feat: Upgrade documentation V2 (#17411)
* setup docusaurus
* rename
* add introduction content
* chore(docsV2): move content from docs to docsV2 (#17714)
* add FAQs and contribution pages
* chore: add api, security, and roadmap pages, include swaggerui in dependency for api page
* chore: move api page header below imports
* chore: change API page info alert to use built in Infima class instead of custom class
Co-authored-by: Corbin Robb <corbin@Corbins-MacBook-Pro.local>
* chore(docs-v2): moving more markdown content to new documentation site (#17736)
* chore: move markdown content and images for docs installation directory to docs-v2
* chore: move docs miscellaneous directory content to docs-v2
* chore(docs-v2): move over connecting to databases content and rename some files to .mdx
Co-authored-by: Corbin Robb <corbin@Corbins-MacBook-Pro.local>
* Update styling and logo (#17990)
* update styling
* update colors
* chore(docs-v2): remove blog and tutorial and update some styling (#17929)
* add superset logo and favicon, change styles to better match current docs, add prettierrc
* change file types to mdx
* Add simple superset dark mode freindly logo
* clean up default pages - blog and tutorial docs
Co-authored-by: Corbin Robb <corbin@Corbins-MacBook-Pro.local>
* Chore: moving charts and dashboard to docusaurus (#18036)
* add contributing add creating charts and dashboards
* delete extra images
* update rat-excludes
* Port homepage (#18115)
* Port community page (#18128)
* chore: add seo redirects for Docs v@ (#18092)
* fix: handle null values in time-series table (#18039)
* cleanup column_type_mappings (#17569)
Signed-off-by: Đặng Minh Dũng <dungdm93@live.com>
* important change to MakeFile (#18037)
* Update superset-e2e.yml (#18041)
* Revert "Update superset-e2e.yml (#18041)" (#18051)
This reverts commit b5652739c9.
* feat: Trino Authentications (#17593)
* feat: support Trino Authentications
Signed-off-by: Đặng Minh Dũng <dungdm93@live.com>
* docs: Trino Authentications
Signed-off-by: Đặng Minh Dũng <dungdm93@live.com>
* chore(supeset.utils.core): move all database utils to database utils module (#18058)
* chore(plugin-chart-echarts): add types to controls (#18059)
* fix(generator): more cleanup to plugin framework (#18027)
* fix(generator): more cleanup to plugin framework
* fix typo and package name
* add docs
* fix typo
* Update superset-frontend/webpack.config.js
Co-authored-by: Kamil Gabryjelski <kamil.gabryjelski@gmail.com>
* fix generator reference
* add steps to tutorial and fix package version
* refine docs/readme
Co-authored-by: Kamil Gabryjelski <kamil.gabryjelski@gmail.com>
* feat(advanced analytics): support groupby in resample (#18045)
* fix(dashboard): scope of nativefilter not update (#18048)
* fix(generator): add lockfile and fix styling issues (#18073)
* fix(generator): add lockfile and fix styling issues
* fix margins and remove redundant scroll
* update tutorial
* refactor(sql_lab): SQL Lab Persistent Saved State (#17771)
* a lot of console logs
* testing
* test
* added saved_query to remoteId
* created useEffect so that title properly changes in modal
* Update superset-frontend/src/SqlLab/actions/sqlLab.js
Co-authored-by: Lyndsi Kay Williams <55605634+lyndsiWilliams@users.noreply.github.com>
Co-authored-by: Lyndsi Kay Williams <55605634+lyndsiWilliams@users.noreply.github.com>
* refactor(example_data): replace the way the birth_names data is loaded to DB (#18060)
* refactor: replace the way the birth_names data is loaded to DB
* fix failed unit test
* fix failed unit test
* fix failed tests
* fix pass wrong flag of support datetime type
* remove unused fixture
* feat: add chart description in info tooltip (#17207)
* feat: add chart list description
* fix: text overflow
* fix: text-overflow with line-height
* Correction of proper names format in README (#18087)
* chore: added SEO routes
* fix can't use examples helpers on non app context based environment (#18086)
* chore: split CLI into multiple files (#18082)
* chore: split CLI into multiple files
* Update tests
* Who fixes the fixtures?
* Add subcommands dynamically
* Rebase
* fix misspelling (#18097)
* refactor: sqleditorleftbar to functional (#17807)
* Working on converting sqleditorleftbar to functional component
* Creating draft PR to address bug
* Still working on solving re rendering bug
* infinite rerender fix
* Creating draft PR to address bug
* Cleaning up in preparation for push
* Made changes suggested by Elizabeth
* Fixed issues as per Lindsey's comment
Co-authored-by: Arash <arash.afghahi@gmail.com>
* fix rat excludes and headers
* fix(docs): fix path of image for "Create New Chart" (#18089)
* Migrate Checkbox story to tsx - see #18100 (#18101)
Looks good!
* refactor: migrate RowCountLabel to TypeScript & added story (#18105)
* enable superbook for explore component
* migrate RowCountLabel to TypeScript
* add storybook for RowCountLabel
* fix: logging warning on dataframe (don't use python's warnings) (#18111)
* fix: logging warning on dataframe (don't use python's warnings)
* lint
* update changelog and updating for 1.4.0 (#18083)
* feat: Adds a key-value endpoint to store charts form data (#17882)
* feat: Adds a key-value endpoint to store charts form data
* Fixes linting problems
* Removes the query_params from the endpoints
* Refactors the commands
* Removes unused imports
* Changes the parameters to use dataclass
* Adds more access tests
* Gets the first dataset while testing
* Adds unit tests for the check_access function
* Changes the can_access check
* Always check for dataset access
* fix(explore): fix chart embed code modal glitch (#17843)
* feat(plugin-chart-echarts): support non-timeseries x-axis (#17917)
* feat(plugin-chart-echarts): support non-timeseries x-axis
* fix tests
* change formula return type from Date to number
* add x_axis test coverage
* rename func and improve coverage
* add x-axis control to bar chart
* remove redundant console.log
* fix description
* make x-axis control mandatory
* 🙃
* fix x-axis formatter
* fix showValues
* fix implicit rDTTM_ALIAS references in postProcessing
* replace TIME_COLUMN with DTTM_ALIAS
* fix remaining implicit indexes
* fix: Disable filtering on wide result sets (#18021)
* fix: handle null values in time-series table (#18039)
* cleanup column_type_mappings (#17569)
Signed-off-by: Đặng Minh Dũng <dungdm93@live.com>
* important change to MakeFile (#18037)
* add missing is_timeseries to pivot op
Co-authored-by: Erik Ritter <erik.ritter@airbnb.com>
Co-authored-by: Grace Guo <grace.guo@airbnb.com>
Co-authored-by: Đặng Minh Dũng <dungdm93@live.com>
Co-authored-by: AAfghahi <48933336+AAfghahi@users.noreply.github.com>
* feat(country-map): added new countries in country-chart-map (#18081)
* chore: migrating storybook jsx to typescript #18100 (#18133)
* Migrating storybook jsx to typescript #18100
* Migrating storybook jsx to typescript
Co-authored-by: Jayakrishnan Karolil <jayakrishnan.karolil@nielsen.com>
* feat(annotation): add toast feedback to annotation templates (#18116)
* feat(dashboard): add toast feedback to dashboard actions (#18114)
* feat(explore): more toast feedback on user actions in Explore (#18108)
* feat(explore): add toasts feedback when user copies chart url
* Show toast message when updating chart properties
* Change toast type to success when saving chart
* Use success toast from props
* Fix tests
* Use withToasts instead of dispatch
* Use PropertiesModalProps instead of any
* Docs: fix typo (#18125)
* fix: undefined error when adding extra sequential color scheme (#18152)
* feat: allow assets to be managed externally (#18093)
* feat: allow assets to be managed externally
* Use server_default
* chore: use pkg_resources for cleaner config (#18130)
* refactor: Moves the Explore form_data endpoint (#18151)
* refactor: Moves the Explore form_data endpoint
* Removes unused imports
* Fixes openapi schema error
* Fixes typo
* Renames and UPDATING.md
Co-authored-by: Grace Guo <grace.guo@airbnb.com>
Co-authored-by: Đặng Minh Dũng <dungdm93@live.com>
Co-authored-by: AAfghahi <48933336+AAfghahi@users.noreply.github.com>
Co-authored-by: Hugh A. Miles II <hughmil3s@gmail.com>
Co-authored-by: ofekisr <35701650+ofekisr@users.noreply.github.com>
Co-authored-by: Ville Brofeldt <33317356+villebro@users.noreply.github.com>
Co-authored-by: Kamil Gabryjelski <kamil.gabryjelski@gmail.com>
Co-authored-by: Yongjie Zhao <yongjie.zhao@gmail.com>
Co-authored-by: Stephen Liu <750188453@qq.com>
Co-authored-by: Lyndsi Kay Williams <55605634+lyndsiWilliams@users.noreply.github.com>
Co-authored-by: Adam Dobrawy <ad-m@users.noreply.github.com>
Co-authored-by: Beto Dealmeida <roberto@dealmeida.net>
Co-authored-by: Emily Wu <86927881+em0227@users.noreply.github.com>
Co-authored-by: Josue Lugaro <82119536+JosueLugaro@users.noreply.github.com>
Co-authored-by: Arash <arash.afghahi@gmail.com>
Co-authored-by: Ville Brofeldt <ville.v.brofeldt@gmail.com>
Co-authored-by: Daniel Vaz Gaspar <danielvazgaspar@gmail.com>
Co-authored-by: Elizabeth Thompson <eschutho@gmail.com>
Co-authored-by: Michael S. Molina <70410625+michael-s-molina@users.noreply.github.com>
Co-authored-by: Erik Ritter <erik.ritter@airbnb.com>
Co-authored-by: Hammad-Raza <hammadraza42@hotmail.com>
Co-authored-by: jayakrishnankk <kk.jayakrishnan@gmail.com>
Co-authored-by: Jayakrishnan Karolil <jayakrishnan.karolil@nielsen.com>
Co-authored-by: Farid Rener <proteusvacuum@users.noreply.github.com>
* remove unneeded requirement
Co-authored-by: Corbin Robb <31329271+corbinrobb@users.noreply.github.com>
Co-authored-by: Corbin Robb <corbin@Corbins-MacBook-Pro.local>
Co-authored-by: Daniel W <61300812+The-hyphen-user@users.noreply.github.com>
Co-authored-by: Geido <60598000+geido@users.noreply.github.com>
Co-authored-by: Srini Kadamati <skadamat@gmail.com>
Co-authored-by: Grace Guo <grace.guo@airbnb.com>
Co-authored-by: Đặng Minh Dũng <dungdm93@live.com>
Co-authored-by: AAfghahi <48933336+AAfghahi@users.noreply.github.com>
Co-authored-by: ofekisr <35701650+ofekisr@users.noreply.github.com>
Co-authored-by: Ville Brofeldt <33317356+villebro@users.noreply.github.com>
Co-authored-by: Kamil Gabryjelski <kamil.gabryjelski@gmail.com>
Co-authored-by: Yongjie Zhao <yongjie.zhao@gmail.com>
Co-authored-by: Stephen Liu <750188453@qq.com>
Co-authored-by: Lyndsi Kay Williams <55605634+lyndsiWilliams@users.noreply.github.com>
Co-authored-by: Adam Dobrawy <ad-m@users.noreply.github.com>
Co-authored-by: Beto Dealmeida <roberto@dealmeida.net>
Co-authored-by: Emily Wu <86927881+em0227@users.noreply.github.com>
Co-authored-by: Josue Lugaro <82119536+JosueLugaro@users.noreply.github.com>
Co-authored-by: Arash <arash.afghahi@gmail.com>
Co-authored-by: Ville Brofeldt <ville.v.brofeldt@gmail.com>
Co-authored-by: Daniel Vaz Gaspar <danielvazgaspar@gmail.com>
Co-authored-by: Elizabeth Thompson <eschutho@gmail.com>
Co-authored-by: Michael S. Molina <70410625+michael-s-molina@users.noreply.github.com>
Co-authored-by: Erik Ritter <erik.ritter@airbnb.com>
Co-authored-by: Hammad-Raza <hammadraza42@hotmail.com>
Co-authored-by: jayakrishnankk <kk.jayakrishnan@gmail.com>
Co-authored-by: Jayakrishnan Karolil <jayakrishnan.karolil@nielsen.com>
Co-authored-by: Farid Rener <proteusvacuum@users.noreply.github.com>
|
|
@ -35,8 +35,9 @@ apache_superset.egg-info
|
|||
.*csv
|
||||
# Generated doc files
|
||||
env/*
|
||||
docs/README.md
|
||||
docs/.htaccess*
|
||||
docs-v2/.htaccess*
|
||||
.nojekyll
|
||||
_build/*
|
||||
_static/*
|
||||
.buildinfo
|
||||
|
|
|
|||
|
|
@ -0,0 +1,20 @@
|
|||
# Dependencies
|
||||
/node_modules
|
||||
|
||||
# Production
|
||||
/build
|
||||
|
||||
# Generated files
|
||||
.docusaurus
|
||||
.cache-loader
|
||||
|
||||
# Misc
|
||||
.DS_Store
|
||||
.env.local
|
||||
.env.development.local
|
||||
.env.test.local
|
||||
.env.production.local
|
||||
|
||||
npm-debug.log*
|
||||
yarn-debug.log*
|
||||
yarn-error.log*
|
||||
|
|
@ -0,0 +1,5 @@
|
|||
{
|
||||
"singleQuote": true,
|
||||
"trailingComma": "all",
|
||||
"arrowParens": "avoid"
|
||||
}
|
||||
|
|
@ -0,0 +1,52 @@
|
|||
<!--
|
||||
Licensed to the Apache Software Foundation (ASF) under one
|
||||
or more contributor license agreements. See the NOTICE file
|
||||
distributed with this work for additional information
|
||||
regarding copyright ownership. The ASF licenses this file
|
||||
to you under the Apache License, Version 2.0 (the
|
||||
"License"); you may not use this file except in compliance
|
||||
with the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing,
|
||||
software distributed under the License is distributed on an
|
||||
"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
|
||||
KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations
|
||||
under the License.
