence case is predominantly lowercase. Capitalize only the initial character of the first word, and other words that require capitalization, like:
|
||||
|
||||
- **Proper nouns.** Objects in the product _are not_ considered proper nouns e.g. dashboards, charts, saved queries etc. Proprietary feature names eg. SQL Lab, Preset Manager _are_ considered proper nouns
|
||||
- **Acronyms** (e.g. CSS, HTML)
|
||||
- When referring to **UI labels that are themselves capitalized** from sentence case (e.g. page titles - Dashboards page, Charts page, Saved queries page, etc.)
|
||||
- User input that is reflected in the UI. E.g. a user-named a dashboard tab
|
||||
|
||||
**Sentence case vs. Title case:**
|
||||
Title case: "A Dog Takes a Walk in Paris"
|
||||
Sentence case: "A dog takes a walk in Paris"
|
||||
|
||||
**Why sentence case?**
|
||||
|
||||
- It’s generally accepted as the quickest to read
|
||||
- It’s the easiest form to distinguish between common and proper nouns
|
||||
|
||||
#### How to refer to UI elements
|
||||
|
||||
When writing about a UI element, use the same capitalization as used in the UI.
|
||||
|
||||
For example, if an input field is labeled “Name” then you refer to this as the “Name input field”. Similarly, if a button has the label “Save” in it, then it is correct to refer to the “Save button”.
|
||||
|
||||
Where a product page is titled “Settings”, you refer to this in writing as follows:
|
||||
“Edit your personal information on the Settings page”.
|
||||
|
||||
Often a product page will have the same title as the objects it contains. In this case, refer to the page as it appears in the UI, and the objects as common nouns:
|
||||
|
||||
- Upload a dashboard on the Dashboards page
|
||||
- Go to Dashboards
|
||||
- View dashboard
|
||||
- View all dashboards
|
||||
- Upload CSS templates on the CSS templates page
|
||||
- Queries that you save will appear on the Saved queries page
|
||||
- Create custom queries in SQL Lab then create dashboards
|
||||
|
||||
#### \*\*Exceptions to sentence case:
|
||||
|
||||
- Input labels, buttons and UI tabs are all caps
|
||||
- User input values (e.g. column names, SQL Lab tab names) should be in their original case
|
||||
|
|
@ -1,288 +0,0 @@
|
|||
---
|
||||
title: Testing
|
||||
hide_title: true
|
||||
sidebar_position: 8
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Testing
|
||||
|
||||
### Python Testing
|
||||
|
||||
All python tests are carried out in [tox](https://tox.readthedocs.io/en/latest/index.html)
|
||||
a standardized testing framework.
|
||||
All python tests can be run with any of the tox [environments](https://tox.readthedocs.io/en/latest/example/basic.html#a-simple-tox-ini-default-environments), via,
|
||||
|
||||
```bash
|
||||
tox -e <environment>
|
||||
```
|
||||
|
||||
For example,
|
||||
|
||||
```bash
|
||||
tox -e py38
|
||||
```
|
||||
|
||||
Alternatively, you can run all tests in a single file via,
|
||||
|
||||
```bash
|
||||
tox -e <environment> -- tests/test_file.py
|
||||
```
|
||||
|
||||
or for a specific test via,
|
||||
|
||||
```bash
|
||||
tox -e <environment> -- tests/test_file.py::TestClassName::test_method_name
|
||||
```
|
||||
|
||||
Note that the test environment uses a temporary directory for defining the
|
||||
SQLite databases which will be cleared each time before the group of test
|
||||
commands are invoked.
|
||||
|
||||
There is also a utility script included in the Superset codebase to run python integration tests. The [readme can be
|
||||
found here](https://github.com/apache/superset/tree/master/scripts/tests)
|
||||
|
||||
To run all integration tests for example, run this script from the root directory:
|
||||
|
||||
```bash
|
||||
scripts/tests/run.sh
|
||||
```
|
||||
|
||||
You can run unit tests found in './tests/unit_tests' for example with pytest. It is a simple way to run an isolated test that doesn't need any database setup
|
||||
|
||||
```bash
|
||||
pytest ./link_to_test.py
|
||||
```
|
||||
|
||||
#### Testing with local Presto connections
|
||||
|
||||
If you happen to change db engine spec for Presto/Trino, you can run a local Presto cluster with Docker:
|
||||
|
||||
```bash
|
||||
docker run -p 15433:15433 starburstdata/presto:350-e.6
|
||||
```
|
||||
|
||||
Then update `SUPERSET__SQLALCHEMY_EXAMPLES_URI` to point to local Presto cluster:
|
||||
|
||||
```bash
|
||||
export SUPERSET__SQLALCHEMY_EXAMPLES_URI=presto://localhost:15433/memory/default
|
||||
```
|
||||
|
||||
### Frontend Testing
|
||||
|
||||
We use [Jest](https://jestjs.io/) and [Enzyme](https://airbnb.io/enzyme/) to test TypeScript/JavaScript. Tests can be run with:
|
||||
|
||||
```bash
|
||||
cd superset-frontend
|
||||
npm run test
|
||||
```
|
||||
|
||||
To run a single test file:
|
||||
|
||||
```bash
|
||||
npm run test -- path/to/file.js
|
||||
```
|
||||
|
||||
### Integration Testing
|
||||
|
||||
We use [Cypress](https://www.cypress.io/) for integration tests. Tests can be run by `tox -e cypress`. To open Cypress and explore tests first setup and run test server:
|
||||
|
||||
```bash
|
||||
export SUPERSET_CONFIG=tests.integration_tests.superset_test_config
|
||||
export SUPERSET_TESTENV=true
|
||||
export CYPRESS_BASE_URL="http://localhost:8081"
|
||||
superset db upgrade
|
||||
superset load_test_users
|
||||
superset init
|
||||
superset load-examples --load-test-data
|
||||
superset run --port 8081
|
||||
```
|
||||
|
||||
Run Cypress tests:
|
||||
|
||||
```bash
|
||||
cd superset-frontend
|
||||
npm run build-instrumented
|
||||
|
||||
cd cypress-base
|
||||
npm install
|
||||
|
||||
# run tests via headless Chrome browser (requires Chrome 64+)
|
||||
npm run cypress-run-chrome
|
||||
|
||||
# run tests from a specific file
|
||||
npm run cypress-run-chrome -- --spec cypress/e2e/explore/link.test.ts
|
||||
|
||||
# run specific file with video capture
|
||||
npm run cypress-run-chrome -- --spec cypress/e2e/dashboard/index.test.js --config video=true
|
||||
|
||||
# to open the cypress ui
|
||||
npm run cypress-debug
|
||||
|
||||
# to point cypress to a url other than the default (http://localhost:8088) set the environment variable before running the script
|
||||
# e.g., CYPRESS_BASE_URL="http://localhost:9000"
|
||||
CYPRESS_BASE_URL=<your url> npm run cypress open
|
||||
```
|
||||
|
||||
See [`superset-frontend/cypress_build.sh`](https://github.com/apache/superset/blob/master/superset-frontend/cypress_build.sh).
|
||||
|
||||
As an alternative you can use docker compose environment for testing:
|
||||
|
||||
Make sure you have added below line to your /etc/hosts file:
|
||||
`127.0.0.1 db`
|
||||
|
||||
If you already have launched Docker environment please use the following command to assure a fresh database instance:
|
||||
`docker compose down -v`
|
||||
|
||||
Launch environment:
|
||||
|
||||
`CYPRESS_CONFIG=true docker compose up`
|
||||
|
||||
It will serve backend and frontend on port 8088.
|
||||
|
||||
Run Cypress tests:
|
||||
|
||||
```bash
|
||||
cd cypress-base
|
||||
npm install
|
||||
npm run cypress open
|
||||
```
|
||||
|
||||
### Debugging Server App
|
||||
|
||||
Follow these instructions to debug the Flask app running inside a docker container.
|
||||
|
||||
First add the following to the ./docker-compose.yaml file
|
||||
|
||||
```diff
|
||||
superset:
|
||||
env_file: docker/.env
|
||||
image: *superset-image
|
||||
container_name: superset_app
|
||||
command: ["/app/docker/docker-bootstrap.sh", "app"]
|
||||
restart: unless-stopped
|
||||
+ cap_add:
|
||||
+ - SYS_PTRACE
|
||||
ports:
|
||||
- 8088:8088
|
||||
+ - 5678:5678
|
||||
user: "root"
|
||||
depends_on: *superset-depends-on
|
||||
volumes: *superset-volumes
|
||||
environment:
|
||||
CYPRESS_CONFIG: "${CYPRESS_CONFIG}"
|
||||
```
|
||||
|
||||
Start Superset as usual
|
||||
|
||||
```bash
|
||||
docker compose up
|
||||
```
|
||||
|
||||
Install the required libraries and packages to the docker container
|
||||
|
||||
Enter the superset_app container
|
||||
|
||||
```bash
|
||||
docker exec -it superset_app /bin/bash
|
||||
root@39ce8cf9d6ab:/app#
|
||||
```
|
||||
|
||||
Run the following commands inside the container
|
||||
|
||||
```bash
|
||||
apt update
|
||||
apt install -y gdb
|
||||
apt install -y net-tools
|
||||
pip install debugpy
|
||||
```
|
||||
|
||||
Find the PID for the Flask process. Make sure to use the first PID. The Flask app will re-spawn a sub-process every time you change any of the python code. So it's important to use the first PID.
|
||||
|
||||
```bash
|
||||
ps -ef
|
||||
|
||||
UID PID PPID C STIME TTY TIME CMD
|
||||
root 1 0 0 14:09 ? 00:00:00 bash /app/docker/docker-bootstrap.sh app
|
||||
root 6 1 4 14:09 ? 00:00:04 /usr/local/bin/python /usr/bin/flask run -p 8088 --with-threads --reload --debugger --host=0.0.0.0
|
||||
root 10 6 7 14:09 ? 00:00:07 /usr/local/bin/python /usr/bin/flask run -p 8088 --with-threads --reload --debugger --host=0.0.0.0
|
||||
```
|
||||
|
||||
Inject debugpy into the running Flask process. In this case PID 6.
|
||||
|
||||
```bash
|
||||
python3 -m debugpy --listen 0.0.0.0:5678 --pid 6
|
||||
```
|
||||
|
||||
Verify that debugpy is listening on port 5678
|
||||
|
||||
```bash
|
||||
netstat -tunap
|
||||
|
||||
Active Internet connections (servers and established)
|
||||
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
|
||||
tcp 0 0 0.0.0.0:5678 0.0.0.0:* LISTEN 462/python
|
||||
tcp 0 0 0.0.0.0:8088 0.0.0.0:* LISTEN 6/python
|
||||
```
|
||||
|
||||
You are now ready to attach a debugger to the process. Using VSCode you can configure a launch configuration file .vscode/launch.json like so.