|
||||
-->
|
||||
|
||||
# Website
|
||||
|
||||
This website is built using [Docusaurus 2](https://docusaurus.io/), a modern static website generator.
|
||||
|
||||
### Installation
|
||||
|
||||
```
|
||||
$ yarn
|
||||
```
|
||||
|
||||
### Local Development
|
||||
|
||||
```
|
||||
$ yarn start
|
||||
```
|
||||
|
||||
This command starts a local development server and opens up a browser window. Most changes are reflected live without having to restart the server.
|
||||
|
||||
### Build
|
||||
|
||||
```
|
||||
$ yarn build
|
||||
```
|
||||
|
||||
This command generates static content into the `build` directory and can be served using any static contents hosting service.
|
||||
|
||||
### Deployment
|
||||
|
||||
```
|
||||
$ GIT_USER=<Your GitHub username> USE_SSH=true yarn deploy
|
||||
```
|
||||
|
||||
If you are using GitHub pages for hosting, this command is a convenient way to build the website and push to the `gh-pages` branch.
|
||||
|
|
@ -0,0 +1,22 @@
|
|||
/**
|
||||
* Licensed to the Apache Software Foundation (ASF) under one
|
||||
* or more contributor license agreements. See the NOTICE file
|
||||
* distributed with this work for additional information
|
||||
* regarding copyright ownership. The ASF licenses this file
|
||||
* to you under the Apache License, Version 2.0 (the
|
||||
* "License"); you may not use this file except in compliance
|
||||
* with the License. You may obtain a copy of the License at
|
||||
*
|
||||
* http://www.apache.org/licenses/LICENSE-2.0
|
||||
*
|
||||
* Unless required by applicable law or agreed to in writing,
|
||||
* software distributed under the License is distributed on an
|
||||
* "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
|
||||
* KIND, either express or implied. See the License for the
|
||||
* specific language governing permissions and limitations
|
||||
* under the License.
|
||||
*/
|
||||
|
||||
module.exports = {
|
||||
presets: [require.resolve('@docusaurus/core/lib/babel/preset')],
|
||||
};
|
||||
|
|
@ -0,0 +1,4 @@
|
|||
{
|
||||
"label": "Contributing",
|
||||
"position": 6
|
||||
}
|
||||
|
|
@ -0,0 +1,21 @@
|
|||
---
|
||||
name: General Resources
|
||||
menu: Contributing
|
||||
route: /docs/contributing/contribution-guidelines
|
||||
index: 1
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Contributing to Superset
|
||||
|
||||
Superset is an [Apache Software foundation](https://www.apache.org/theapacheway/index.html) project.
|
||||
The core contributors (or committers) to Superset communicate primarily in the following channels (all of
|
||||
which you can join):
|
||||
|
||||
- [Mailing list](https://lists.apache.org/list.html?dev@superset.apache.org)
|
||||
- [Apache Superset Slack community](https://join.slack.com/t/apache-superset/shared_invite/zt-uxbh5g36-AISUtHbzOXcu0BIj7kgUaw)
|
||||
- [Github issues and PR's](https://github.com/apache/superset/issues)
|
||||
|
||||
More references:
|
||||
- [Comprehensive Tutorial for Contributing Code to Apache Superset](https://preset.io/blog/tutorial-contributing-code-to-apache-superset/)
|
||||
- [CONTRIBUTING Guide on Github](https://github.com/apache/superset/blob/master/CONTRIBUTING.md)
|
||||
|
|
@ -0,0 +1,57 @@
|
|||
---
|
||||
title: Conventions and Typing
|
||||
hide_title: true
|
||||
sidebar_position: 7
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Conventions
|
||||
|
||||
### Python
|
||||
|
||||
Parameters in the `config.py` (which are accessible via the Flask app.config dictionary) are assumed to always be defined and thus should be accessed directly via,
|
||||
|
||||
```python
|
||||
blueprints = app.config["BLUEPRINTS"]
|
||||
```
|
||||
|
||||
rather than,
|
||||
|
||||
```python
|
||||
blueprints = app.config.get("BLUEPRINTS")
|
||||
```
|
||||
|
||||
or similar as the later will cause typing issues. The former is of type `List[Callable]` whereas the later is of type `Optional[List[Callable]]`.
|
||||
|
||||
## Typing
|
||||
|
||||
### Python
|
||||
|
||||
To ensure clarity, consistency, all readability, _all_ new functions should use
|
||||
[type hints](https://docs.python.org/3/library/typing.html) and include a
|
||||
docstring.
|
||||
|
||||
Note per [PEP-484](https://www.python.org/dev/peps/pep-0484/#exceptions) no
|
||||
syntax for listing explicitly raised exceptions is proposed and thus the
|
||||
recommendation is to put this information in a docstring, i.e.,
|
||||
|
||||
```python
|
||||
import math
|
||||
from typing import Union
|
||||
|
||||
|
||||
def sqrt(x: Union[float, int]) -> Union[float, int]:
|
||||
"""
|
||||
Return the square root of x.
|
||||
|
||||
:param x: A number
|
||||
:returns: The square root of the given number
|
||||
:raises ValueError: If the number is negative
|
||||
"""
|
||||
|
||||
return math.sqrt(x)
|
||||
```
|
||||
|
||||
### TypeScript
|
||||
|
||||
TypeScript is fully supported and is the recommended language for writing all new frontend components. When modifying existing functions/components, migrating to TypeScript is appreciated, but not required. Examples of migrating functions/components to TypeScript can be found in [#9162](https://github.com/apache/superset/pull/9162) and [#9180](https://github.com/apache/superset/pull/9180).
|
||||
|
|
@ -0,0 +1,61 @@
|
|||
---
|
||||
title: Pre-commit Hooks and Linting
|
||||
hide_title: true
|
||||
sidebar_position: 6
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Git Hooks
|
||||
|
||||
Superset uses Git pre-commit hooks courtesy of [pre-commit](https://pre-commit.com/). To install run the following:
|
||||
|
||||
```bash
|
||||
pip3 install -r requirements/integration.txt
|
||||
pre-commit install
|
||||
```
|
||||
|
||||
A series of checks will now run when you make a git commit.
|
||||
|
||||
Alternatively it is possible to run pre-commit via tox:
|
||||
|
||||
```bash
|
||||
tox -e pre-commit
|
||||
```
|
||||
|
||||
Or by running pre-commit manually:
|
||||
|
||||
```bash
|
||||
pre-commit run --all-files
|
||||
```
|
||||
|
||||
## Linting
|
||||
|
||||
### Python
|
||||
|
||||
We use [Pylint](https://pylint.org/) for linting which can be invoked via:
|
||||
|
||||
```bash
|
||||
# for python
|
||||
tox -e pylint
|
||||
```
|
||||
|
||||
In terms of best practices please advoid blanket disablement of Pylint messages globally (via `.pylintrc`) or top-level within the file header, albeit there being a few exceptions. Disablement should occur inline as it prevents masking issues and provides context as to why said message is disabled.
|
||||
|
||||
Additionally the Python code is auto-formatted using [Black](https://github.com/python/black) which
|
||||
is configured as a pre-commit hook. There are also numerous [editor integrations](https://black.readthedocs.io/en/stable/editor_integration.html)
|
||||
|
||||
### TypeScript
|
||||
|
||||
```bash
|
||||
cd superset-frontend
|
||||
npm ci
|
||||
npm run lint
|
||||
```
|
||||
|
||||
If using the eslint extension with vscode, put the following in your workspace `settings.json` file:
|
||||
|
||||
```json
|
||||
"eslint.workingDirectories": [
|
||||
"superset-frontend"
|
||||
]
|
||||
```
|
||||
|
|
@ -0,0 +1,106 @@
|
|||
---
|
||||
title: Running a Local Flask Backend
|
||||
hide_title: true
|
||||
sidebar_position: 5
|
||||
version: 1
|
||||
---
|
||||
|
||||
### Flask server
|
||||
|
||||
#### OS Dependencies
|
||||
|
||||
Make sure your machine meets the [OS dependencies](https://superset.apache.org/docs/installation/installing-superset-from-scratch#os-dependencies) before following these steps.
|
||||
You also need to install MySQL or [MariaDB](https://mariadb.com/downloads).
|
||||
|
||||
Ensure that you are using Python version 3.7 or 3.8, then proceed with:
|
||||
|
||||
````bash
|
||||
# Create a virtual environment and activate it (recommended)
|
||||
python3 -m venv venv # setup a python3 virtualenv
|
||||
source venv/bin/activate
|
||||
|
||||
# Install external dependencies
|
||||
pip install -r requirements/testing.txt
|
||||
|
||||
# Install Superset in editable (development) mode
|
||||
pip install -e .
|
||||
|
||||
# Initialize the database
|
||||
superset db upgrade
|
||||
|
||||
# Create an admin user in your metadata database (use `admin` as username to be able to load the examples)
|
||||
superset fab create-admin
|
||||
|
||||
# Create default roles and permissions
|
||||
superset init
|
||||
|
||||
# Load some data to play with.
|
||||
# Note: you MUST have previously created an admin user with the username `admin` for this command to work.
|
||||
superset load-examples
|
||||
|
||||
# Start the Flask dev web server from inside your virtualenv.
|
||||
# Note that your page may not have CSS at this point.
|
||||
FLASK_ENV=development superset run -p 8088 --with-threads --reload --debugger
|
||||
```
|
||||
|
||||
Or you can install via our Makefile
|
||||
|
||||
```bash
|
||||
# Create a virtual environment and activate it (recommended)
|
||||
$ python3 -m venv venv # setup a python3 virtualenv
|
||||
$ source venv/bin/activate
|
||||
|
||||
# install pip packages + pre-commit
|
||||
$ make install
|
||||
|
||||
# Install superset pip packages and setup env only
|
||||
$ make superset
|
||||
|
||||
# Setup pre-commit only
|
||||
$ make pre-commit
|
||||
````
|
||||
|
||||
**Note: the FLASK_APP env var should not need to be set, as it's currently controlled
|
||||
via `.flaskenv`, however if needed, it should be set to `superset.app:create_app()`**
|
||||
|
||||
If you have made changes to the FAB-managed templates, which are not built the same way as the newer, React-powered front-end assets, you need to start the app without the `--with-threads` argument like so:
|
||||
`FLASK_ENV=development superset run -p 8088 --reload --debugger`
|
||||
|
||||
#### Dependencies
|
||||
|
||||
If you add a new requirement or update an existing requirement (per the `install_requires` section in `setup.py`) you must recompile (freeze) the Python dependencies to ensure that for CI, testing, etc. the build is deterministic. This can be achieved via,
|
||||
|
||||
```bash
|
||||
$ python3 -m venv venv
|
||||
$ source venv/bin/activate
|
||||
$ python3 -m pip install -r requirements/integration.txt
|
||||
$ pip-compile-multi --no-upgrade
|
||||
```
|
||||
|
||||
#### Logging to the browser console
|
||||
|
||||
This feature is only available on Python 3. When debugging your application, you can have the server logs sent directly to the browser console using the [ConsoleLog](https://github.com/betodealmeida/consolelog) package. You need to mutate the app, by adding the following to your `config.py` or `superset_config.py`:
|
||||
|
||||
```python
|
||||
from console_log import ConsoleLog
|
||||
|
||||
def FLASK_APP_MUTATOR(app):
|
||||
app.wsgi_app = ConsoleLog(app.wsgi_app, app.logger)
|
||||
```
|
||||
|
||||
Then make sure you run your WSGI server using the right worker type:
|
||||
|
||||
```bash
|
||||
FLASK_ENV=development gunicorn "superset.app:create_app()" -k "geventwebsocket.gunicorn.workers.GeventWebSocketWorker" -b 127.0.0.1:8088 --reload
|
||||
```
|
||||
|
||||
You can log anything to the browser console, including objects:
|
||||
|
||||
```python
|
||||
from superset import app
|
||||
app.logger.error('An exception occurred!')
|
||||
app.logger.info(form_data)
|
||||
```
|
||||
|
||||
### Frontend Assets
|
||||
See [Running Frontend Assets Locally](https://superset.apache.org/docs/installation/installing-superset-from-scratch#os-dependencies)
|
||||
|
|
@ -0,0 +1,96 @@
|
|||
---
|
||||
title: Pull Request Guidelines
|
||||
hide_title: true
|
||||
sidebar_position: 3
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Pull Request Guidelines
|
||||
|
||||
A philosophy we would like to strongly encourage is
|
||||
|
||||
> Before creating a PR, create an issue.
|
||||
|
||||
The purpose is to separate problem from possible solutions.
|
||||
|
||||
**Bug fixes:** If you’re only fixing a small bug, it’s fine to submit a pull request right away but we highly recommend to file an issue detailing what you’re fixing. This is helpful in case we don’t accept that specific fix but want to keep track of the issue. Please keep in mind that the project maintainers reserve the rights to accept or reject incoming PRs, so it is better to separate the issue and the code to fix it from each other. In some cases, project maintainers may request you to create a separate issue from PR before proceeding.
|
||||
|
||||
**Refactor:** For small refactors, it can be a standalone PR itself detailing what you are refactoring and why. If there are concerns, project maintainers may request you to create a `#SIP` for the PR before proceeding.
|
||||
|
||||
**Feature/Large changes:** If you intend to change the public API, or make any non-trivial changes to the implementation, we require you to file a new issue as `#SIP` (Superset Improvement Proposal). This lets us reach an agreement on your proposal before you put significant effort into it. You are welcome to submit a PR along with the SIP (sometimes necessary for demonstration), but we will not review/merge the code until the SIP is approved.
|
||||
|
||||
In general, small PRs are always easier to review than large PRs. The best practice is to break your work into smaller independent PRs and refer to the same issue. This will greatly reduce turnaround time.
|
||||
|
||||
If you wish to share your work which is not ready to merge yet, create a [Draft PR](https://github.blog/2019-02-14-introducing-draft-pull-requests/). This will enable maintainers and the CI runner to prioritize mature PR's.
|
||||
|
||||
Finally, never submit a PR that will put master branch in broken state. If the PR is part of multiple PRs to complete a large feature and cannot work on its own, you can create a feature branch and merge all related PRs into the feature branch before creating a PR from feature branch to master.
|
||||
|
||||
### Protocol
|
||||
|
||||
#### Authoring
|
||||
|
||||
- Fill in all sections of the PR template.
|
||||
- Title the PR with one of the following semantic prefixes (inspired by [Karma](http://karma-runner.github.io/0.10/dev/git-commit-msg.html])):
|
||||
|
||||
- `feat` (new feature)
|
||||
- `fix` (bug fix)
|
||||
- `docs` (changes to the documentation)
|
||||
- `style` (formatting, missing semi colons, etc; no application logic change)
|
||||
- `refactor` (refactoring code)
|
||||
- `test` (adding missing tests, refactoring tests; no application logic change)
|
||||
- `chore` (updating tasks etc; no application logic change)
|
||||
- `perf` (performance-related change)
|
||||
- `build` (build tooling, Docker configuration change)
|
||||
- `ci` (test runner, Github Actions workflow changes)
|
||||
- `other` (changes that don't correspond to the above -- should be rare!)
|
||||
- Examples:
|
||||
- `feat: export charts as ZIP files`
|
||||
- `perf(api): improve API info performance`
|
||||
- `fix(chart-api): cached-indicator always shows value is cached`
|
||||
|
||||
- Add prefix `[WIP]` to title if not ready for review (WIP = work-in-progress). We recommend creating a PR with `[WIP]` first and remove it once you have passed CI test and read through your code changes at least once.
|
||||
- If you believe your PR contributes a potentially breaking change, put a `!` after the semantic prefix but before the colon in the PR title, like so: `feat!: Added foo functionality to bar`
|
||||
- **Screenshots/GIFs:** Changes to user interface require before/after screenshots, or GIF for interactions
|
||||
- Recommended capture tools ([Kap](https://getkap.co/), [LICEcap](https://www.cockos.com/licecap/), [Skitch](https://download.cnet.com/Skitch/3000-13455_4-189876.html))
|
||||
- If no screenshot is provided, the committers will mark the PR with `need:screenshot` label and will not review until screenshot is provided.
|
||||
- **Dependencies:** Be careful about adding new dependency and avoid unnecessary dependencies.
|
||||
- For Python, include it in `setup.py` denoting any specific restrictions and in `requirements.txt` pinned to a specific version which ensures that the application build is deterministic.
|
||||
- For TypeScript/JavaScript, include new libraries in `package.json`
|
||||
- **Tests:** The pull request should include tests, either as doctests, unit tests, or both. Make sure to resolve all errors and test failures. See [Testing](#testing) for how to run tests.
|
||||
- **Documentation:** If the pull request adds functionality, the docs should be updated as part of the same PR.
|
||||
- **CI:** Reviewers will not review the code until all CI tests are passed. Sometimes there can be flaky tests. You can close and open PR to re-run CI test. Please report if the issue persists. After the CI fix has been deployed to `master`, please rebase your PR.
|
||||
- **Code coverage:** Please ensure that code coverage does not decrease.
|
||||
- Remove `[WIP]` when ready for review. Please note that it may be merged soon after approved so please make sure the PR is ready to merge and do not expect more time for post-approval edits.
|
||||
- If the PR was not ready for review and inactive for > 30 days, we will close it due to inactivity. The author is welcome to re-open and update.
|
||||
|
||||
#### Reviewing
|
||||
|
||||
- Use constructive tone when writing reviews.
|
||||
- If there are changes required, state clearly what needs to be done before the PR can be approved.
|
||||
- If you are asked to update your pull request with some changes there's no need to create a new one. Push your changes to the same branch.
|
||||
- The committers reserve the right to reject any PR and in some cases may request the author to file an issue.
|
||||
|
||||
#### Test Environments
|
||||
|
||||
- Members of the Apache GitHub org can launch an ephemeral test environment directly on a pull request by creating a comment containing (only) the command `/testenv up`.
|
||||
- Note that org membership must be public in order for this validation to function properly.
|
||||
- Feature flags may be set for a test environment by specifying the flag name (prefixed with `FEATURE_`) and value after the command.
|
||||
- Format: `/testenv up FEATURE_<feature flag name>=true|false`
|
||||
- Example: `/testenv up FEATURE_DASHBOARD_NATIVE_FILTERS=true`
|
||||
- Multiple feature flags may be set in single command, separated by whitespace
|
||||
- A comment will be created by the workflow script with the address and login information for the ephemeral environment.
|
||||
- Test environments may be created once the Docker build CI workflow for the PR has completed successfully.
|
||||
- Test environments do not currently update automatically when new commits are added to a pull request.
|
||||
- Test environments do not currently support async workers, though this is planned.
|
||||
- Running test environments will be shutdown upon closing the pull request.
|
||||
|
||||
#### Merging
|
||||
|
||||
- At least one approval is required for merging a PR.
|
||||
- PR is usually left open for at least 24 hours before merging.
|
||||
- After the PR is merged, [close the corresponding issue(s)](https://help.github.com/articles/closing-issues-using-keywords/).
|
||||
|
||||
#### Post-merge Responsibility
|
||||
|
||||
- Project maintainers may contact the PR author if new issues are introduced by the PR.
|
||||
- Project maintainers may revert your changes if a critical issue is found, such as breaking master branch CI.
|
||||
|
|
@ -0,0 +1,54 @@
|
|||
---
|
||||
title: Style Guide
|
||||
hide_title: true
|
||||
sidebar_position: 4
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Design Guidelines
|
||||
|
||||
### Capitalization guidelines
|
||||
|
||||
#### Sentence case
|
||||
|
||||
Use sentence-case capitalization for everything in the UI (except these \*\*).
|
||||
|
||||
Sentence case is predominantly lowercase. Capitalize only the initial character of the first word, and other words that require capitalization, like:
|
||||
|
||||
- **Proper nouns.** Objects in the product _are not_ considered proper nouns e.g. dashboards, charts, saved queries etc. Proprietary feature names eg. SQL Lab, Preset Manager _are_ considered proper nouns
|
||||
- **Acronyms** (e.g. CSS, HTML)
|
||||
- When referring to **UI labels that are themselves capitalized** from sentence case (e.g. page titles - Dashboards page, Charts page, Saved queries page, etc.)
|
||||
- User input that is reflected in the UI. E.g. a user-named a dashboard tab
|
||||
|
||||
**Sentence case vs. Title case:**
|
||||
Title case: "A Dog Takes a Walk in Paris"
|
||||
Sentence case: "A dog takes a walk in Paris"
|
||||
|
||||
**Why sentence case?**
|
||||
|
||||
- It’s generally accepted as the quickest to read
|
||||
- It’s the easiest form to distinguish between common and proper nouns
|
||||
|
||||
#### How to refer to UI elements
|
||||
|
||||
When writing about a UI element, use the same capitalization as used in the UI.
|
||||
|
||||
For example, if an input field is labeled “Name” then you refer to this as the “Name input field”. Similarly, if a button has the label “Save” in it, then it is correct to refer to the “Save button”.
|
||||
|
||||
Where a product page is titled “Settings”, you refer to this in writing as follows:
|
||||
“Edit your personal information on the Settings page”.
|
||||
|
||||
Often a product page will have the same title as the objects it contains. In this case, refer to the page as it appears in the UI, and the objects as common nouns:
|
||||
|
||||
- Upload a dashboard on the Dashboards page
|
||||
- Go to Dashboards
|
||||
- View dashboard
|
||||
- View all dashboards
|
||||
- Upload CSS templates on the CSS templates page
|
||||
- Queries that you save will appear on the Saved queries page
|
||||
- Create custom queries in SQL Lab then create dashboards
|
||||
|
||||
#### \*\*Exceptions to sentence case:
|
||||
|
||||
- Input labels, buttons and UI tabs are all caps
|
||||
- User input values (e.g. column names, SQL Lab tab names) should be in their original case
|
||||
|
|
@ -0,0 +1,275 @@
|
|||
---
|
||||
title: Testing
|
||||
hide_title: true
|
||||
sidebar_position: 8
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Testing
|
||||
|
||||
### Python Testing
|
||||
|
||||
All python tests are carried out in [tox](https://tox.readthedocs.io/en/latest/index.html)
|
||||
a standardized testing framework.
|
||||
All python tests can be run with any of the tox [environments](https://tox.readthedocs.io/en/latest/example/basic.html#a-simple-tox-ini-default-environments), via,
|
||||
|
||||
```bash
|
||||
tox -e <environment>
|
||||
```
|
||||
|
||||
For example,
|
||||
|
||||
```bash
|
||||
tox -e py38
|
||||
```
|
||||
|
||||
Alternatively, you can run all tests in a single file via,
|
||||
|
||||
```bash
|
||||
tox -e <environment> -- tests/test_file.py
|
||||
```
|
||||
|
||||
or for a specific test via,
|
||||
|
||||
```bash
|
||||
tox -e <environment> -- tests/test_file.py::TestClassName::test_method_name
|
||||
```
|
||||
|
||||
Note that the test environment uses a temporary directory for defining the
|
||||
SQLite databases which will be cleared each time before the group of test
|
||||
commands are invoked.
|
||||
|
||||
There is also a utility script included in the Superset codebase to run python integration tests. The [readme can be
|
||||
found here](https://github.com/apache/superset/tree/master/scripts/tests)
|
||||
|
||||
To run all integration tests for example, run this script from the root directory:
|
||||
|
||||
```bash
|
||||
scripts/tests/run.sh
|
||||
```
|
||||
|
||||
You can run unit tests found in './tests/unit_tests' for example with pytest. It is a simple way to run an isolated test that doesn't need any database setup
|
||||
|
||||
```bash
|
||||
pytest ./link_to_test.py
|
||||
```
|
||||
|
||||
### Frontend Testing
|
||||
|
||||
We use [Jest](https://jestjs.io/) and [Enzyme](https://airbnb.io/enzyme/) to test TypeScript/JavaScript. Tests can be run with:
|
||||
|
||||
```bash
|
||||
cd superset-frontend
|
||||
npm run test
|
||||
```
|
||||
|
||||
To run a single test file:
|
||||
|
||||
```bash
|
||||
npm run test -- path/to/file.js
|
||||
```
|
||||
|
||||
### Integration Testing
|
||||
|
||||
We use [Cypress](https://www.cypress.io/) for integration tests. Tests can be run by `tox -e cypress`. To open Cypress and explore tests first setup and run test server:
|
||||
|
||||
```bash
|
||||
export SUPERSET_CONFIG=tests.integration_tests.superset_test_config
|
||||
export SUPERSET_TESTENV=true
|
||||
export ENABLE_REACT_CRUD_VIEWS=true
|
||||
export CYPRESS_BASE_URL="http://localhost:8081"
|
||||
superset db upgrade
|
||||
superset load_test_users
|
||||
superset load-examples --load-test-data
|
||||
superset init
|
||||
superset run --port 8081
|
||||
```
|
||||
|
||||
Run Cypress tests:
|
||||
|
||||
```bash
|
||||
cd superset-frontend
|
||||
npm run build-instrumented
|
||||
|
||||
cd cypress-base
|
||||
npm install
|
||||
|
||||
# run tests via headless Chrome browser (requires Chrome 64+)
|
||||
npm run cypress-run-chrome
|
||||
|
||||
# run tests from a specific file
|
||||
npm run cypress-run-chrome -- --spec cypress/integration/explore/link.test.ts
|
||||
|
||||
# run specific file with video capture
|
||||
npm run cypress-run-chrome -- --spec cypress/integration/dashboard/index.test.js --config video=true
|
||||
|
||||
# to open the cypress ui
|
||||
npm run cypress-debug
|
||||
|
||||
# to point cypress to a url other than the default (http://localhost:8088) set the environment variable before running the script
|
||||
# e.g., CYPRESS_BASE_URL="http://localhost:9000"
|
||||
CYPRESS_BASE_URL=<your url> npm run cypress open
|
||||
```
|
||||
|
||||
See [`superset-frontend/cypress_build.sh`](https://github.com/apache/superset/blob/master/superset-frontend/cypress_build.sh).