|
||||
|
||||
```
|
||||
{
|
||||
"version": "0.2.0",
|
||||
"configurations": [
|
||||
{
|
||||
"name": "Attach to Superset App in Docker Container",
|
||||
"type": "python",
|
||||
"request": "attach",
|
||||
"connect": {
|
||||
"host": "127.0.0.1",
|
||||
"port": 5678
|
||||
},
|
||||
"pathMappings": [
|
||||
{
|
||||
"localRoot": "${workspaceFolder}",
|
||||
"remoteRoot": "/app"
|
||||
}
|
||||
]
|
||||
},
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
VSCode will not stop on breakpoints right away. We've attached to PID 6 however it does not yet know of any sub-processes. In order to "wakeup" the debugger you need to modify a python file. This will trigger Flask to reload the code and create a new sub-process. This new sub-process will be detected by VSCode and breakpoints will be activated.
|
||||
|
||||
### Debugging Server App in Kubernetes Environment
|
||||
|
||||
To debug Flask running in POD inside kubernetes cluster. You'll need to make sure the pod runs as root and is granted the SYS_TRACE capability.These settings should not be used in production environments.
|
||||
|
||||
```
|
||||
securityContext:
|
||||
capabilities:
|
||||
add: ["SYS_PTRACE"]
|
||||
```
|
||||
|
||||
See (set capabilities for a container)[https://kubernetes.io/docs/tasks/configure-pod-container/security-context/#set-capabilities-for-a-container] for more details.
|
||||
|
||||
Once the pod is running as root and has the SYS_PTRACE capability it will be able to debug the Flask app.
|
||||
|
||||
You can follow the same instructions as in the docker-compose. Enter the pod and install the required library and packages; gdb, netstat and debugpy.
|
||||
|
||||
Often in a Kubernetes environment nodes are not addressable from outside the cluster. VSCode will thus be unable to remotely connect to port 5678 on a Kubernetes node. In order to do this you need to create a tunnel that port forwards 5678 to your local machine.
|
||||
|
||||
```
|
||||
kubectl port-forward pod/superset-<some random id> 5678:5678
|
||||
```
|
||||
|
||||
You can now launch your VSCode debugger with the same config as above. VSCode will connect to to 127.0.0.1:5678 which is forwarded by kubectl to your remote kubernetes POD.
|
||||
|
||||
### Storybook
|
||||
|
||||
Superset includes a [Storybook](https://storybook.js.org/) to preview the layout/styling of various Superset components, and variations thereof. To open and view the Storybook:
|
||||
|
||||
```bash
|
||||
cd superset-frontend
|
||||
npm run storybook
|
||||
```
|
||||
|
||||
When contributing new React components to Superset, please try to add a Story alongside the component's `jsx/tsx` file.
|
||||
|
|
@ -1,148 +0,0 @@
|
|||
---
|
||||
title: Translating
|
||||
hide_title: true
|
||||
sidebar_position: 9
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Translating
|
||||
|
||||
We use [Flask-Babel](https://python-babel.github.io/flask-babel/) to translate Superset.
|
||||
In Python files, we use the following
|
||||
[translation functions](https://python-babel.github.io/flask-babel/#using-translations)
|
||||
from `Flask-Babel`:
|
||||
- `gettext` and `lazy_gettext` (usually aliased to `_`): for translating singular
|
||||
strings.
|
||||
- `ngettext`: for translating strings that might become plural.
|
||||
|
||||
```python
|
||||
from flask_babel import lazy_gettext as _
|
||||
```
|
||||
|
||||
then wrap the translatable strings with it, e.g. `_('Translate me')`.
|
||||
During extraction, string literals passed to `_` will be added to the
|
||||
generated `.po` file for each language for later translation.
|
||||
|
||||
At runtime, the `_` function will return the translation of the given
|
||||
string for the current language, or the given string itself
|
||||
if no translation is available.
|
||||
|
||||
In TypeScript/JavaScript, the technique is similar:
|
||||
we import `t` (simple translation), `tn` (translation containing a number).
|
||||
|
||||
```javascript
|
||||
import { t, tn } from "@superset-ui/translation";
|
||||
```
|
||||
|
||||
### Enabling language selection
|
||||
|
||||
Add the `LANGUAGES` variable to your `superset_config.py`. Having more than one
|
||||
option inside will add a language selection dropdown to the UI on the right side
|
||||
of the navigation bar.
|
||||
|
||||
```python
|
||||
LANGUAGES = {
|
||||
'en': {'flag': 'us', 'name': 'English'},
|
||||
'fr': {'flag': 'fr', 'name': 'French'},
|
||||
'zh': {'flag': 'cn', 'name': 'Chinese'},
|
||||
}
|
||||
```
|
||||
|
||||
### Creating a new language dictionary
|
||||
|
||||
First check if the language code for your target language already exists. Check if the
|
||||
[two letter ISO 639-1 code](https://en.wikipedia.org/wiki/List_of_ISO_639-1_codes)
|
||||
for your target language already exists in the `superset/translations` directory:
|
||||
|
||||
```bash
|
||||
ls superset/translations | grep -E "^[a-z]{2}\/"
|
||||
```
|
||||
|
||||
If your language already has a preexisting translation, skip to the next section
|
||||
|
||||
The following languages are already supported by Flask AppBuilder, and will make it
|
||||
easier to translate the application to your target language:
|
||||
[Flask AppBuilder i18n documentation](https://flask-appbuilder.readthedocs.io/en/latest/i18n.html)
|
||||
|
||||
To create a dictionary for a new language, first make sure the necessary dependencies are installed:
|
||||
```bash
|
||||
pip install -r superset/translations/requirements.txt
|
||||
```
|
||||
|
||||
Then run the following, where `LANGUAGE_CODE` is replaced with the language code for your target
|
||||
language:
|
||||
|
||||
```bash
|
||||
pybabel init -i superset/translations/messages.pot -d superset/translations -l LANGUAGE_CODE
|
||||
```
|
||||
|
||||
For instance, to add a translation for Finnish (language code `fi`), run the following:
|
||||
|
||||
```bash
|
||||
pybabel init -i superset/translations/messages.pot -d superset/translations -l fi
|
||||
```
|
||||
|
||||
### Extracting new strings for translation
|
||||
|
||||
This step needs to be done every time application strings change. This happens fairly
|
||||
frequently, so if you want to ensure that your translation has good coverage, this
|
||||
step needs to be run fairly frequently and the updated strings merged to the upstream
|
||||
codebase via PRs. To update the template file `superset/translations/messages.pot`
|
||||
with current application strings, run the following command:
|
||||
|
||||
```bash
|
||||
pybabel extract -F superset/translations/babel.cfg -o superset/translations/messages.pot -k _ -k __ -k t -k tn -k tct .
|
||||
```
|
||||
|
||||
Do not forget to update this file with the appropriate license information.
|
||||
|
||||
### Updating language files
|
||||
|
||||
Run the following command to update the language files with the new extracted strings.
|
||||
|
||||
```bash
|
||||
pybabel update -i superset/translations/messages.pot -d superset/translations --ignore-obsolete
|
||||
```
|
||||
|
||||
You can then translate the strings gathered in files located under
|
||||
`superset/translation`, where there's one folder per language. You can use [Poedit](https://poedit.net/features)
|
||||
to translate the `po` file more conveniently.
|
||||
Here is [a tutorial](https://web.archive.org/web/20220517065036/https://wiki.lxde.org/en/Translate_*.po_files_with_Poedit).
|
||||
|
||||
To perform the translation on MacOS, you can install `poedit` via Homebrew:
|
||||
|
||||
```bash
|
||||
brew install poedit
|
||||
```
|
||||
|
||||
After this, just start the `poedit` application and open the `messages.po` file. In the
|
||||
case of the Finnish translation, this would be `superset/translations/fi/LC_MESSAGES/messages.po`.
|
||||
|
||||
### Applying translations
|
||||
|
||||
To make the translations available on the frontend, we need to convert the PO file into
|
||||
a JSON file. To do this, we need to globally install the npm package `po2json`.
|
||||
|
||||
```bash
|
||||
npm install -g po2json
|
||||
```
|
||||
|
||||
To convert all PO files to formatted JSON files you can use the `po2json.sh` script.
|
||||
|
||||
```bash
|
||||
./scripts/po2json.sh
|
||||
```
|
||||
|
||||
If you get errors running `po2json`, you might be running the Ubuntu package with the same
|
||||
name, rather than the Node.js package (they have a different format for the arguments). If
|
||||
there is a conflict, you may need to update your `PATH` environment variable or fully qualify
|
||||
the executable path (e.g. `/usr/local/bin/po2json` instead of `po2json`).
|
||||
If you get a lot of `[null,***]` in `messages.json`, just delete all the `null,`.
|
||||
For example, `"year":["年"]` is correct while `"year":[null,"年"]`is incorrect.
|
||||
|
||||
Finally, for the translations to take effect we need to compile translation catalogs into
|
||||
binary MO files.
|
||||
|
||||
```bash
|
||||
pybabel compile -d superset/translations
|
||||
```
|
||||
|
|
@ -1,62 +0,0 @@
|
|||
---
|
||||
title: Types of Contributions
|
||||
hide_title: true
|
||||
sidebar_position: 2
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Types of Contributions
|
||||
|
||||
### Report Bug
|
||||
|
||||
The best way to report a bug is to file an issue on GitHub. Please include:
|
||||
|
||||
- Your operating system name and version.
|
||||
- Superset version.
|
||||
- Detailed steps to reproduce the bug.
|
||||
- Any details about your local setup that might be helpful in troubleshooting.
|
||||
|
||||
When posting Python stack traces, please quote them using
|
||||
[Markdown blocks](https://help.github.com/articles/creating-and-highlighting-code-blocks/).
|
||||
|
||||
_Please note that feature requests opened as GitHub Issues will be moved to Discussions._
|
||||
|
||||
### Submit Ideas or Feature Requests
|
||||
|
||||
The best way is to start an ["Ideas" Discussion thread](https://github.com/apache/superset/discussions/categories/ideas) on GitHub:
|
||||
|
||||
- Explain in detail how it would work.
|
||||
- Keep the scope as narrow as possible, to make it easier to implement.