|
||||
|
||||
As an alternative you can use docker-compose environment for testing:
|
||||
|
||||
Make sure you have added below line to your /etc/hosts file:
|
||||
`127.0.0.1 db`
|
||||
|
||||
If you already have launched Docker environment please use the following command to assure a fresh database instance:
|
||||
`docker-compose down -v`
|
||||
|
||||
Launch environment:
|
||||
|
||||
`CYPRESS_CONFIG=true docker-compose up`
|
||||
|
||||
It will serve backend and frontend on port 8088.
|
||||
|
||||
Run Cypress tests:
|
||||
|
||||
```bash
|
||||
cd cypress-base
|
||||
npm install
|
||||
npm run cypress open
|
||||
```
|
||||
|
||||
### Debugging Server App
|
||||
|
||||
Follow these instructions to debug the Flask app running inside a docker container.
|
||||
|
||||
First add the following to the ./docker-compose.yaml file
|
||||
|
||||
```diff
|
||||
superset:
|
||||
env_file: docker/.env
|
||||
image: *superset-image
|
||||
container_name: superset_app
|
||||
command: ["/app/docker/docker-bootstrap.sh", "app"]
|
||||
restart: unless-stopped
|
||||
+ cap_add:
|
||||
+ - SYS_PTRACE
|
||||
ports:
|
||||
- 8088:8088
|
||||
+ - 5678:5678
|
||||
user: "root"
|
||||
depends_on: *superset-depends-on
|
||||
volumes: *superset-volumes
|
||||
environment:
|
||||
CYPRESS_CONFIG: "${CYPRESS_CONFIG}"
|
||||
```
|
||||
|
||||
Start Superset as usual
|
||||
|
||||
```bash
|
||||
docker-compose up
|
||||
```
|
||||
|
||||
Install the required libraries and packages to the docker container
|
||||
|
||||
Enter the superset_app container
|
||||
|
||||
```bash
|
||||
docker exec -it superset_app /bin/bash
|
||||
root@39ce8cf9d6ab:/app#
|
||||
```
|
||||
|
||||
Run the following commands inside the container
|
||||
|
||||
```bash
|
||||
apt update
|
||||
apt install -y gdb
|
||||
apt install -y net-tools
|
||||
pip install debugpy
|
||||
```
|
||||
|
||||
Find the PID for the Flask process. Make sure to use the first PID. The Flask app will re-spawn a sub-process every time you change any of the python code. So it's important to use the first PID.
|
||||
|
||||
```bash
|
||||
ps -ef
|
||||
|
||||
UID PID PPID C STIME TTY TIME CMD
|
||||
root 1 0 0 14:09 ? 00:00:00 bash /app/docker/docker-bootstrap.sh app
|
||||
root 6 1 4 14:09 ? 00:00:04 /usr/local/bin/python /usr/bin/flask run -p 8088 --with-threads --reload --debugger --host=0.0.0.0
|
||||
root 10 6 7 14:09 ? 00:00:07 /usr/local/bin/python /usr/bin/flask run -p 8088 --with-threads --reload --debugger --host=0.0.0.0
|
||||
```
|
||||
|
||||
Inject debugpy into the running Flask process. In this case PID 6.
|
||||
|
||||
```bash
|
||||
python3 -m debugpy --listen 0.0.0.0:5678 --pid 6
|
||||
```
|
||||
|
||||
Verify that debugpy is listening on port 5678
|
||||
|
||||
```bash
|
||||
netstat -tunap
|
||||
|
||||
Active Internet connections (servers and established)
|
||||
Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name
|
||||
tcp 0 0 0.0.0.0:5678 0.0.0.0:* LISTEN 462/python
|
||||
tcp 0 0 0.0.0.0:8088 0.0.0.0:* LISTEN 6/python
|
||||
```
|
||||
|
||||
You are now ready to attach a debugger to the process. Using VSCode you can configure a launch configuration file .vscode/launch.json like so.
|
||||
|
||||
```
|
||||
{
|
||||
"version": "0.2.0",
|
||||
"configurations": [
|
||||
{
|
||||
"name": "Attach to Superset App in Docker Container",
|
||||
"type": "python",
|
||||
"request": "attach",
|
||||
"connect": {
|
||||
"host": "127.0.0.1",
|
||||
"port": 5678
|
||||
},
|
||||
"pathMappings": [
|
||||
{
|
||||
"localRoot": "${workspaceFolder}",
|
||||
"remoteRoot": "/app"
|
||||
}
|
||||
]
|
||||
},
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
VSCode will not stop on breakpoints right away. We've attached to PID 6 however it does not yet know of any sub-processes. In order to "wakeup" the debugger you need to modify a python file. This will trigger Flask to reload the code and create a new sub-process. This new sub-process will be detected by VSCode and breakpoints will be activated.
|
||||
|
||||
### Debugging Server App in Kubernetes Environment
|
||||
|
||||
To debug Flask running in POD inside kubernetes cluster. You'll need to make sure the pod runs as root and is granted the SYS_TRACE capability.These settings should not be used in production environments.
|
||||
|
||||
```
|
||||
securityContext:
|
||||
capabilities:
|
||||
add: ["SYS_PTRACE"]
|
||||
```
|
||||
|
||||
See (set capabilities for a container)[https://kubernetes.io/docs/tasks/configure-pod-container/security-context/#set-capabilities-for-a-container] for more details.
|
||||
|
||||
Once the pod is running as root and has the SYS_PTRACE capability it will be able to debug the Flask app.
|
||||
|
||||
You can follow the same instructions as in the docker-compose. Enter the pod and install the required library and packages; gdb, netstat and debugpy.
|
||||
|
||||
Often in a Kubernetes environment nodes are not addressable from outside the cluster. VSCode will thus be unable to remotely connect to port 5678 on a Kubernetes node. In order to do this you need to create a tunnel that port forwards 5678 to your local machine.
|
||||
|
||||
```
|
||||
kubectl port-forward pod/superset-<some random id> 5678:5678
|
||||
```
|
||||
|
||||
You can now launch your VSCode debugger with the same config as above. VSCode will connect to to 127.0.0.1:5678 which is forwarded by kubectl to your remote kubernetes POD.
|
||||
|
||||
### Storybook
|
||||
|
||||
Superset includes a [Storybook](https://storybook.js.org/) to preview the layout/styling of various Superset components, and variations thereof. To open and view the Storybook:
|
||||
|
||||
```bash
|
||||
cd superset-frontend
|
||||
npm run storybook
|
||||
```
|
||||
|
||||
When contributing new React components to Superset, please try to add a Story alongside the component's `jsx/tsx` file.
|
||||
|
|
@ -0,0 +1,103 @@
|
|||
---
|
||||
title: Translating
|
||||
hide_title: true
|
||||
sidebar_position: 9
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Translating
|
||||
|
||||
We use [Babel](http://babel.pocoo.org/en/latest/) to translate Superset.
|
||||
In Python files, we import the magic `_` function using:
|
||||
|
||||
```python
|
||||
from flask_babel import lazy_gettext as _
|
||||
```
|
||||
|
||||
then wrap our translatable strings with it, e.g. `_('Translate me')`.
|
||||
During extraction, string literals passed to `_` will be added to the
|
||||
generated `.po` file for each language for later translation.
|
||||
|
||||
At runtime, the `_` function will return the translation of the given
|
||||
string for the current language, or the given string itself
|
||||
if no translation is available.
|
||||
|
||||
In TypeScript/JavaScript, the technique is similar:
|
||||
we import `t` (simple translation), `tn` (translation containing a number).
|
||||
|
||||
```javascript
|
||||
import { t, tn } from "@superset-ui/translation";
|
||||
```
|
||||
|
||||
### Enabling language selection
|
||||
|
||||
Add the `LANGUAGES` variable to your `superset_config.py`. Having more than one
|
||||
option inside will add a language selection dropdown to the UI on the right side
|
||||
of the navigation bar.
|
||||
|
||||
```python
|
||||
LANGUAGES = {
|
||||
'en': {'flag': 'us', 'name': 'English'},
|
||||
'fr': {'flag': 'fr', 'name': 'French'},
|
||||
'zh': {'flag': 'cn', 'name': 'Chinese'},
|
||||
}
|
||||
```
|
||||
|
||||
### Extracting new strings for translation
|
||||
|
||||
```bash
|
||||
pybabel extract -F superset/translations/babel.cfg -o superset/translations/messages.pot -k _ -k __ -k t -k tn -k tct .
|
||||
```
|
||||
|
||||
This will update the template file `superset/translations/messages.pot` with current application strings. Do not forget to update
|
||||
this file with the appropriate license information.
|
||||
|
||||
### Updating language files
|
||||
|
||||
```bash
|
||||
pybabel update -i superset/translations/messages.pot -d superset/translations --ignore-obsolete
|
||||
```
|
||||
|
||||
This will update language files with the new extracted strings.
|
||||
|
||||
You can then translate the strings gathered in files located under
|
||||
`superset/translation`, where there's one per language. You can use [Poedit](https://poedit.net/features)
|
||||
to translate the `po` file more conveniently.
|
||||
There are some [tutorials in the wiki](https://wiki.lxde.org/en/Translate_*.po_files_with_Poedit).
|
||||
|
||||
In the case of JS translation, we need to convert the PO file into a JSON file, and we need the global download of the npm package po2json.
|
||||
|
||||
```bash
|
||||
npm install -g po2json
|
||||
```
|
||||
|
||||
To convert all PO files to formatted JSON files you can use the `po2json.sh` script.
|
||||
|
||||
```bash
|
||||
./scripts/po2json.sh
|
||||
```
|
||||
|
||||
If you get errors running `po2json`, you might be running the Ubuntu package with the same
|
||||
name, rather than the Node.js package (they have a different format for the arguments). If
|
||||
there is a conflict, you may need to update your `PATH` environment variable or fully qualify
|
||||
the executable path (e.g. `/usr/local/bin/po2json` instead of `po2json`).
|
||||
If you get a lot of `[null,***]` in `messages.json`, just delete all the `null,`.
|
||||
For example, `"year":["年"]` is correct while `"year":[null,"年"]`is incorrect.
|
||||
|
||||
For the translations to take effect we need to compile translation catalogs into binary MO files.
|
||||
|
||||
```bash
|
||||
pybabel compile -d superset/translations
|
||||
```
|
||||
|
||||
### Creating a new language dictionary
|
||||
|
||||
To create a dictionary for a new language, run the following, where `LANGUAGE_CODE` is replaced with
|
||||
the language code for your target language, e.g. `es` (see [Flask AppBuilder i18n documentation](https://flask-appbuilder.readthedocs.io/en/latest/i18n.html) for more details):
|
||||
|
||||
```bash
|
||||
pip install -r superset/translations/requirements.txt
|
||||
pybabel init -i superset/translations/messages.pot -d superset/translations -l LANGUAGE_CODE
|
||||
```
|
||||
|
||||
Then, [extract strings for the new language](#extracting-new-strings-for-translation).
|
||||
|
|
@ -0,0 +1,60 @@
|
|||
---
|
||||
title: Types of Contributions
|
||||
hide_title: true
|
||||
sidebar_position: 2
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Types of Contributions
|
||||
|
||||
### Report Bug
|
||||
|
||||
The best way to report a bug is to file an issue on GitHub. Please include:
|
||||
|
||||
- Your operating system name and version.
|
||||
- Superset version.
|
||||
- Detailed steps to reproduce the bug.
|
||||
- Any details about your local setup that might be helpful in troubleshooting.
|
||||
|
||||
When posting Python stack traces, please quote them using
|
||||
[Markdown blocks](https://help.github.com/articles/creating-and-highlighting-code-blocks/).
|
||||
|
||||
### Submit Ideas or Feature Requests
|
||||
|
||||
The best way is to file an issue on GitHub:
|
||||
|
||||
- Explain in detail how it would work.
|
||||
- Keep the scope as narrow as possible, to make it easier to implement.
|
||||
- Remember that this is a volunteer-driven project, and that contributions are welcome :)
|
||||
|
||||
For large features or major changes to codebase, please create **Superset Improvement Proposal (SIP)**. See template from [SIP-0](https://github.com/apache/superset/issues/5602)
|
||||
|
||||
### Fix Bugs
|
||||
|
||||
Look through the GitHub issues. Issues tagged with `#bug` are
|
||||
open to whoever wants to implement them.
|
||||
|
||||
### Implement Features
|
||||
|
||||
Look through the GitHub issues. Issues tagged with
|
||||
`#feature` is open to whoever wants to implement it.
|
||||
|
||||
### Improve Documentation
|
||||
|
||||
Superset could always use better documentation,
|
||||
whether as part of the official Superset docs,
|
||||
in docstrings, `docs/*.rst` or even on the web as blog posts or
|
||||
articles. See [Documentation](#documentation) for more details.
|
||||
|
||||
### Add Translations
|
||||
|
||||
If you are proficient in a non-English language, you can help translate
|
||||
text strings from Superset's UI. You can jump in to the existing
|
||||
language dictionaries at
|
||||
`superset/translations/<language_code>/LC_MESSAGES/messages.po`, or
|
||||
even create a dictionary for a new language altogether.
|
||||
See [Translating](#translating) for more details.
|
||||
|
||||
### Ask Questions
|
||||
|
||||
There is a dedicated [`apache-superset` tag](https://stackoverflow.com/questions/tagged/apache-superset) on [StackOverflow](https://stackoverflow.com/). Please use it when asking questions.
|
||||
|
|
@ -0,0 +1,4 @@
|
|||
{
|
||||
"label": "Creating Charts and Dashboards",
|
||||
"position": 4
|
||||
}
|
||||
|
|
@ -0,0 +1,191 @@
|
|||
---
|
||||
title: Creating Your First Dashboard
|
||||
hide_title: true
|
||||
sidebar_position: 1
|
||||
version: 1
|
||||
---
|
||||
|
||||
import useBaseUrl from "@docusaurus/useBaseUrl";
|
||||
|
||||
## Creating Your First Dashboard
|
||||
|
||||
This section is focused on documentation for end-users who will be using Superset
|
||||
for the data analysis and exploration workflow
|
||||
(data analysts, business analysts, data
|
||||
scientists, etc). In addition to this site, [Preset.io](http://preset.io/) maintains an updated set of end-user
|
||||
documentation at [docs.preset.io](https://docs.preset.io/).
|
||||
|
||||
This tutorial targets someone who wants to create charts and dashboards in Superset. We’ll show you
|
||||
how to connect Superset to a new database and configure a table in that database for analysis.
|
||||
You’ll also explore the data you’ve exposed and add a visualization to a dashboard so that you get a
|
||||
feel for the end-to-end user experience.
|
||||
|
||||
### Connecting to a new database
|
||||
|
||||
Superset itself doesn't have a storage layer to store your data but instead pairs with
|
||||
your existing SQL-speaking database or data store.
|
||||
|
||||
First things first, we need to add the connection credentials to your database to be able
|
||||
to query and visualize data from it. If you're using Superset locally via
|
||||
[Docker compose](/docs/installation/installing-superset-using-docker-compose), you can
|
||||
skip this step because a Postgres database, named **examples**, is included and
|
||||
pre-configured in Superset for you.
|
||||
|
||||
Under the **Data** menu, select the _Databases_ option:
|
||||
|
||||
<img src={useBaseUrl("/img/tutorial/tutorial_01_sources_database.png" )} />{" "} <br/><br/>
|
||||
|
||||
Next, click the green **+ Database** button in the top right corner:
|
||||
|
||||
<img src={useBaseUrl("/img/tutorial/tutorial_02_add_database.png" )} />{" "} <br/><br/>
|
||||
|
||||
You can configure a number of advanced options in this window, but for this walkthrough you only
|
||||
need to specify two things (the database name and SQLAlchemy URI):
|
||||
|
||||
<img src={useBaseUrl("/img/tutorial/tutorial_03_database_name.png" )} />
|
||||
|
||||
As noted in the text below
|
||||
the URI, you should refer to the SQLAlchemy documentation on
|
||||
[creating new connection URIs](https://docs.sqlalchemy.org/en/12/core/engines.html#database-urls)
|
||||
for your target database.
|
||||
|
||||
Click the **Test Connection** button to confirm things work end to end. If the connection looks good, save the configuration
|
||||
by clicking the **Add** button in the bottom right corner of the modal window:
|
||||
|
||||
<img src={useBaseUrl("/img/tutorial/tutorial_04_add_button.png" )} />
|
||||
|
||||
Congratulations, you've just added a new data source in Superset!
|
||||
|
||||
### Registering a new table
|
||||
|
||||
Now that you’ve configured a data source, you can select specific tables (called **Datasets** in Superset)
|
||||
that you want exposed in Superset for querying.
|
||||
|
||||
Navigate to **Data ‣ Datasets** and select the **+ Dataset** button in the top right corner.
|
||||
|
||||
<img src={useBaseUrl("/img/tutorial/tutorial_08_sources_tables.png" )} />
|
||||
|
||||
A modal window should pop up in front of you. Select your **Database**,
|
||||
**Schema**, and **Table** using the drop downs that appear. In the following example,
|
||||
we register the **cleaned_sales_data** table from the **examples** database.
|
||||
|
||||
<img src={useBaseUrl("/img/tutorial/tutorial_09_add_new_table.png" )} />
|
||||
|
||||
To finish, click the **Add** button in the bottom right corner. You should now see your dataset in the list of datasets.
|
||||
|
||||
### Customizing column properties
|
||||
|
||||
Now that you've registered your dataset, you can configure column properties
|
||||
for how the column should be treated in the Explore workflow:
|
||||
|
||||
- Is the column temporal? (should it be used for slicing & dicing in time series charts?)
|
||||
- Should the column be filterable?
|
||||
- Is the column dimensional?
|
||||
- If it's a datetime column, how should Superset parse
|
||||
the datetime format? (using the [ISO-8601 string pattern](https://en.wikipedia.org/wiki/ISO_8601))
|
||||
|
||||
<img src={useBaseUrl("/img/tutorial/tutorial_column_properties.png" )} />
|
||||
|
||||
### Superset semantic layer
|
||||
|
||||
Superset has a thin semantic layer that adds many quality of life improvements for analysts.
|
||||
The Superset semantic layer can store 2 types of computed data:
|
||||
|
||||
1. Virtual metrics: you can write SQL queries that aggregate values
|
||||
from multiple column (e.g. `SUM(recovered) / SUM(confirmed)`) and make them
|
||||
available as columns for (e.g. `recovery_rate`) visualization in Explore.
|
||||
Agggregate functions are allowed and encouraged for metrics.
|
||||
|
||||
<img src={useBaseUrl("/img/tutorial/tutorial_sql_metric.png" )} />
|
||||
|
||||
You can also certify metrics if you'd like for your team in this view.
|
||||
|
||||
2. Virtual calculated columns: you can write SQL queries that
|
||||
customize the appearance and behavior
|
||||
of a specific column (e.g. `CAST(recovery_rate) as float`).
|
||||
Aggregate functions aren't allowed in calculated columns.
|
||||
|
||||
<img src={useBaseUrl("/img/tutorial/tutorial_calculated_column.png" )} />
|
||||
|
||||
### Creating charts in Explore view
|
||||
|
||||
Superset has 2 main interfaces for exploring data:
|
||||
|
||||
- **Explore**: no-code viz builder. Select your dataset, select the chart,
|
||||
customize the appearance, and publish.
|
||||
- **SQL Lab**: SQL IDE for cleaning, joining, and preparing data for Explore workflow
|
||||
|
||||
We'll focus on the Explore view for creating charts right now.
|
||||
To start the Explore workflow from the **Datasets** tab, start by clicking the name
|
||||
of the dataset that will be powering your chart.
|
||||
|
||||
<img src={useBaseUrl("/img/tutorial/tutorial_launch_explore.png" )} /><br/><br/>
|
||||
|
||||
You're now presented with a powerful workflow for exploring data and iterating on charts.
|
||||
|
||||
- The **Dataset** view on the left-hand side has a list of columns and metrics,
|
||||
scoped to the current dataset you selected.
|
||||
- The **Data** preview below the chart area also gives you helpful data context.
|
||||
- Using the **Data** tab and **Customize** tabs, you can change the visualization type,
|
||||
select the temporal column, select the metric to group by, and customize
|
||||
the aesthetics of the chart.
|
||||
|
||||
As you customize your chart using drop-down menus, make sure to click the **Run** button
|
||||
to get visual feedback.
|
||||
|
||||
<img src={useBaseUrl("/img/tutorial/tutorial_explore_run.jpg" )} />
|
||||
|
||||
In the following screenshot, we craft a grouped Time-series Bar Chart to visualize
|
||||
our quarterly sales data by product line just be clicking options in drop-down menus.
|
||||
|
||||
<img src={useBaseUrl("/img/tutorial/tutorial_explore_settings.jpg" )} />
|
||||
|
||||
### Creating a slice and dashboard
|
||||
|
||||
To save your chart, first click the **Save** button. You can either:
|
||||
|
||||
- Save your chart and add it to an existing dashboard
|
||||
- Save your chart and add it to a new dashboard
|
||||
|
||||
In the following screenshot, we save the chart to a new "Superset Duper Sales Dashboard":
|
||||
|
||||
<img src={useBaseUrl("/img/tutorial/tutorial_save_slice.png" )} />
|
||||
|
||||
To publish, click **Save and goto Dashboard**.
|
||||
|
||||
Behind the scenes, Superset will create a slice and store all the information needed
|
||||
to create your chart in its thin data layer
|
||||
(the query, chart type, options selected, name, etc).
|
||||
|
||||
<img src={useBaseUrl("/img/tutorial/tutorial_first_dashboard.png" )} />
|
||||
|
||||
To resize the chart, start by clicking the pencil button in the top right corner.
|
||||
|
||||
<img src={useBaseUrl("/img/tutorial/tutorial_pencil_edit.png" )} />
|
||||
|
||||
Then, click and drag the bottom right corner of the chart until the chart layout snaps
|
||||
into a position you like onto the underlying grid.
|
||||
|
||||
<img src={useBaseUrl("/img/tutorial/tutorial_chart_resize.png" )} />
|
||||
|
||||
Click **Save** to persist the changes.
|
||||
|
||||
Congrats! You’ve successfully linked, analyzed, and visualized data in Superset. There are a wealth
|
||||
of other table configuration and visualization options, so please start exploring and creating
|
||||
slices and dashboards of your own
|
||||
|
||||
ֿ
|
||||
### Manage access to Dashboards
|
||||
|
||||
|
||||
Access to dashboards is managed via owners (users that have edit permissions to the dashboard)
|
||||
|
||||
Non-owner users access can be managed two different ways:
|
||||
|
||||
1. Dataset permissions - if you add to the relevant role permissions to datasets it automatically grants implict access to all dashboards that uses those permitted datasets
|
||||
2. Dashboard roles - if you enable **DASHBOARD_RBAC** feature flag then you be able to manage which roles can access the dashboard
|
||||
- Having dashboard access implicitly grants read access to the associated datasets, therefore
|
||||
all charts will load their data even if feature flag is turned on and no roles assigned
|
||||
to roles the access will fallback to **Dataset permissions**
|
||||
|
||||
<img src={useBaseUrl("/img/tutorial/tutorial_dashboard_access.png" )} />
|
||||
|
|
@ -0,0 +1,354 @@
|
|||
---
|
||||
title: Exploring Data in Superset
|
||||
hide_title: true
|
||||
sidebar_position: 2
|
||||
version: 1
|
||||
---
|
||||
|
||||
import useBaseUrl from "@docusaurus/useBaseUrl";
|
||||
|
||||
## Exploring Data in Superset
|
||||
|
||||
In this tutorial, we will introduce key concepts in Apache Superset through the exploration of a
|
||||
real dataset which contains the flights made by employees of a UK-based organization in 2011. The
|
||||
following information about each flight is given:
|
||||
|
||||
- The traveller’s department. For the purposes of this tutorial the departments have been renamed
|
||||
Orange, Yellow and Purple.
|
||||
- The cost of the ticket.
|
||||
- The travel class (Economy, Premium Economy, Business and First Class).
|
||||
- Whether the ticket was a single or return.
|
||||
- The date of travel.
|
||||
- Information about the origin and destination.
|
||||
- The distance between the origin and destination, in kilometers (km).
|
||||
|
||||
### Enabling Data Upload Functionality
|
||||
|
||||
You may need to enable the functionality to upload a CSV or Excel file to your database. The following section
|
||||
explains how to enable this functionality for the examples database.
|
||||
|
||||
In the top menu, select **Data ‣ Databases**. Find the **examples** database in the list and
|
||||
select the **Edit** button.
|
||||
|
||||
<img src={useBaseUrl("/img/tutorial/edit-record.png" )} />
|
||||
|
||||
In the resulting modal window, switch to the **Extra** tab and
|
||||
tick the checkbox for **Allow Data Upload**. End by clicking the **Save** button.