|
||||
- Remember that this is a volunteer-driven project, and that your contributions are as welcome as anyone's :)
|
||||
|
||||
To propose large features or major changes to codebase, and help usher in those changes, please create a **Superset Improvement Proposal (SIP)**. See template from [SIP-0](https://github.com/apache/superset/issues/5602)
|
||||
|
||||
### Fix Bugs
|
||||
|
||||
Look through the GitHub issues. Issues tagged with `#bug` are
|
||||
open to whoever wants to implement them.
|
||||
|
||||
### Implement Features
|
||||
|
||||
Look through the GitHub issues. Issues tagged with
|
||||
`#feature` is open to whoever wants to implement it.
|
||||
|
||||
### Improve Documentation
|
||||
|
||||
Superset could always use better documentation,
|
||||
whether as part of the official Superset docs,
|
||||
in docstrings, `docs/*.rst` or even on the web as blog posts or
|
||||
articles. See [Documentation](#documentation) for more details.
|
||||
|
||||
### Add Translations
|
||||
|
||||
If you are proficient in a non-English language, you can help translate
|
||||
text strings from Superset's UI. You can jump into the existing
|
||||
language dictionaries at
|
||||
`superset/translations/<language_code>/LC_MESSAGES/messages.po`, or
|
||||
even create a dictionary for a new language altogether.
|
||||
See [Translating](#translating) for more details.
|
||||
|
||||
### Ask Questions
|
||||
|
||||
There is a dedicated [`apache-superset` tag](https://stackoverflow.com/questions/tagged/apache-superset) on [StackOverflow](https://stackoverflow.com/). Please use it when asking questions.
|
||||
|
|
@ -1,4 +0,0 @@
|
|||
{
|
||||
"label": "Creating Charts and Dashboards",
|
||||
"position": 4
|
||||
}
|
||||
|
|
@ -1,4 +0,0 @@
|
|||
{
|
||||
"label": "Connecting to Databases",
|
||||
"position": 5
|
||||
}
|
||||
|
|
@ -1,16 +0,0 @@
|
|||
---
|
||||
title: Ascend.io
|
||||
hide_title: true
|
||||
sidebar_position: 10
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Ascend.io
|
||||
|
||||
The recommended connector library to Ascend.io is [impyla](https://github.com/cloudera/impyla).
|
||||
|
||||
The expected connection string is formatted as follows:
|
||||
|
||||
```
|
||||
ascend://{username}:{password}@{hostname}:{port}/{database}?auth_mechanism=PLAIN;use_ssl=true
|
||||
```
|
||||
|
|
@ -1,39 +0,0 @@
|
|||
---
|
||||
title: Amazon Athena
|
||||
hide_title: true
|
||||
sidebar_position: 4
|
||||
version: 1
|
||||
---
|
||||
|
||||
## AWS Athena
|
||||
|
||||
### PyAthenaJDBC
|
||||
|
||||
[PyAthenaJDBC](https://pypi.org/project/PyAthenaJDBC/) is a Python DB 2.0 compliant wrapper for the
|
||||
[Amazon Athena JDBC driver](https://docs.aws.amazon.com/athena/latest/ug/connect-with-jdbc.html).
|
||||
|
||||
The connection string for Amazon Athena is as follows:
|
||||
|
||||
```
|
||||
awsathena+jdbc://{aws_access_key_id}:{aws_secret_access_key}@athena.{region_name}.amazonaws.com/{schema_name}?s3_staging_dir={s3_staging_dir}&...
|
||||
```
|
||||
|
||||
Note that you'll need to escape & encode when forming the connection string like so:
|
||||
|
||||
```
|
||||
s3://... -> s3%3A//...
|
||||
```
|
||||
|
||||
### PyAthena
|
||||
|
||||
You can also use the [PyAthena library](https://pypi.org/project/PyAthena/) (no Java required) with the
|
||||
following connection string:
|
||||
|
||||
```
|
||||
awsathena+rest://{aws_access_key_id}:{aws_secret_access_key}@athena.{region_name}.amazonaws.com/{schema_name}?s3_staging_dir={s3_staging_dir}&...
|
||||
```
|
||||
|
||||
The PyAthena library also allows to assume a specific IAM role which you can define by adding following parameters in Superset's Athena database connection UI under ADVANCED --> Other --> ENGINE PARAMETERS.
|
||||
```
|
||||
{"connect_args":{"role_arn":"<role arn>"}}
|
||||
```
|
||||
|
|
@ -1,92 +0,0 @@
|
|||
---
|
||||
title: Google BigQuery
|
||||
hide_title: true
|
||||
sidebar_position: 20
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Google BigQuery
|
||||
|
||||
The recommended connector library for BigQuery is
|
||||
[sqlalchemy-bigquery](https://github.com/googleapis/python-bigquery-sqlalchemy).
|
||||
|
||||
### Install BigQuery Driver
|
||||
|
||||
Follow the steps [here](/docs/databases/docker-add-drivers) about how to
|
||||
install new database drivers when setting up Superset locally via docker compose.
|
||||
|
||||
```
|
||||
echo "sqlalchemy-bigquery" >> ./docker/requirements-local.txt
|
||||
```
|
||||
|
||||
### Connecting to BigQuery
|
||||
|
||||
When adding a new BigQuery connection in Superset, you'll need to add the GCP Service Account
|
||||
credentials file (as a JSON).
|
||||
|
||||
1. Create your Service Account via the Google Cloud Platform control panel, provide it access to the
|
||||
appropriate BigQuery datasets, and download the JSON configuration file for the service account.
|
||||
2. In Superset, you can either upload that JSON or add the JSON blob in the following format (this should be the content of your credential JSON file):
|
||||
|
||||
```
|
||||
{
|
||||
"type": "service_account",
|
||||
"project_id": "...",
|
||||
"private_key_id": "...",
|
||||
"private_key": "...",
|
||||
"client_email": "...",
|
||||
"client_id": "...",
|
||||
"auth_uri": "...",
|
||||
"token_uri": "...",
|
||||
"auth_provider_x509_cert_url": "...",
|
||||
"client_x509_cert_url": "..."
|
||||
}
|
||||
```
|
||||
|
||||
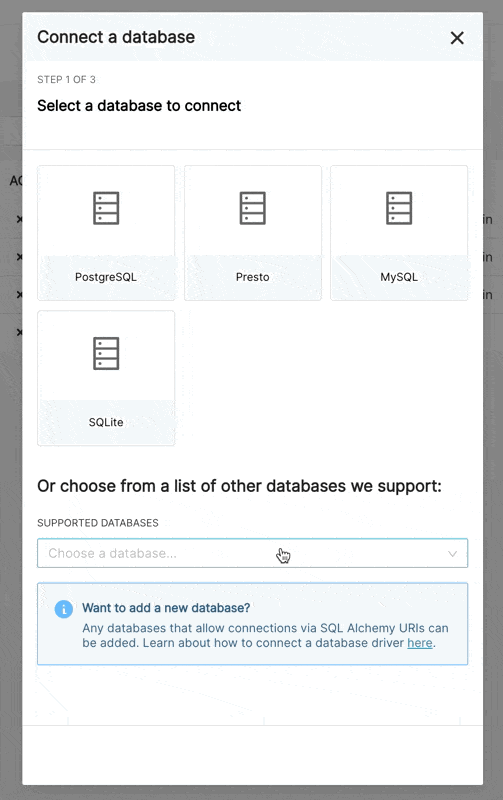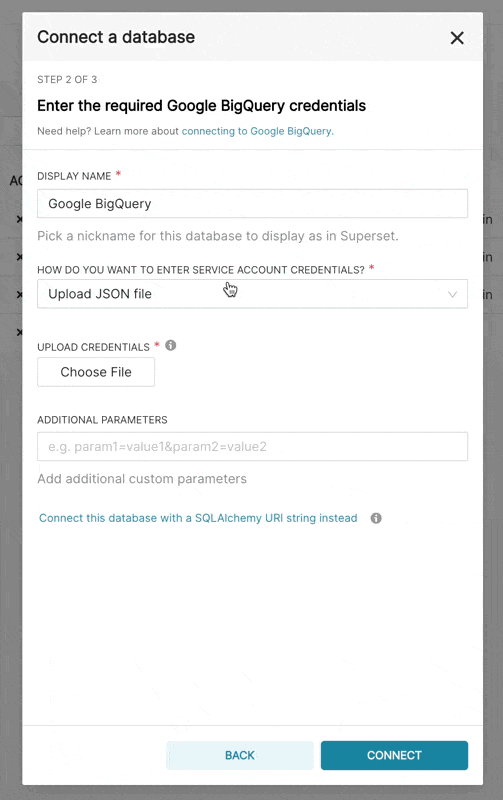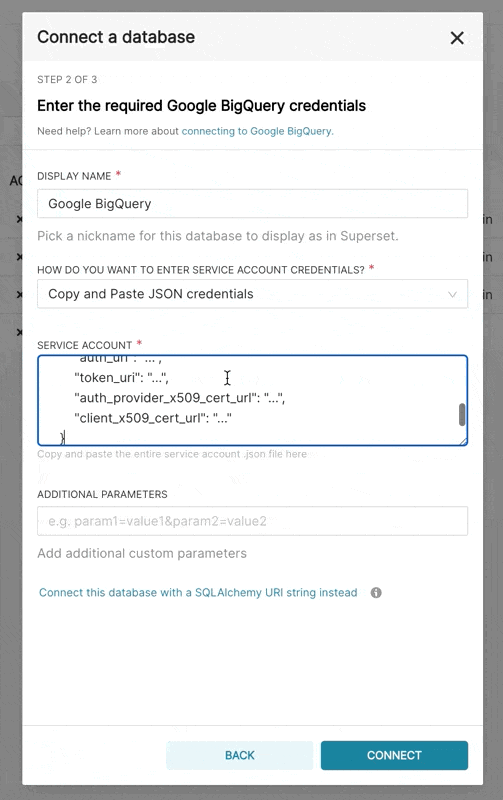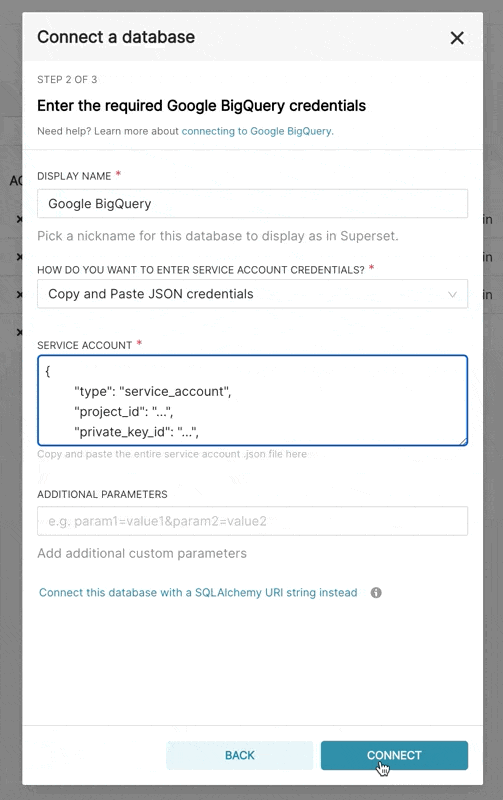
|
||||
|
||||
3. Additionally, can connect via SQLAlchemy URI instead
|
||||
|
||||
The connection string for BigQuery looks like:
|
||||
|
||||
```
|
||||
bigquery://{project_id}
|
||||
```
|
||||
|
||||
Go to the **Advanced** tab, Add a JSON blob to the **Secure Extra** field in the database configuration form with
|
||||
the following format:
|
||||
|
||||
```
|
||||
{
|
||||
"credentials_info": <contents of credentials JSON file>
|
||||
}
|
||||
```
|
||||
|
||||
The resulting file should have this structure:
|
||||
|
||||
```
|
||||
{
|
||||
"credentials_info": {
|
||||
"type": "service_account",
|
||||
"project_id": "...",
|
||||
"private_key_id": "...",
|
||||
"private_key": "...",
|
||||
"client_email": "...",
|
||||
"client_id": "...",
|
||||
"auth_uri": "...",
|
||||
"token_uri": "...",
|
||||
"auth_provider_x509_cert_url": "...",
|
||||
"client_x509_cert_url": "..."
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
You should then be able to connect to your BigQuery datasets.
|
||||
|
||||
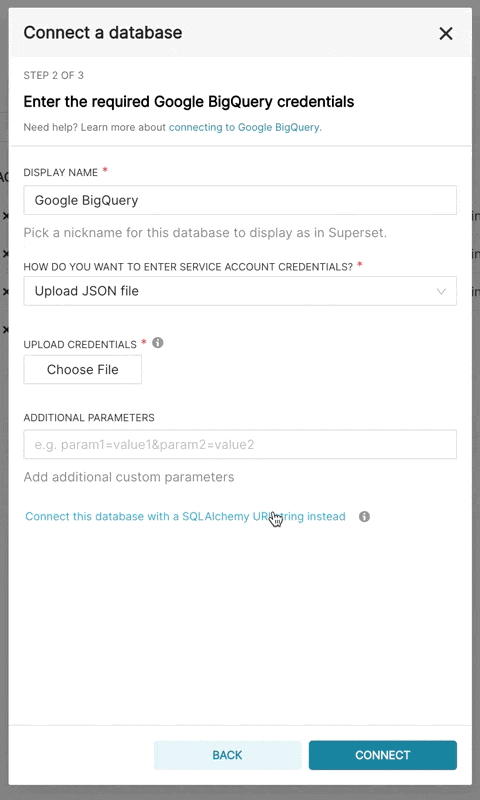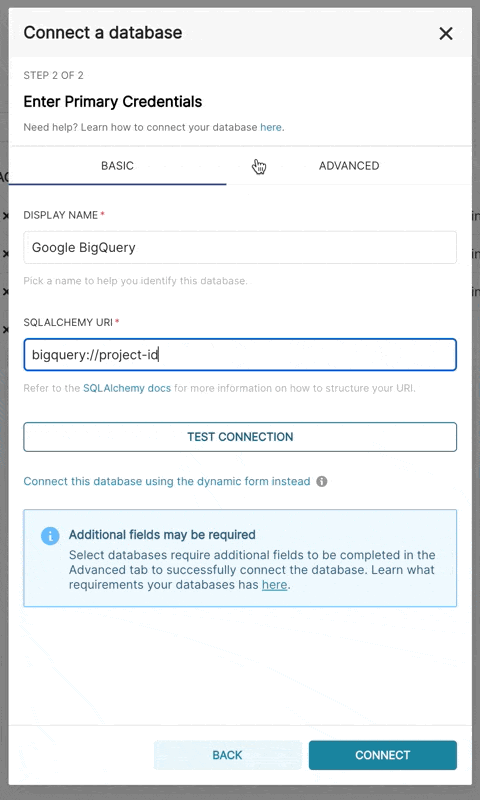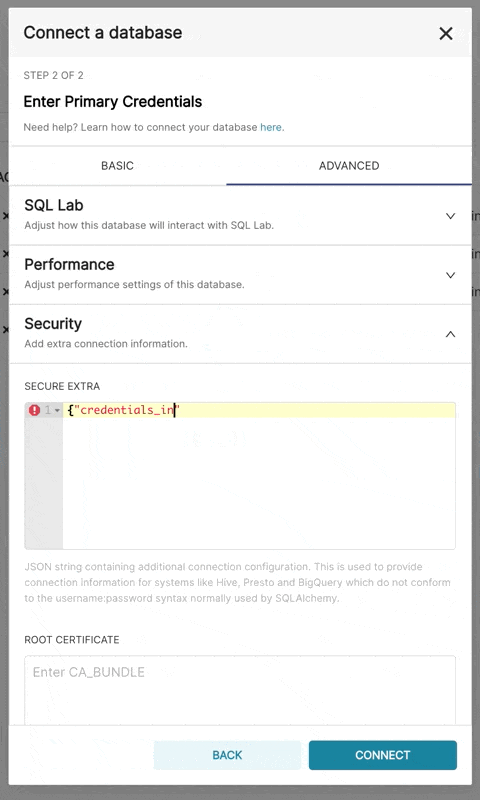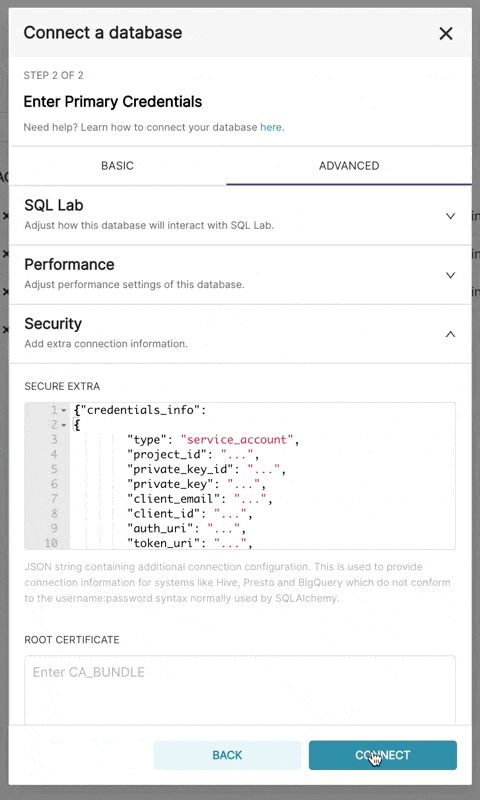
|
||||
|
||||
To be able to upload CSV or Excel files to BigQuery in Superset, you'll need to also add the
|
||||
[pandas_gbq](https://github.com/pydata/pandas-gbq) library.
|
||||
|
||||
Currently, Google BigQuery python sdk is not compatible with `gevent`, due to some dynamic monkeypatching on python core library by `gevent`.
|
||||
So, when you deploy Superset with `gunicorn` server, you have to use worker type except `gevent`.
|
||||
|
|
@ -1,42 +0,0 @@
|
|||
---
|
||||
title: ClickHouse
|
||||
hide_title: true
|
||||
sidebar_position: 15
|
||||
version: 1
|
||||
---
|
||||
|
||||
## ClickHouse
|
||||
|
||||
To use ClickHouse with Superset, you will need to add the following Python library:
|
||||
|
||||
```
|
||||
clickhouse-connect>=0.6.8
|
||||
```
|
||||
|
||||
If running Superset using Docker Compose, add the following to your `./docker/requirements-local.txt` file:
|
||||
|
||||
```
|
||||
clickhouse-connect>=0.6.8
|
||||
```
|
||||
|
||||
The recommended connector library for ClickHouse is
|
||||
[clickhouse-connect](https://github.com/ClickHouse/clickhouse-connect).
|
||||
|
||||
The expected connection string is formatted as follows:
|
||||
|
||||
```
|
||||
clickhousedb://<user>:<password>@<host>:<port>/<database>[?options…]clickhouse://{username}:{password}@{hostname}:{port}/{database}
|
||||
```
|
||||
|
||||
Here's a concrete example of a real connection string:
|
||||
|
||||
```
|
||||
clickhousedb://demo:demo@github.demo.trial.altinity.cloud/default?secure=true
|
||||
```
|
||||
|
||||
If you're using Clickhouse locally on your computer, you can get away with using a http protocol URL that
|
||||
uses the default user without a password (and doesn't encrypt the connection):
|
||||
|
||||
```
|
||||
clickhousedb://localhost/default
|
||||
```
|
||||
|
|
@ -1,17 +0,0 @@
|
|||
---
|
||||
title: CockroachDB
|
||||
hide_title: true
|
||||
sidebar_position: 16
|
||||
version: 1
|
||||
---
|
||||
|
||||
## CockroachDB
|
||||
|
||||
The recommended connector library for CockroachDB is
|
||||
[sqlalchemy-cockroachdb](https://github.com/cockroachdb/sqlalchemy-cockroachdb).
|
||||
|
||||
The expected connection string is formatted as follows:
|
||||
|
||||
```
|
||||
cockroachdb://root@{hostname}:{port}/{database}?sslmode=disable
|
||||
```
|
||||
|
|
@ -1,24 +0,0 @@
|
|||
---
|
||||
title: CrateDB
|
||||
hide_title: true
|
||||
sidebar_position: 36
|
||||
version: 1
|
||||
---
|
||||
|
||||
## CrateDB
|
||||
|
||||
The recommended connector library for CrateDB is
|
||||
[crate](https://pypi.org/project/crate/).
|
||||
You need to install the extras as well for this library.
|
||||
We recommend adding something like the following
|
||||
text to your requirements file:
|
||||
|
||||
```
|
||||
crate[sqlalchemy]==0.26.0
|
||||
```
|
||||
|
||||
The expected connection string is formatted as follows:
|
||||
|
||||
```
|
||||
crate://crate@127.0.0.1:4200
|
||||
```
|
||||
|
|
@ -1,23 +0,0 @@
|
|||
---
|
||||
title: Databend
|
||||
hide_title: true
|
||||
sidebar_position: 39
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Databend
|
||||
|
||||
The recommended connector library for Databend is [databend-sqlalchemy](https://pypi.org/project/databend-sqlalchemy/).