|
||||
|
||||
<img src={useBaseUrl("/img/tutorial/add-data-upload.png" )} />
|
||||
|
||||
### Loading CSV Data
|
||||
|
||||
Download the CSV dataset to your computer from
|
||||
[Github](https://raw.githubusercontent.com/apache-superset/examples-data/master/tutorial_flights.csv).
|
||||
In the Superset menu, select **Data ‣ Upload a CSV**.
|
||||
|
||||
<img src={useBaseUrl("/img/tutorial/upload_a_csv.png" )} />
|
||||
|
||||
Then, enter the **Table Name** as _tutorial_flights_ and select the CSV file from your computer.
|
||||
|
||||
<img src={useBaseUrl("/img/tutorial/csv_to_database_configuration.png" )} />
|
||||
|
||||
Next enter the text _Travel Date_ into the **Parse Dates** field.
|
||||
|
||||
<img src={useBaseUrl("/img/tutorial/parse_dates_column.png" )} />
|
||||
|
||||
Leaving all the other options in their default settings, select **Save** at the bottom of the page.
|
||||
|
||||
### Table Visualization
|
||||
|
||||
You should now see _tutorial_flights_ as a dataset in the **Datasets** tab. Click on the entry to
|
||||
launch an Explore workflow using this dataset.
|
||||
|
||||
In this section, we'll create a table visualization
|
||||
to show the number of flights and cost per travel class.
|
||||
|
||||
By default, Apache Superset only shows the last week of data. In our example, we want to visualize all
|
||||
of the data in the dataset. Click the **Time ‣ Time Range** section and change
|
||||
the **Range Type** to **No Filter**.
|
||||
|
||||
<img src={useBaseUrl("/img/tutorial/no_filter_on_time_filter.png" )} />
|
||||
|
||||
Click **Apply** to save.
|
||||
|
||||
Now, we want to specify the rows in our table by using the **Group by** option. Since in this
|
||||
example, we want to understand different Travel Classes, we select **Travel Class** in this menu.
|
||||
|
||||
Next, we can specify the metrics we would like to see in our table with the **Metrics** option.
|
||||
|
||||
- `COUNT(*)`, which represents the number of rows in the table
|
||||
(in this case, quantity of flights in each Travel Class)
|
||||
- `SUM(Cost)`, which represents the total cost spent by each Travel Class
|
||||
|
||||
<img src={useBaseUrl("/img/tutorial/sum_cost_column.png" )} />
|
||||
|
||||
Finally, select **Run Query** to see the results of the table.
|
||||
|
||||
<img src={useBaseUrl("/img/tutorial/tutorial_table.png" )} />
|
||||
|
||||
To save the visualization, click on **Save** in the top left of the screen. In the following modal,
|
||||
|
||||
- Select the **Save as**
|
||||
option and enter the chart name as Tutorial Table (you will be able to find it again through the
|
||||
**Charts** screen, accessible in the top menu).
|
||||
- Select **Add To Dashboard** and enter
|
||||
Tutorial Dashboard. Finally, select **Save & Go To Dashboard**.
|
||||
|
||||
<img src={useBaseUrl("/img/tutorial/save_tutorial_table.png" )} />
|
||||
|
||||
### Dashboard Basics
|
||||
|
||||
Next, we are going to explore the dashboard interface. If you’ve followed the previous section, you
|
||||
should already have the dashboard open. Otherwise, you can navigate to the dashboard by selecting
|
||||
Dashboards on the top menu, then Tutorial dashboard from the list of dashboards.
|
||||
|
||||
On this dashboard you should see the table you created in the previous section. Select **Edit
|
||||
dashboard** and then hover over the table. By selecting the bottom right hand corner of the table
|
||||
(the cursor will change too), you can resize it by dragging and dropping.
|
||||
|
||||
<img src={useBaseUrl("/img/tutorial/resize_tutorial_table_on_dashboard.png" )} />
|
||||
|
||||
Finally, save your changes by selecting Save changes in the top right.
|
||||
|
||||
### Pivot Table
|
||||
|
||||
In this section, we will extend our analysis using a more complex visualization, Pivot Table. By the
|
||||
end of this section, you will have created a table that shows the monthly spend on flights for the
|
||||
first six months, by department, by travel class.
|
||||
|
||||
Create a new chart by selecting **+ ‣ Chart** from the top right corner. Choose
|
||||
tutorial_flights again as a datasource, then click on the visualization type to get to the
|
||||
visualization menu. Select the **Pivot Table** visualization (you can filter by entering text in the
|
||||
search box) and then **Create New Chart**.
|
||||
|
||||
<img src={useBaseUrl("/img/tutorial/create_pivot.png" )} />
|
||||
|
||||
In the **Time** section, keep the Time Column as Travel Date (this is selected automatically as we
|
||||
only have one time column in our dataset). Then select Time Grain to be month as having daily data
|
||||
would be too granular to see patterns from. Then select the time range to be the first six months of
|
||||
2011 by click on Last week in the Time Range section, then in Custom selecting a Start / end of 1st
|
||||
January 2011 and 30th June 2011 respectively by either entering directly the dates or using the
|
||||
calendar widget (by selecting the month name and then the year, you can move more quickly to far
|
||||
away dates).
|
||||
|
||||
<img src={useBaseUrl("/img/tutorial/select_dates_pivot_table.png" )} />
|
||||
|
||||
Next, within the **Query** section, remove the default COUNT(\*) and add Cost, keeping the default
|
||||
SUM aggregate. Note that Apache Superset will indicate the type of the metric by the symbol on the
|
||||
left hand column of the list (ABC for string, # for number, a clock face for time, etc.).
|
||||
|
||||
In **Group by** select **Time**: this will automatically use the Time Column and Time Grain
|
||||
selections we defined in the Time section.
|
||||
|
||||
Within **Columns**, select first Department and then Travel Class. All set – let’s **Run Query** to
|
||||
see some data!
|
||||
|
||||
<img src={useBaseUrl("/img/tutorial/tutorial_pivot_table.png" )} />
|
||||
|
||||
You should see months in the rows and Department and Travel Class in the columns. Publish this chart
|
||||
to your existing Tutorial Dashboard you created earlier.
|
||||
|
||||
### Line Chart
|
||||
|
||||
In this section, we are going to create a line chart to understand the average price of a ticket by
|
||||
month across the entire dataset.
|
||||
|
||||
In the Time section, as before, keep the Time Column as Travel Date and Time Grain as month but this
|
||||
time for the Time range select No filter as we want to look at entire dataset.
|
||||
|
||||
Within Metrics, remove the default `COUNT(*)` metric and instead add `AVG(Cost)`, to show the mean value.
|
||||
|
||||
<img src={useBaseUrl("/img/tutorial/average_aggregate_for_cost.png" )} />
|
||||
|
||||
Next, select **Run Query** to show the data on the chart.
|
||||
|
||||
How does this look? Well, we can see that the average cost goes up in December. However, perhaps it
|
||||
doesn’t make sense to combine both single and return tickets, but rather show two separate lines for
|
||||
each ticket type.
|
||||
|
||||
Let’s do this by selecting Ticket Single or Return in the Group by box, and the selecting **Run
|
||||
Query** again. Nice! We can see that on average single tickets are cheaper than returns and that the
|
||||
big spike in December is caused by return tickets.
|
||||
|
||||
Our chart is looking pretty good already, but let’s customize some more by going to the Customize
|
||||
tab on the left hand pane. Within this pane, try changing the Color Scheme, removing the range
|
||||
filter by selecting No in the Show Range Filter drop down and adding some labels using X Axis Label
|
||||
and Y Axis Label.
|
||||
|
||||
<img src={useBaseUrl("/img/tutorial/tutorial_line_chart.png" )} />
|
||||
|
||||
Once you’re done, publish the chart in your Tutorial Dashboard.
|
||||
|
||||
### Markup
|
||||
|
||||
In this section, we will add some text to our dashboard. If you’re there already, you can navigate
|
||||
to the dashboard by selecting Dashboards on the top menu, then Tutorial dashboard from the list of
|
||||
dashboards. Got into edit mode by selecting **Edit dashboard**.
|
||||
|
||||
Within the Insert components pane, drag and drop a Markdown box on the dashboard. Look for the blue
|
||||
lines which indicate the anchor where the box will go.
|
||||
|
||||
<img src={useBaseUrl("/img/tutorial/blue_bar_insert_component.png" )} />
|
||||
|
||||
Now, to edit the text, select the box. You can enter text, in markdown format (see
|
||||
[this Markdown Cheatsheet](https://github.com/adam-p/markdown-here/wiki/Markdown-Cheatsheet) for
|
||||
more information about this format). You can toggle between Edit and Preview using the menu on the
|
||||
top of the box.
|
||||
|
||||
<img src={useBaseUrl("/img/tutorial/markdown.png" )} />
|
||||
|
||||
To exit, select any other part of the dashboard. Finally, don’t forget to keep your changes using
|
||||
**Save changes**.
|
||||
|
||||
### Filter Box
|
||||
|
||||
In this section, you will learn how to add a filter to your dashboard. Specifically, we will create
|
||||
a filter that allows us to look at those flights that depart from a particular country.
|
||||
|
||||
A filter box visualization can be created as any other visualization by selecting **+ ‣ Chart**,
|
||||
and then _tutorial_flights_ as the datasource and Filter Box as the visualization type.
|
||||
|
||||
First of all, in the **Time** section, remove the filter from the Time range selection by selecting
|
||||
No filter.
|
||||
|
||||
Next, in **Filters Configurations** first add a new filter by selecting the plus sign and then edit
|
||||
the newly created filter by selecting the pencil icon.
|
||||
|
||||
For our use case, it makes most sense to present a list of countries in alphabetical order. First,
|
||||
enter the column as Origin Country and keep all other options the same and then select **Run
|
||||
Query**. This gives us a preview of our filter.
|
||||
|
||||
Next, remove the date filter by unchecking the Date Filter checkbox.
|
||||
|
||||
<img src={useBaseUrl("/img/tutorial/filter_on_origin_country.png" )} />
|
||||
|
||||
Finally, select **Save**, name the chart as Tutorial Filter, add the chart to our existing Tutorial
|
||||
Dashboard and then Save & go to dashboard. Once on the Dashboard, try using the filter to show only
|
||||
those flights that departed from the United Kingdom – you will see the filter is applied to all of
|
||||
the other visualizations on the dashboard.
|
||||
|
||||
### Publishing Your Dashboard
|
||||
|
||||
If you have followed all of the steps outlined in the previous section, you should have a dashboard
|
||||
that looks like the below. If you would like, you can rearrange the elements of the dashboard by
|
||||
selecting **Edit dashboard** and dragging and dropping.
|
||||
|
||||
If you would like to make your dashboard available to other users, simply select Draft next to the
|
||||
title of your dashboard on the top left to change your dashboard to be in Published state. You can
|
||||
also favorite this dashboard by selecting the star.
|
||||
|
||||
<img src={useBaseUrl("/img/tutorial/publish_dashboard.png" )} />
|
||||
|
||||
### Annotations
|
||||
|
||||
Annotations allow you to add additional context to your chart. In this section, we will add an
|
||||
annotation to the Tutorial Line Chart we made in a previous section. Specifically, we will add the
|
||||
dates when some flights were cancelled by the UK’s Civil Aviation Authority in response to the
|
||||
eruption of the Grímsvötn volcano in Iceland (23-25 May 2011).
|
||||
|
||||
First, add an annotation layer by navigating to Manage ‣ Annotation Layers. Add a new annotation
|
||||
layer by selecting the green plus sign to add a new record. Enter the name Volcanic Eruptions and
|
||||
save. We can use this layer to refer to a number of different annotations.
|
||||
|
||||
Next, add an annotation by navigating to Manage ‣ Annotations and then create a new annotation by
|
||||
selecting the green plus sign. Then, select the Volcanic Eruptions layer, add a short description
|
||||
Grímsvötn and the eruption dates (23-25 May 2011) before finally saving.
|
||||
|
||||
<img src={useBaseUrl("/img/tutorial/edit_annotation.png" )} />
|
||||
|
||||
Then, navigate to the line chart by going to Charts then selecting Tutorial Line Chart from the
|
||||
list. Next, go to the Annotations and Layers section and select Add Annotation Layer. Within this
|
||||
dialogue:
|
||||
|
||||
- Name the layer as Volcanic Eruptions
|
||||
- Change the Annotation Layer Type to Event
|
||||
- Set the Annotation Source as Superset annotation
|
||||
- Specify the Annotation Layer as Volcanic Eruptions
|
||||
|
||||
<img src={useBaseUrl("/img/tutorial/annotation_settings.png" )} />
|
||||
|
||||
Select **Apply** to see your annotation shown on the chart.
|
||||
|
||||
<img src={useBaseUrl("/img/tutorial/annotation.png" )} />
|
||||
|
||||
If you wish, you can change how your annotation looks by changing the settings in the Display
|
||||
configuration section. Otherwise, select **OK** and finally **Save** to save your chart. If you keep
|
||||
the default selection to overwrite the chart, your annotation will be saved to the chart and also
|
||||
appear automatically in the Tutorial Dashboard.
|
||||
|
||||
### Advanced Analytics
|
||||
|
||||
In this section, we are going to explore the Advanced Analytics feature of Apache Superset that
|
||||
allows you to apply additional transformations to your data. The three types of transformation are:
|
||||
|
||||
**Setting up the base chart**
|
||||
|
||||
In this section, we’re going to set up a base chart which we can then apply the different **Advanced
|
||||
Analytics** features to. Start off by creating a new chart using the same _tutorial_flights_
|
||||
datasource and the **Line Chart** visualization type. Within the Time section, set the Time Range as
|
||||
1st October 2011 and 31st October 2011.
|
||||
|
||||
Next, in the query section, change the Metrics to the sum of Cost. Select **Run Query** to show the
|
||||
chart. You should see the total cost per day for each month in October 2011.
|
||||
|
||||
<img src={useBaseUrl("/img/tutorial/advanced_analytics_base.png" )} />
|
||||
|
||||
Finally, save the visualization as Tutorial Advanced Analytics Base, adding it to the Tutorial
|
||||
Dashboard.
|
||||
|
||||
### Rolling Mean
|
||||
|
||||
There is quite a lot of variation in the data, which makes it difficult to identify any trend. One
|
||||
approach we can take is to show instead a rolling average of the time series. To do this, in the
|
||||
**Moving Average** subsection of **Advanced Analytics**, select mean in the **Rolling** box and
|
||||
enter 7 into both Periods and Min Periods. The period is the length of the rolling period expressed
|
||||
as a multiple of the Time Grain. In our example, the Time Grain is day, so the rolling period is 7
|
||||
days, such that on the 7th October 2011 the value shown would correspond to the first seven days of
|
||||
October 2011. Lastly, by specifying Min Periods as 7, we ensure that our mean is always calculated
|
||||
on 7 days and we avoid any ramp up period.
|
||||
|
||||
After displaying the chart by selecting **Run Query** you will see that the data is less variable
|
||||
and that the series starts later as the ramp up period is excluded.
|
||||
|
||||
<img src={useBaseUrl("/img/tutorial/rolling_mean.png" )} />
|
||||
|
||||
Save the chart as Tutorial Rolling Mean and add it to the Tutorial Dashboard.
|
||||
|
||||
### Time Comparison
|
||||
|
||||
In this section, we will compare values in our time series to the value a week before. Start off by
|
||||
opening the Tutorial Advanced Analytics Base chart, by going to **Charts** in the top menu and then
|
||||
selecting the visualization name in the list (alternatively, find the chart in the Tutorial
|
||||
Dashboard and select Explore chart from the menu for that visualization).
|
||||
|
||||
Next, in the Time Comparison subsection of **Advanced Analytics**, enter the Time Shift by typing in
|
||||
“minus 1 week” (note this box accepts input in natural language). Run Query to see the new chart,
|
||||
which has an additional series with the same values, shifted a week back in time.
|
||||
|
||||
<img src={useBaseUrl("/img/tutorial/time_comparison_two_series.png" )} />
|
||||
|
||||
Then, change the **Calculation type** to Absolute difference and select **Run Query**. We can now
|
||||
see only one series again, this time showing the difference between the two series we saw
|
||||
previously.
|
||||
|
||||
<img src={useBaseUrl("/img/tutorial/time_comparison_absolute_difference.png" )} />
|
||||
|
||||
Save the chart as Tutorial Time Comparison and add it to the Tutorial Dashboard.
|
||||
|
||||
### Resampling the data
|
||||
|
||||
In this section, we’ll resample the data so that rather than having daily data we have weekly data.
|
||||
As in the previous section, reopen the Tutorial Advanced Analytics Base chart.
|
||||
|
||||
Next, in the Python Functions subsection of **Advanced Analytics**, enter 7D, corresponding to seven
|
||||
days, in the Rule and median as the Method and show the chart by selecting **Run Query**.
|
||||
|
||||
<img src={useBaseUrl("/img/tutorial/resample.png" )} />
|
||||
|
||||
Note that now we have a single data point every 7 days. In our case, the value showed corresponds to
|
||||
the median value within the seven daily data points. For more information on the meaning of the
|
||||
various options in this section, refer to the
|
||||
[Pandas documentation](https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.DataFrame.resample.html).
|
||||
|
||||
Lastly, save your chart as Tutorial Resample and add it to the Tutorial Dashboard. Go to the
|
||||
tutorial dashboard to see the four charts side by side and compare the different outputs.
|
||||
|
|
@ -0,0 +1,49 @@
|
|||
---
|
||||
title: API
|
||||
hide_title: true
|
||||
sidebar_position: 9
|
||||
---
|
||||
|
||||
import { Buffer } from "buffer";
|
||||
global.Buffer = Buffer;
|
||||
import SwaggerUI from "swagger-ui-react";
|
||||
import openapi from "/resources/openapi.json";
|
||||
import "swagger-ui-react/swagger-ui.css";
|
||||
// import { Alert } from "antd";
|
||||
|
||||
## API
|
||||
|
||||
Superset's public **REST API** follows the
|
||||
[OpenAPI specification](https://swagger.io/specification/), and is
|
||||
documented here. The docs bellow are generated using
|
||||
[Swagger React UI](https://www.npmjs.com/package/swagger-ui-react).
|
||||
|
||||
<!--
|
||||
TODO: (corbinrobb) Uncomment Alert if/when antd gets added and remove Infima alert. Fix SwaggerUI readability in dark mode.
|
||||
-->
|
||||
|
||||
<!-- <Alert
|
||||
type="info"
|
||||
message={
|
||||
|
||||
<div>
|
||||
<strong>NOTE! </strong>
|
||||
You can find an interactive version of this documentation on your local Superset
|
||||
instance at <strong>/swagger/v1</strong> (if enabled)
|
||||
</div>
|
||||
|
||||
}
|
||||
/> -->
|
||||
|
||||
<div class="alert alert--info" role="alert">
|
||||
<strong>NOTE! </strong>
|
||||
You can find an interactive version of this documentation on your local Superset
|
||||
instance at <strong>/swagger/v1</strong> (if enabled)
|
||||
</div>
|
||||
|
||||
<br />
|
||||
<br />
|
||||
<hr />
|
||||
<div className="swagger-container">
|
||||
<SwaggerUI spec={openapi} />
|
||||
</div>
|
||||
|
|
@ -0,0 +1,4 @@
|
|||
{
|
||||
"label": "Connecting to Databases",
|
||||
"position": 3
|
||||
}
|
||||
|
|
@ -0,0 +1,16 @@
|
|||
---
|
||||
title: Ascend.io
|
||||
hide_title: true
|
||||
sidebar_position: 10
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Ascend.io
|
||||
|
||||
The recommended connector library to Ascend.io is [impyla](https://github.com/cloudera/impyla).
|
||||
|
||||
The expected connection string is formatted as follows:
|
||||
|
||||
```
|
||||
ascend://{username}:{password}@{hostname}:{port}/{database}?auth_mechanism=PLAIN;use_ssl=true
|
||||
```
|
||||
|
|
@ -0,0 +1,34 @@
|
|||
---
|
||||
title: Amazon Athena
|
||||
hide_title: true
|
||||
sidebar_position: 4
|
||||
version: 1
|
||||
---
|
||||
|
||||
## AWS Athena
|
||||
|
||||
### PyAthenaJDBC
|
||||
|
||||
[PyAthenaJDBC](https://pypi.org/project/PyAthenaJDBC/) is a Python DB 2.0 compliant wrapper for the
|
||||
[Amazon Athena JDBC driver](https://docs.aws.amazon.com/athena/latest/ug/connect-with-jdbc.html).
|
||||
|
||||
The connection string for Amazon Athena is as follows:
|
||||
|
||||
```
|
||||
awsathena+jdbc://{aws_access_key_id}:{aws_secret_access_key}@athena.{region_name}.amazonaws.com/{schema_name}?s3_staging_dir={s3_staging_dir}&...
|
||||
```
|
||||
|
||||
Note that you'll need to escape & encode when forming the connection string like so:
|
||||
|
||||
```
|
||||
s3://... -> s3%3A//...
|
||||
```
|
||||
|
||||
### PyAthena
|
||||
|
||||
You can also use [PyAthena library](https://pypi.org/project/PyAthena/) (no Java required) with the
|
||||
following connection string:
|
||||
|
||||
```
|
||||
awsathena+rest://{aws_access_key_id}:{aws_secret_access_key}@athena.{region_name}.amazonaws.com/{schema_name}?s3_staging_dir={s3_staging_dir}&...
|
||||
```
|
||||
|
|
@ -0,0 +1,89 @@
|
|||
---
|
||||
title: Google BigQuery
|
||||
hide_title: true
|
||||
sidebar_position: 20
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Google BigQuery
|
||||
|
||||
The recommended connector library for BigQuery is
|
||||
[pybigquery](https://github.com/mxmzdlv/pybigquery).
|
||||
|
||||
### Install BigQuery Driver
|
||||
|
||||
Follow the steps [here](/docs/databases/dockeradddrivers) about how to
|
||||
install new database drivers when setting up Superset locally via docker-compose.
|
||||
|
||||
```
|
||||
echo "pybigquery" >> ./docker/requirements-local.txt
|
||||
```
|
||||
|
||||
### Connecting to BigQuery
|
||||
|
||||
When adding a new BigQuery connection in Superset, you'll need to add the GCP Service Account
|
||||
credentials file (as a JSON).
|
||||
|
||||
1. Create your Service Account via the Google Cloud Platform control panel, provide it access to the
|
||||
appropriate BigQuery datasets, and download the JSON configuration file for the service account.
|
||||
2. In Superset, you can either upload that JSON or add the JSON blob in the following format (this should be the content of your credential JSON file):
|
||||
|
||||
```
|
||||
{
|
||||
"type": "service_account",
|
||||
"project_id": "...",
|
||||
"private_key_id": "...",
|
||||
"private_key": "...",
|
||||
"client_email": "...",
|
||||
"client_id": "...",
|
||||
"auth_uri": "...",
|
||||
"token_uri": "...",
|
||||
"auth_provider_x509_cert_url": "...",
|
||||
"client_x509_cert_url": "..."