|
||||
Superset has been tested on `databend-sqlalchemy>=0.2.3`.
|
||||
|
||||
The recommended connection string is:
|
||||
|
||||
```
|
||||
databend://{username}:{password}@{host}:{port}/{database_name}
|
||||
```
|
||||
|
||||
Here's a connection string example of Superset connecting to a Databend database:
|
||||
|
||||
```
|
||||
databend://user:password@localhost:8000/default?secure=false
|
||||
```
|
||||
|
|
@ -1,89 +0,0 @@
|
|||
---
|
||||
title: Databricks
|
||||
hide_title: true
|
||||
sidebar_position: 37
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Databricks
|
||||
|
||||
Databricks now offer a native DB API 2.0 driver, `databricks-sql-connector`, that can be used with the `sqlalchemy-databricks` dialect. You can install both with:
|
||||
|
||||
```bash
|
||||
pip install "apache-superset[databricks]"
|
||||
```
|
||||
|
||||
To use the Hive connector you need the following information from your cluster:
|
||||
|
||||
- Server hostname
|
||||
- Port
|
||||
- HTTP path
|
||||
|
||||
These can be found under "Configuration" -> "Advanced Options" -> "JDBC/ODBC".
|
||||
|
||||
You also need an access token from "Settings" -> "User Settings" -> "Access Tokens".
|
||||
|
||||
Once you have all this information, add a database of type "Databricks Native Connector" and use the following SQLAlchemy URI:
|
||||
|
||||
```
|
||||
databricks+connector://token:{access_token}@{server_hostname}:{port}/{database_name}
|
||||
```
|
||||
|
||||
You also need to add the following configuration to "Other" -> "Engine Parameters", with your HTTP path:
|
||||
|
||||
```json
|
||||
{
|
||||
"connect_args": {"http_path": "sql/protocolv1/o/****"}
|
||||
}
|
||||
```
|
||||
|
||||
## Older driver
|
||||
|
||||
Originally Superset used `databricks-dbapi` to connect to Databricks. You might want to try it if you're having problems with the official Databricks connector:
|
||||
|
||||
```bash
|
||||
pip install "databricks-dbapi[sqlalchemy]"
|
||||
```
|
||||
|
||||
There are two ways to connect to Databricks when using `databricks-dbapi`: using a Hive connector or an ODBC connector. Both ways work similarly, but only ODBC can be used to connect to [SQL endpoints](https://docs.databricks.com/sql/admin/sql-endpoints.html).
|
||||
|
||||
### Hive
|
||||
|
||||
To connect to a Hive cluster add a database of type "Databricks Interactive Cluster" in Superset, and use the following SQLAlchemy URI:
|
||||
|
||||
```
|
||||
databricks+pyhive://token:{access_token}@{server_hostname}:{port}/{database_name}
|
||||
```
|
||||
|
||||
You also need to add the following configuration to "Other" -> "Engine Parameters", with your HTTP path:
|
||||
|
||||
```json
|
||||
{"connect_args": {"http_path": "sql/protocolv1/o/****"}}
|
||||
```
|
||||
|
||||
### ODBC
|
||||
|
||||
For ODBC you first need to install the [ODBC drivers for your platform](https://databricks.com/spark/odbc-drivers-download).
|
||||
|
||||
For a regular connection use this as the SQLAlchemy URI after selecting either "Databricks Interactive Cluster" or "Databricks SQL Endpoint" for the database, depending on your use case:
|
||||
|
||||
```
|
||||
databricks+pyodbc://token:{access_token}@{server_hostname}:{port}/{database_name}
|
||||
```
|
||||
|
||||
And for the connection arguments:
|
||||
|
||||
```json
|
||||
{"connect_args": {"http_path": "sql/protocolv1/o/****", "driver_path": "/path/to/odbc/driver"}}
|
||||
```
|
||||
|
||||
The driver path should be:
|
||||
|
||||
- `/Library/simba/spark/lib/libsparkodbc_sbu.dylib` (Mac OS)
|
||||
- `/opt/simba/spark/lib/64/libsparkodbc_sb64.so` (Linux)
|
||||
|
||||
For a connection to a SQL endpoint you need to use the HTTP path from the endpoint:
|
||||
|
||||
```json
|
||||
{"connect_args": {"http_path": "/sql/1.0/endpoints/****", "driver_path": "/path/to/odbc/driver"}}
|
||||
```
|
||||
|
|
@ -1,76 +0,0 @@
|
|||
---
|
||||
title: Using Database Connection UI
|
||||
hide_title: true
|
||||
sidebar_position: 3
|
||||
version: 1
|
||||
---
|
||||
|
||||
Here is the documentation on how to leverage the new DB Connection UI. This will provide admins the ability to enhance the UX for users who want to connect to new databases.
|
||||
|
||||
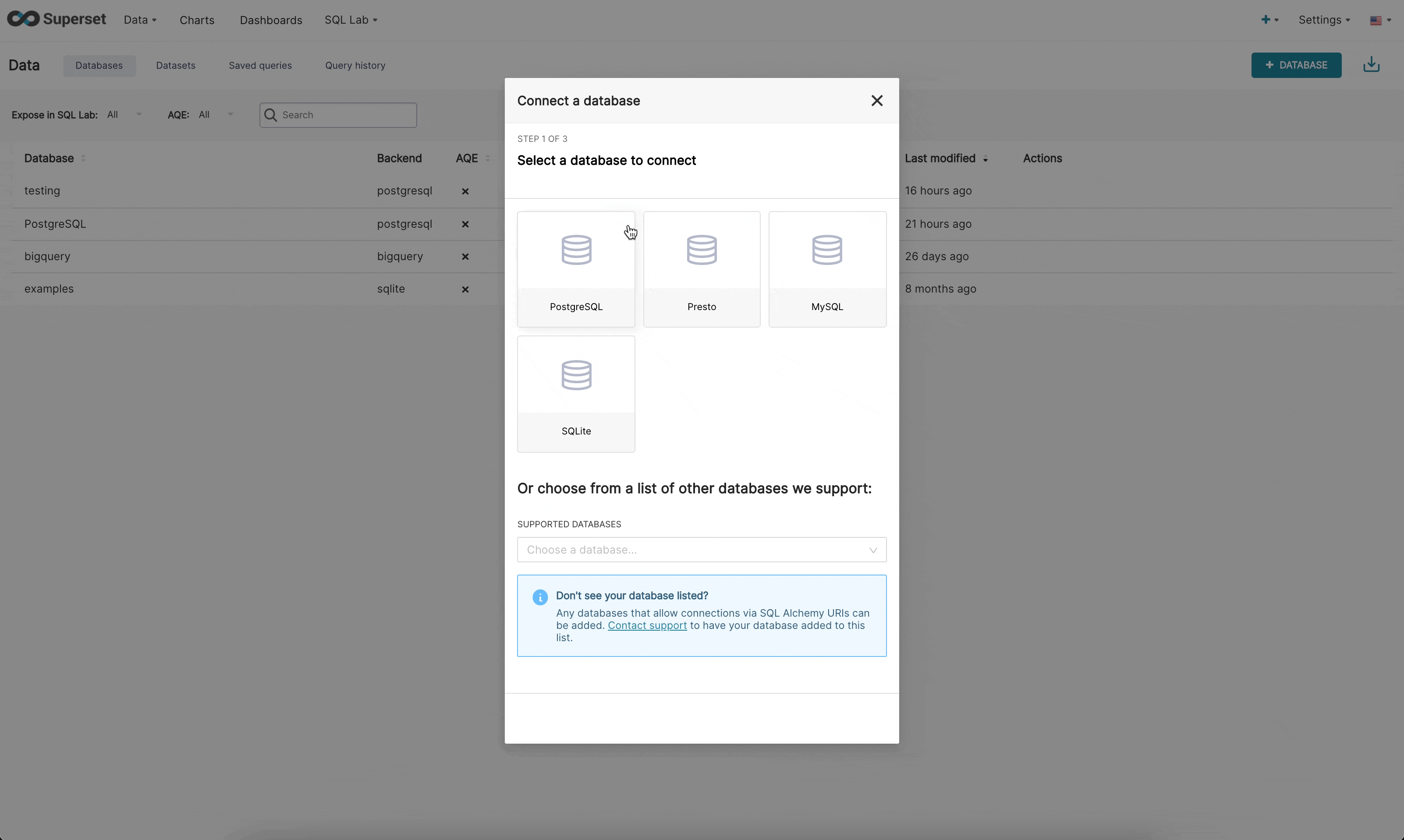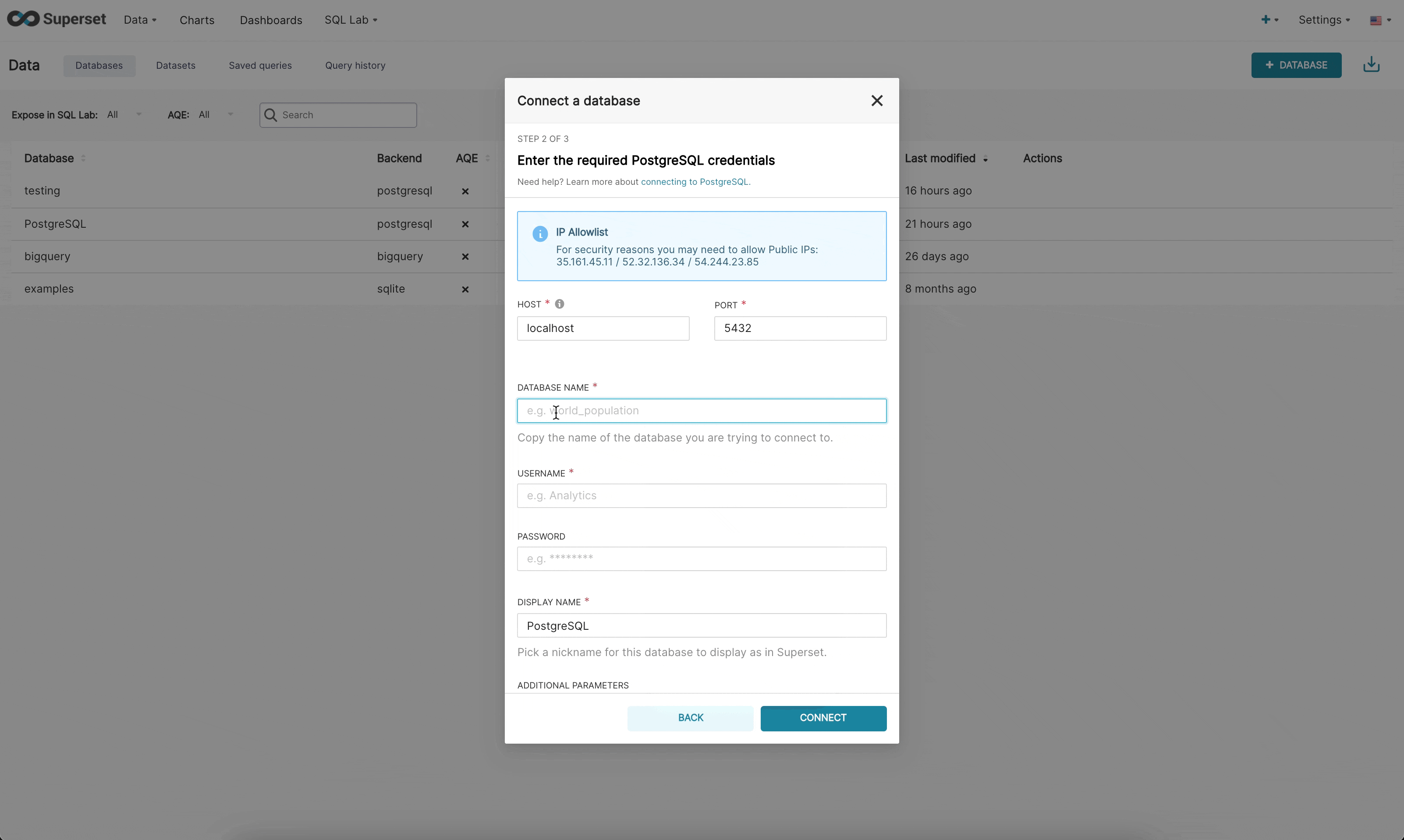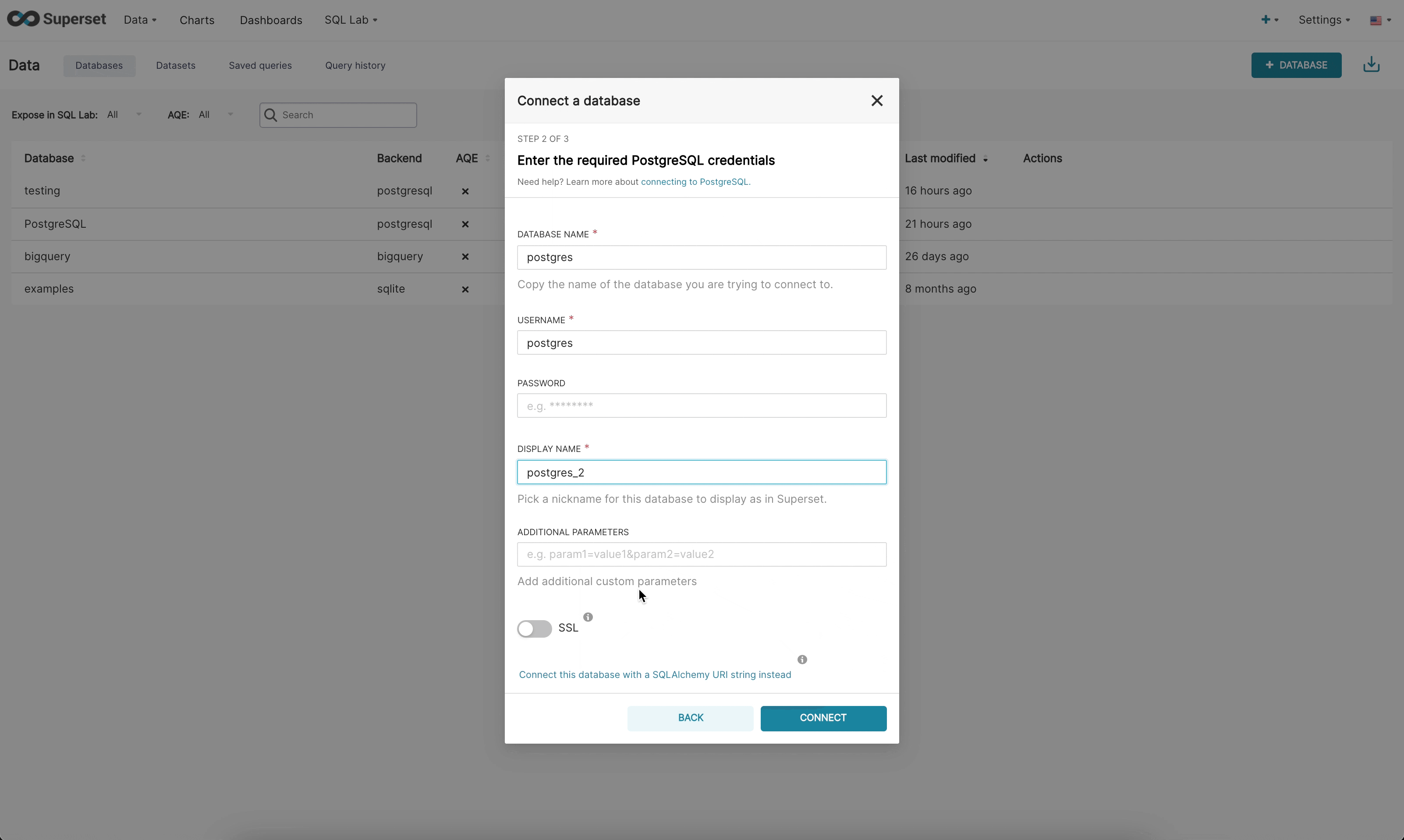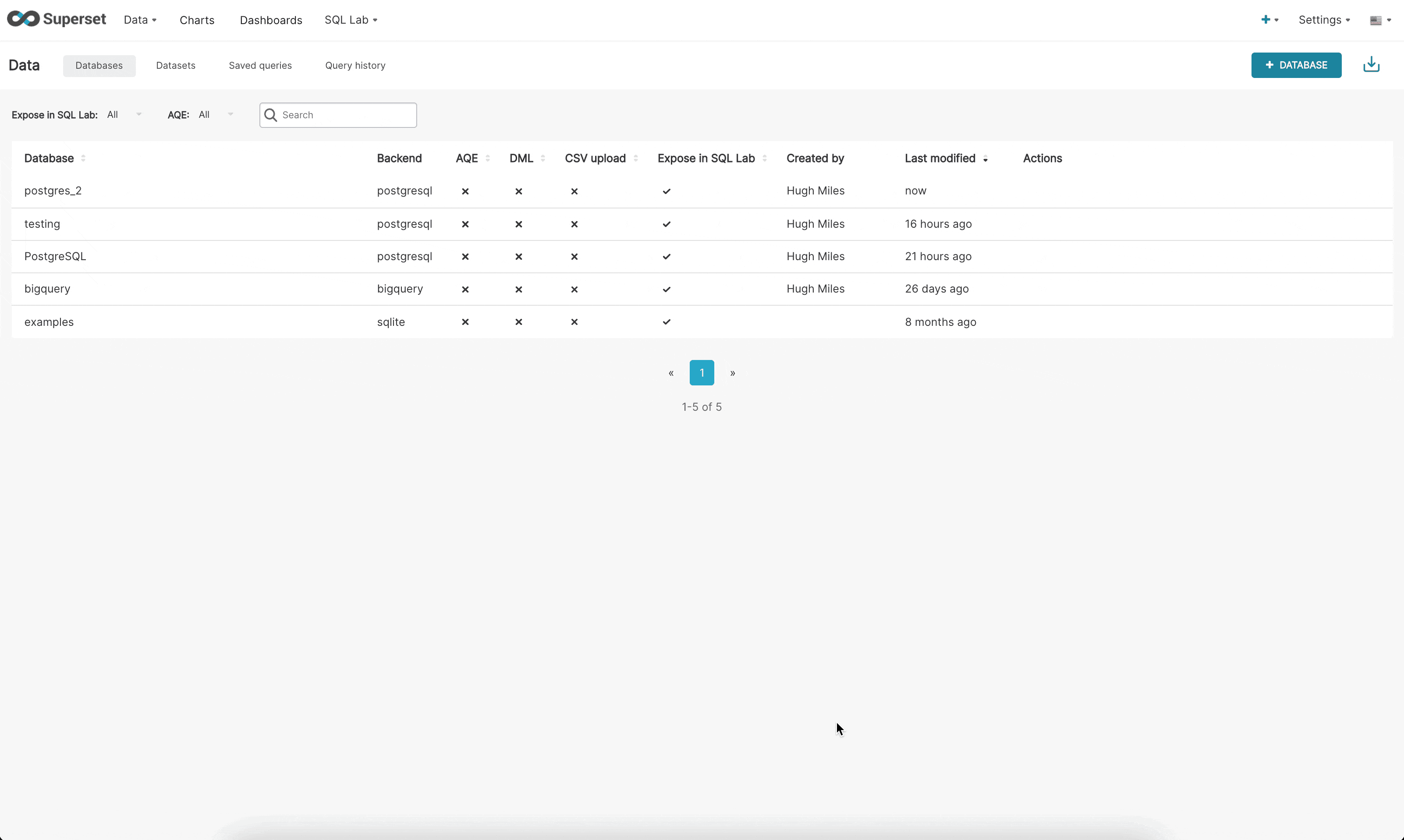
|
||||
|
||||
There are now 3 steps when connecting to a database in the new UI:
|
||||
|
||||
Step 1: First the admin must inform superset what engine they want to connect to. This page is powered by the `/available` endpoint which pulls on the engines currently installed in your environment, so that only supported databases are shown.
|
||||
|
||||
Step 2: Next, the admin is prompted to enter database specific parameters. Depending on whether there is a dynamic form available for that specific engine, the admin will either see the new custom form or the legacy SQLAlchemy form. We currently have built dynamic forms for (Redshift, MySQL, Postgres, and BigQuery). The new form prompts the user for the parameters needed to connect (for example, username, password, host, port, etc.) and provides immediate feedback on errors.
|
||||
|
||||
Step 3: Finally, once the admin has connected to their DB using the dynamic form they have the opportunity to update any optional advanced settings.
|
||||
|
||||
We hope this feature will help eliminate a huge bottleneck for users to get into the application and start crafting datasets.
|
||||
|
||||
### How to setup up preferred database options and images
|
||||
|
||||
We added a new configuration option where the admin can define their preferred databases, in order:
|
||||
|
||||
```python
|
||||
# A list of preferred databases, in order. These databases will be
|
||||
# displayed prominently in the "Add Database" dialog. You should
|
||||
# use the "engine_name" attribute of the corresponding DB engine spec
|
||||
# in `superset/db_engine_specs/`.
|
||||
PREFERRED_DATABASES: list[str] = [
|
||||
"PostgreSQL",
|
||||
"Presto",
|
||||
"MySQL",
|
||||
"SQLite",
|
||||
]
|
||||
```
|
||||
|
||||
For copyright reasons the logos for each database are not distributed with Superset.
|
||||
|
||||
### Setting images
|
||||
|
||||
- To set the images of your preferred database, admins must create a mapping in the `superset_text.yml` file with engine and location of the image. The image can be host locally inside your static/file directory or online (e.g. S3)
|
||||
|
||||
```python
|
||||
DB_IMAGES:
|
||||
postgresql: "path/to/image/postgres.jpg"
|
||||
bigquery: "path/to/s3bucket/bigquery.jpg"
|
||||
snowflake: "path/to/image/snowflake.jpg"
|
||||
```
|
||||
|
||||
### How to add new database engines to available endpoint
|
||||
|
||||
Currently the new modal supports the following databases:
|
||||
|
||||
- Postgres
|
||||
- Redshift
|
||||
- MySQL
|
||||
- BigQuery
|
||||
|
||||
When the user selects a database not in this list they will see the old dialog asking for the SQLAlchemy URI. New databases can be added gradually to the new flow. In order to support the rich configuration a DB engine spec needs to have the following attributes:
|
||||
|
||||
1. `parameters_schema`: a Marshmallow schema defining the parameters needed to configure the database. For Postgres this includes username, password, host, port, etc. ([see](https://github.com/apache/superset/blob/accee507c0819cd0d7bcfb5a3e1199bc81eeebf2/superset/db_engine_specs/base.py#L1309-L1320)).
|
||||
2. `default_driver`: the name of the recommended driver for the DB engine spec. Many SQLAlchemy dialects support multiple drivers, but usually one is the official recommendation. For Postgres we use "psycopg2".
|
||||
3. `sqlalchemy_uri_placeholder`: a string that helps the user in case they want to type the URI directly.
|
||||
4. `encryption_parameters`: parameters used to build the URI when the user opts for an encrypted connection. For Postgres this is `{"sslmode": "require"}`.
|
||||
|
||||
In addition, the DB engine spec must implement these class methods:
|
||||
|
||||
- `build_sqlalchemy_uri(cls, parameters, encrypted_extra)`: this method receives the distinct parameters and builds the URI from them.
|
||||
- `get_parameters_from_uri(cls, uri, encrypted_extra)`: this method does the opposite, extracting the parameters from a given URI.
|
||||
- `validate_parameters(cls, parameters)`: this method is used for `onBlur` validation of the form. It should return a list of `SupersetError` indicating which parameters are missing, and which parameters are definitely incorrect ([example](https://github.com/apache/superset/blob/accee507c0819cd0d7bcfb5a3e1199bc81eeebf2/superset/db_engine_specs/base.py#L1404)).
|
||||
|
||||
For databases like MySQL and Postgres that use the standard format of `engine+driver://user:password@host:port/dbname` all you need to do is add the `BasicParametersMixin` to the DB engine spec, and then define the parameters 2-4 (`parameters_schema` is already present in the mixin).
|
||||
|
||||
For other databases you need to implement these methods yourself. The BigQuery DB engine spec is a good example of how to do that.
|
||||
|
|
@ -1,63 +0,0 @@
|
|||
---
|
||||
title: Adding New Drivers in Docker
|
||||
hide_title: true
|
||||
sidebar_position: 2
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Adding New Database Drivers in Docker
|
||||
|
||||
Superset requires a Python database driver to be installed for each additional type of database you want to connect to.
|
||||
|
||||
In this example, we'll walk through how to install the MySQL connector library. The connector library installation process is the same for all additional libraries.
|
||||
|
||||
### 1. Determine the driver you need
|
||||
|
||||
Consult the [list of database drivers](/docs/databases/installing-database-drivers) and find the PyPI package needed to connect to your database. In this example, we're connecting to a MySQL database, so we'll need the `mysqlclient` connector library.
|
||||
|
||||
### 2. Install the driver in the container
|
||||
|
||||
We need to get the `mysqlclient` library installed into the Superset docker container (it doesn't matter if it's installed on the host machine). We could enter the running container with `docker exec -it <container_name> bash` and run `pip install mysqlclient` there, but that wouldn't persist permanently.
|
||||
|
||||
To address this, the Superset `docker compose` deployment uses the convention of a `requirements-local.txt` file. All packages listed in this file will be installed into the container from PyPI at runtime. This file will be ignored by Git for the purposes of local development.
|
||||
|
||||
Create the file `requirements-local.txt` in a subdirectory called `docker` that exists in the directory with your `docker-compose.yml` or `docker-compose-non-dev.yml` file.
|
||||
|
||||
```
|
||||
# Run from the repo root:
|
||||
touch ./docker/requirements-local.txt
|
||||
```
|
||||
|
||||
Add the driver identified in step above. You can use a text editor or do it from the command line like:
|
||||
|
||||
```
|
||||
echo "mysqlclient" >> ./docker/requirements-local.txt
|
||||
```
|
||||
|
||||
**If you are running a stock (non-customized) Superset image**, you are done. Launch Superset with `docker compose -f docker-compose-non-dev.yml up` and the driver should be present.
|
||||
|
||||
You can check its presence by entering the running container with `docker exec -it <container_name> bash` and running `pip freeze`. The PyPI package should be present in the printed list.
|
||||
|
||||
**If you're running a customized docker image**, rebuild your local image with the new driver baked in:
|
||||
|
||||
```
|
||||
docker compose build --force-rm
|
||||
```
|
||||
|
||||
After the rebuild of the Docker images is complete, relaunch Superset by running `docker compose up`.
|
||||
|
||||
### 3. Connect to MySQL
|
||||
|
||||
Now that you've got a MySQL driver installed in your container, you should be able to connect to your database via the Superset web UI.
|
||||
|
||||
As an admin user, go to Settings -> Data: Database Connections and click the +DATABASE button. From there, follow the steps on the [Using Database Connection UI page](/docs/databases/db-connection-ui).
|
||||
|
||||
Consult the page for your specific database type in the Superset documentation to determine the connection string and any other parameters you need to input. For instance, on the [MySQL page](/docs/databases/mysql), we see that the connection string to a local MySQL database differs depending on whether the setup is running on Linux or Mac.
|
||||
|
||||
Click the “Test Connection” button, which should result in a popup message saying, "Connection looks good!".
|
||||
|
||||
### 4. Troubleshooting
|
||||
|
||||
If the test fails, review your docker logs for error messages. Superset uses SQLAlchemy to connect to databases; to troubleshoot the connection string for your database, you might start Python in the Superset application container or host environment and try to connect directly to the desired database and fetch data. This eliminates Superset for the purposes of isolating the problem.
|
||||
|
||||
Repeat this process for each different type of database you want Superset to be able to connect to.
|
||||
|
|
@ -1,26 +0,0 @@
|
|||
---
|
||||
title: Apache Doris
|
||||
hide_title: true
|
||||
sidebar_position: 5
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Doris
|
||||
|
||||
The [sqlalchemy-doris](https://pypi.org/project/pydoris/) library is the recommended way to connect to Apache Doris through SQLAlchemy.
|
||||
|
||||
You'll need the following setting values to form the connection string:
|
||||
|
||||
- **User**: User Name
|
||||
- **Password**: Password
|
||||
- **Host**: Doris FE Host
|
||||
- **Port**: Doris FE port
|
||||
- **Catalog**: Catalog Name
|
||||
- **Database**: Database Name
|
||||
|
||||
|
||||
Here's what the connection string looks like:
|
||||
|
||||
```
|
||||
doris://<User>:<Password>@<Host>:<Port>/<Catalog>.<Database>
|
||||
```
|
||||
|
|
@ -1,26 +0,0 @@
|
|||
---
|
||||
title: Dremio
|
||||
hide_title: true
|
||||
sidebar_position: 17
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Dremio
|
||||
|
||||
The recommended connector library for Dremio is
|
||||
[sqlalchemy_dremio](https://pypi.org/project/sqlalchemy-dremio/).
|
||||
|
||||
The expected connection string for ODBC (Default port is 31010) is formatted as follows:
|
||||
|
||||
```
|
||||
dremio://{username}:{password}@{host}:{port}/{database_name}/dremio?SSL=1
|
||||
```
|
||||
|
||||
The expected connection string for Arrow Flight (Dremio 4.9.1+. Default port is 32010) is formatted as follows:
|
||||
|
||||
```
|
||||
dremio+flight://{username}:{password}@{host}:{port}/dremio
|
||||
```
|
||||
|
||||
This [blog post by Dremio](https://www.dremio.com/tutorials/dremio-apache-superset/) has some
|
||||
additional helpful instructions on connecting Superset to Dremio.
|
||||
|
|
@ -1,47 +0,0 @@
|
|||
---
|
||||
title: Apache Drill
|
||||
hide_title: true
|
||||
sidebar_position: 6
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Apache Drill
|
||||
|
||||
### SQLAlchemy
|
||||
|
||||
The recommended way to connect to Apache Drill is through SQLAlchemy. You can use the
|
||||
[sqlalchemy-drill](https://github.com/JohnOmernik/sqlalchemy-drill) package.
|
||||
|
||||
Once that is done, you can connect to Drill in two ways, either via the REST interface or by JDBC.
|
||||
If you are connecting via JDBC, you must have the Drill JDBC Driver installed.
|
||||
|
||||
The basic connection string for Drill looks like this:
|
||||
|
||||
```
|
||||
drill+sadrill://<username>:<password>@<host>:<port>/<storage_plugin>?use_ssl=True
|
||||
```
|
||||
|
||||
To connect to Drill running on a local machine running in embedded mode you can use the following
|
||||
connection string:
|
||||
|
||||
```
|
||||
drill+sadrill://localhost:8047/dfs?use_ssl=False
|
||||
```
|
||||
|
||||
### JDBC
|
||||
|
||||
Connecting to Drill through JDBC is more complicated and we recommend following
|
||||
[this tutorial](https://drill.apache.org/docs/using-the-jdbc-driver/).
|
||||
|
||||
The connection string looks like:
|
||||
|
||||
```
|
||||
drill+jdbc://<username>:<password>@<host>:<port>
|
||||
```
|
||||
|
||||
### ODBC
|
||||
|
||||
We recommend reading the
|
||||
[Apache Drill documentation](https://drill.apache.org/docs/installing-the-driver-on-linux/) and read
|
||||
the [GitHub README](https://github.com/JohnOmernik/sqlalchemy-drill#usage-with-odbc) to learn how to
|
||||
work with Drill through ODBC.
|
||||
|
|
@ -1,71 +0,0 @@
|
|||
---
|
||||
title: Apache Druid
|
||||
hide_title: true
|
||||
sidebar_position: 7
|
||||
version: 1
|
||||
---
|
||||
|
||||
import useBaseUrl from "@docusaurus/useBaseUrl";
|
||||
|
||||
## Apache Druid
|
||||
|
||||
A native connector to Druid ships with Superset (behind the `DRUID_IS_ACTIVE` flag) but this is
|
||||
slowly getting deprecated in favor of the SQLAlchemy / DBAPI connector made available in the
|
||||
[pydruid library](https://pythonhosted.org/pydruid/).
|
||||
|
||||
The connection string looks like:
|
||||
|
||||
```
|
||||
druid://<User>:<password>@<Host>:<Port-default-9088>/druid/v2/sql
|
||||
```
|
||||
Here's a breakdown of the key components of this connection string:
|
||||
|
||||
- `User`: username portion of the credentials needed to connect to your database
|
||||
- `Password`: password portion of the credentials needed to connect to your database
|
||||
- `Host`: IP address (or URL) of the host machine that's running your database
|
||||
- `Port`: specific port that's exposed on your host machine where your database is running
|
||||
|
||||
### Customizing Druid Connection
|
||||
|
||||
When adding a connection to Druid, you can customize the connection a few different ways in the
|
||||
**Add Database** form.
|
||||
|
||||
**Custom Certificate**
|
||||
|
||||
You can add certificates in the **Root Certificate** field when configuring the new database
|
||||
connection to Druid:
|
||||
|
||||
<img src={useBaseUrl("/img/root-cert-example.png")} />{" "}
|
||||
|
||||
When using a custom certificate, pydruid will automatically use https scheme.
|
||||
|
||||
**Disable SSL Verification**
|
||||
|
||||
To disable SSL verification, add the following to the **Extras** field:
|
||||
|
||||
```
|
||||
engine_params:
|
||||
{"connect_args":
|
||||
{"scheme": "https", "ssl_verify_cert": false}}
|
||||
```
|
||||
|
||||
### Aggregations
|
||||
|
||||
Common aggregations or Druid metrics can be defined and used in Superset. The first and simpler use
|
||||
case is to use the checkbox matrix exposed in your datasource’s edit view (**Sources -> Druid
|
||||
Datasources -> [your datasource] -> Edit -> [tab] List Druid Column**).
|
||||
|
||||
Clicking the GroupBy and Filterable checkboxes will make the column appear in the related dropdowns
|
||||
while in the Explore view. Checking Count Distinct, Min, Max or Sum will result in creating new
|
||||
metrics that will appear in the **List Druid Metric** tab upon saving the datasource.
|
||||
|
||||
By editing these metrics, you’ll notice that their JSON element corresponds to Druid aggregation
|
||||
definition. You can create your own aggregations manually from the **List Druid Metric** tab
|
||||
following Druid documentation.
|
||||
|
||||
### Post-Aggregations
|
||||
|
||||
Druid supports post aggregation and this works in Superset. All you have to do is create a metric,
|
||||
much like you would create an aggregation manually, but specify `postagg` as a `Metric Type`. You
|
||||
then have to provide a valid json post-aggregation definition (as specified in the Druid docs) in
|
||||
the JSON field.
|
||||
|
|
@ -1,20 +0,0 @@
|
|||
---
|
||||
title: Amazon DynamoDB
|
||||
hide_title: true
|
||||
sidebar_position: 4
|
||||
version: 1
|
||||
---
|
||||
|
||||
## AWS DynamoDB
|
||||
|
||||
### PyDynamoDB
|
||||
|
||||
[PyDynamoDB](https://pypi.org/project/PyDynamoDB/) is a Python DB API 2.0 (PEP 249) client for Amazon DynamoDB.
|
||||
|
||||
The connection string for Amazon DynamoDB is as follows:
|
||||
|
||||
```
|
||||
dynamodb://{aws_access_key_id}:{aws_secret_access_key}@dynamodb.{region_name}.amazonaws.com:443?connector=superset
|
||||
```
|
||||
|
||||
To get more documentation, please visit: [PyDynamoDB WIKI](https://github.com/passren/PyDynamoDB/wiki/5.-Superset).
|
||||
|
|
@ -1,76 +0,0 @@
|
|||
---
|
||||
title: Elasticsearch
|
||||
hide_title: true
|
||||
sidebar_position: 18
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Elasticsearch
|
||||
|
||||
The recommended connector library for Elasticsearch is
|
||||
[elasticsearch-dbapi](https://github.com/preset-io/elasticsearch-dbapi).
|
||||
|
||||
The connection string for Elasticsearch looks like this:
|
||||
|
||||
```
|
||||
elasticsearch+http://{user}:{password}@{host}:9200/
|
||||
```
|
||||
|
||||
**Using HTTPS**
|
||||
|
||||
```
|
||||
elasticsearch+https://{user}:{password}@{host}:9200/
|
||||
```
|
||||
|
||||
Elasticsearch as a default limit of 10000 rows, so you can increase this limit on your cluster or
|
||||
set Superset’s row limit on config
|
||||
|
||||
```
|
||||
ROW_LIMIT = 10000
|
||||
```
|
||||
|
||||
You can query multiple indices on SQL Lab for example
|
||||
|
||||
```
|
||||
SELECT timestamp, agent FROM "logstash"
|
||||
```
|
||||
|
||||
But, to use visualizations for multiple indices you need to create an alias index on your cluster
|
||||
|
||||
```
|
||||
POST /_aliases
|
||||
{
|
||||
"actions" : [
|
||||
{ "add" : { "index" : "logstash-**", "alias" : "logstash_all" } }
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
Then register your table with the alias name logstash_all
|
||||
|
||||
**Time zone**
|
||||
|
||||
By default, Superset uses UTC time zone for elasticsearch query. If you need to specify a time zone,
|
||||
please edit your Database and enter the settings of your specified time zone in the Other > ENGINE PARAMETERS:
|
||||
|
||||
```
|
||||
{
|
||||
"connect_args": {
|
||||
"time_zone": "Asia/Shanghai"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Another issue to note about the time zone problem is that before elasticsearch7.8, if you want to convert a string into a `DATETIME` object,
|
||||
you need to use the `CAST` function,but this function does not support our `time_zone` setting. So it is recommended to upgrade to the version after elasticsearch7.8.
|
||||
After elasticsearch7.8, you can use the `DATETIME_PARSE` function to solve this problem.
|
||||
The DATETIME_PARSE function is to support our `time_zone` setting, and here you need to fill in your elasticsearch version number in the Other > VERSION setting.
|
||||
the superset will use the `DATETIME_PARSE` function for conversion.
|
||||
|
||||
**Disable SSL Verification**
|
||||
|
||||
To disable SSL verification, add the following to the **SQLALCHEMY URI** field:
|
||||
|
||||
```
|
||||
elasticsearch+https://{user}:{password}@{host}:9200/?verify_certs=False
|
||||
```
|
||||
|
|
@ -1,17 +0,0 @@
|
|||
---
|
||||
title: Exasol
|
||||
hide_title: true
|
||||
sidebar_position: 19
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Exasol
|
||||
|
||||
The recommended connector library for Exasol is
|
||||
[sqlalchemy-exasol](https://github.com/exasol/sqlalchemy-exasol).
|
||||
|
||||
The connection string for Exasol looks like this:
|
||||
|
||||
```
|
||||
exa+pyodbc://{username}:{password}@{hostname}:{port}/my_schema?CONNECTIONLCALL=en_US.UTF-8&driver=EXAODBC
|
||||
```
|
||||
|
|
@ -1,69 +0,0 @@
|
|||
---
|
||||
title: Extra Database Settings
|
||||
hide_title: true
|
||||
sidebar_position: 40
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Extra Database Settings
|
||||
|
||||
### Deeper SQLAlchemy Integration
|
||||
|
||||
It is possible to tweak the database connection information using the parameters exposed by
|
||||
SQLAlchemy. In the **Database edit** view, you can edit the **Extra** field as a JSON blob.
|
||||
|
||||
This JSON string contains extra configuration elements. The `engine_params` object gets unpacked
|
||||
into the `sqlalchemy.create_engine` call, while the `metadata_params` get unpacked into the
|
||||
`sqlalchemy.MetaData` call. Refer to the SQLAlchemy docs for more information.
|
||||
|
||||
### Schemas
|
||||
|
||||
Databases like Postgres and Redshift use the **schema** as the logical entity on top of the
|
||||
**database**. For Superset to connect to a specific schema, you can set the **schema** parameter in
|
||||
the **Edit Tables** form (Sources > Tables > Edit record).
|
||||
|
||||
### External Password Store for SQLAlchemy Connections
|
||||
|
||||
Superset can be configured to use an external store for database passwords. This is useful if you a
|
||||
running a custom secret distribution framework and do not wish to store secrets in Superset’s meta
|
||||
database.
|
||||
|
||||
Example: Write a function that takes a single argument of type `sqla.engine.url` and returns the
|
||||
password for the given connection string. Then set `SQLALCHEMY_CUSTOM_PASSWORD_STORE` in your config
|
||||
file to point to that function.
|
||||
|
||||
```python
|
||||
def example_lookup_password(url):
|
||||
secret = <<get password from external framework>>
|
||||
return 'secret'
|
||||
|
||||
SQLALCHEMY_CUSTOM_PASSWORD_STORE = example_lookup_password
|
||||
```
|
||||
|
||||
A common pattern is to use environment variables to make secrets available.
|
||||
`SQLALCHEMY_CUSTOM_PASSWORD_STORE` can also be used for that purpose.
|
||||
|
||||
```python
|
||||
def example_password_as_env_var(url):
|
||||
# assuming the uri looks like
|
||||
# mysql://localhost?superset_user:{SUPERSET_PASSWORD}
|
||||
return url.password.format(**os.environ)
|
||||
|
||||
SQLALCHEMY_CUSTOM_PASSWORD_STORE = example_password_as_env_var
|
||||
```
|
||||
|
||||
### SSL Access to Databases
|
||||
|
||||
You can use the `Extra` field in the **Edit Databases** form to configure SSL:
|
||||
|
||||
```JSON
|
||||
{
|
||||
"metadata_params": {},
|
||||
"engine_params": {
|
||||
"connect_args":{
|
||||
"sslmode":"require",
|
||||
"sslrootcert": "/path/to/my/pem"
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
Some files were not shown because too many files have changed in this diff Show More
Loading…
Reference in New Issue