|
||||
}
|
||||
```
|
||||
|
||||
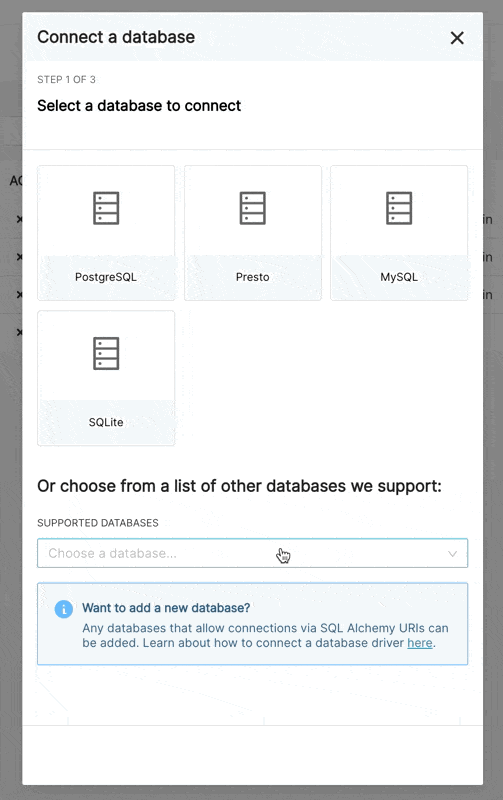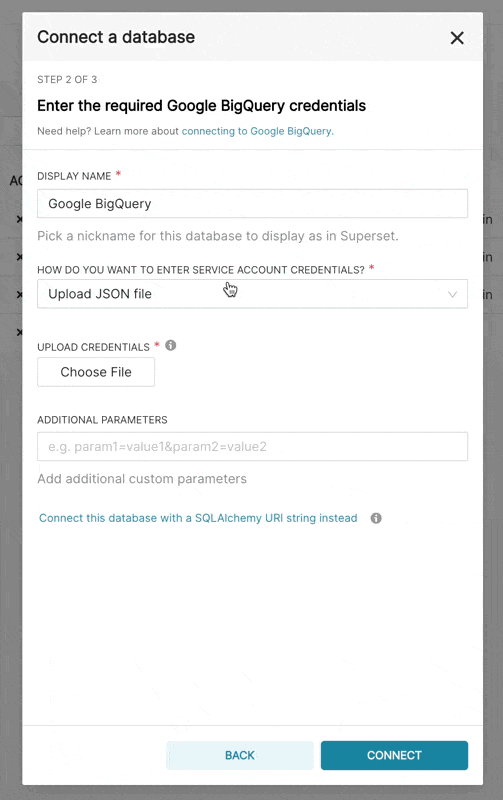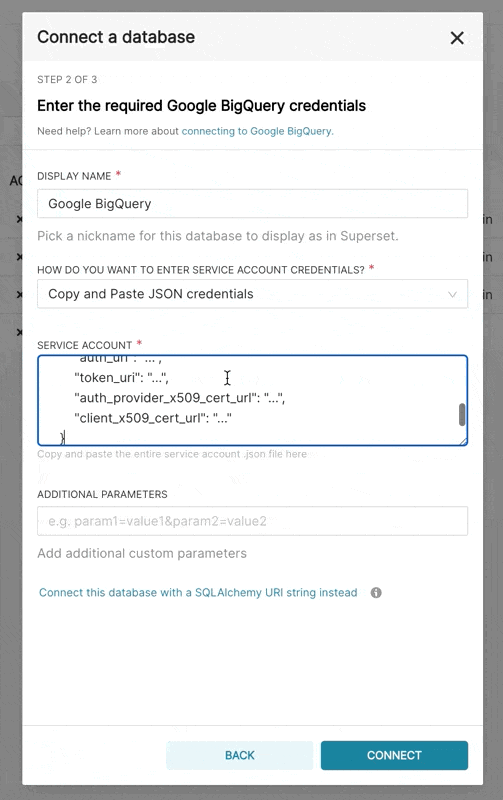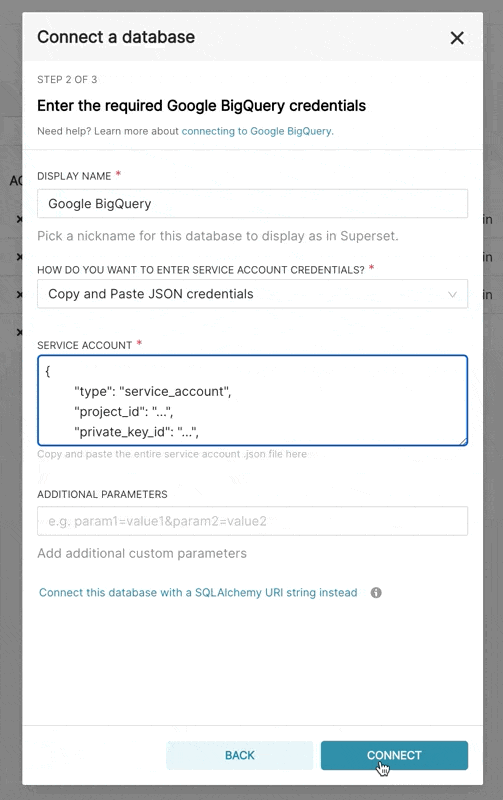
|
||||
|
||||
3. Additionally, can connect via SQLAlchemy URI instead
|
||||
|
||||
The connection string for BigQuery looks like:
|
||||
|
||||
```
|
||||
bigquery://{project_id}
|
||||
```
|
||||
|
||||
Go to the **Advanced** tab, Add a JSON blob to the **Secure Extra** field in the database configuration form with
|
||||
the following format:
|
||||
|
||||
```
|
||||
{
|
||||
"credentials_info": <contents of credentials JSON file>
|
||||
}
|
||||
```
|
||||
|
||||
The resulting file should have this structure:
|
||||
|
||||
```
|
||||
{
|
||||
"credentials_info": {
|
||||
"type": "service_account",
|
||||
"project_id": "...",
|
||||
"private_key_id": "...",
|
||||
"private_key": "...",
|
||||
"client_email": "...",
|
||||
"client_id": "...",
|
||||
"auth_uri": "...",
|
||||
"token_uri": "...",
|
||||
"auth_provider_x509_cert_url": "...",
|
||||
"client_x509_cert_url": "..."
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
You should then be able to connect to your BigQuery datasets.
|
||||
|
||||
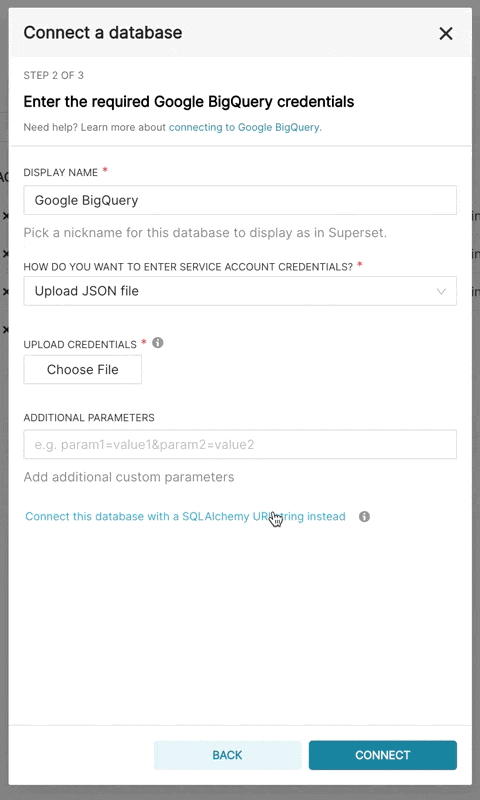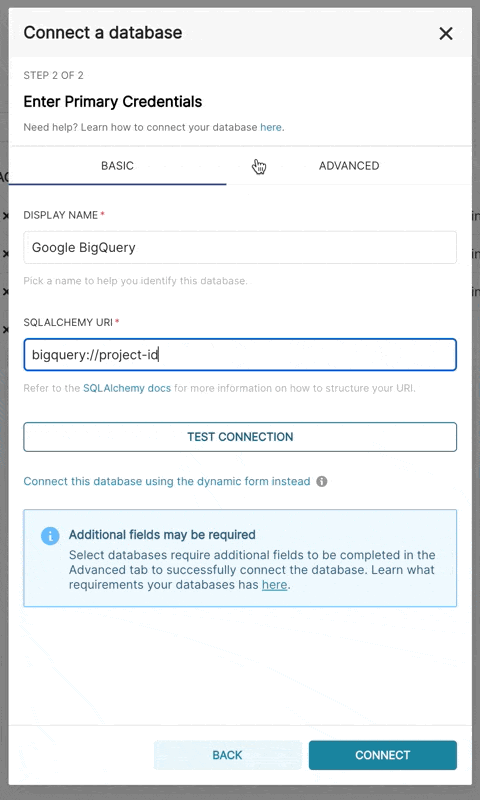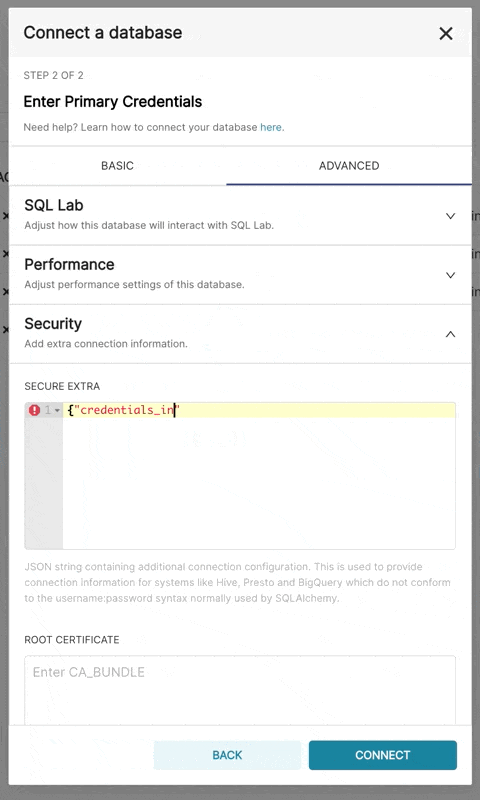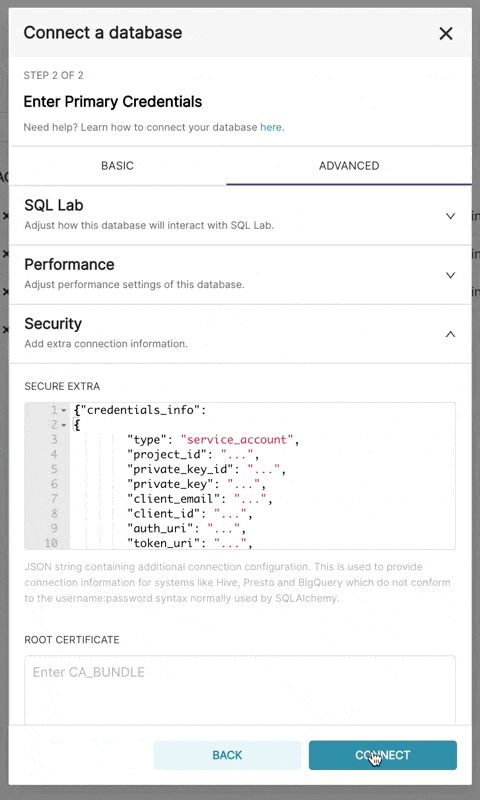
|
||||
|
||||
To be able to upload CSV or Excel files to BigQuery in Superset, you'll need to also add the
|
||||
[pandas_gbq](https://github.com/pydata/pandas-gbq) library.
|
||||
|
|
@ -0,0 +1,44 @@
|
|||
---
|
||||
title: Clickhouse
|
||||
hide_title: true
|
||||
sidebar_position: 15
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Clickhouse
|
||||
|
||||
To use Clickhouse with Superset, you will need to add the following Python libraries:
|
||||
|
||||
```
|
||||
clickhouse-driver==0.2.0
|
||||
clickhouse-sqlalchemy==0.1.6
|
||||
```
|
||||
|
||||
If running Superset using Docker Compose, add the following to your `./docker/requirements-local.txt` file:
|
||||
|
||||
```
|
||||
clickhouse-driver>=0.2.0
|
||||
clickhouse-sqlalchemy>=0.1.6
|
||||
```
|
||||
|
||||
The recommended connector library for Clickhouse is
|
||||
[sqlalchemy-clickhouse](https://github.com/cloudflare/sqlalchemy-clickhouse).
|
||||
|
||||
The expected connection string is formatted as follows:
|
||||
|
||||
```
|
||||
clickhouse+native://<user>:<password>@<host>:<port>/<database>[?options…]clickhouse://{username}:{password}@{hostname}:{port}/{database}
|
||||
```
|
||||
|
||||
Here's a concrete example of a real connection string:
|
||||
|
||||
```
|
||||
clickhouse+native://demo:demo@github.demo.trial.altinity.cloud/default?secure=true
|
||||
```
|
||||
|
||||
If you're using Clickhouse locally on your computer, you can get away with using a native protocol URL that
|
||||
uses the default user without a password (and doesn't encrypt the connection):
|
||||
|
||||
```
|
||||
clickhouse+native://localhost/default
|
||||
```
|
||||
|
|
@ -0,0 +1,17 @@
|
|||
---
|
||||
title: CockroachDB
|
||||
hide_title: true
|
||||
sidebar_position: 16
|
||||
version: 1
|
||||
---
|
||||
|
||||
## CockroachDB
|
||||
|
||||
The recommended connector library for CockroachDB is
|
||||
[sqlalchemy-cockroachdb](https://github.com/cockroachdb/sqlalchemy-cockroachdb).
|
||||
|
||||
The expected connection string is formatted as follows:
|
||||
|
||||
```
|
||||
cockroachdb://root@{hostname}:{port}/{database}?sslmode=disable
|
||||
```
|
||||
|
|
@ -0,0 +1,24 @@
|
|||
---
|
||||
title: CrateDB
|
||||
hide_title: true
|
||||
sidebar_position: 36
|
||||
version: 1
|
||||
---
|
||||
|
||||
## CrateDB
|
||||
|
||||
The recommended connector library for CrateDB is
|
||||
[crate](https://pypi.org/project/crate/).
|
||||
You need to install the extras as well for this library.
|
||||
We recommend adding something like the following
|
||||
text to your requirements file:
|
||||
|
||||
```
|
||||
crate[sqlalchemy]==0.26.0
|
||||
```
|
||||
|
||||
The expected connection string is formatted as follows:
|
||||
|
||||
```
|
||||
crate://crate@127.0.0.1:4200
|
||||
```
|
||||
|
|
@ -0,0 +1,67 @@
|
|||
---
|
||||
title: Databricks
|
||||
hide_title: true
|
||||
sidebar_position: 37
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Databricks
|
||||
|
||||
To connect to Databricks, first install [databricks-dbapi](https://pypi.org/project/databricks-dbapi/) with the optional SQLAlchemy dependencies:
|
||||
|
||||
```bash
|
||||
pip install databricks-dbapi[sqlalchemy]
|
||||
```
|
||||
|
||||
There are two ways to connect to Databricks: using a Hive connector or an ODBC connector. Both ways work similarly, but only ODBC can be used to connect to [SQL endpoints](https://docs.databricks.com/sql/admin/sql-endpoints.html).
|
||||
|
||||
### Hive
|
||||
|
||||
To use the Hive connector you need the following information from your cluster:
|
||||
|
||||
- Server hostname
|
||||
- Port
|
||||
- HTTP path
|
||||
|
||||
These can be found under "Configuration" -> "Advanced Options" -> "JDBC/ODBC".
|
||||
|
||||
You also need an access token from "Settings" -> "User Settings" -> "Access Tokens".
|
||||
|
||||
Once you have all this information, add a database of type "Databricks (Hive)" in Superset, and use the following SQLAlchemy URI:
|
||||
|
||||
```
|
||||
databricks+pyhive://token:{access token}@{server hostname}:{port}/{database name}
|
||||
```
|
||||
|
||||
You also need to add the following configuration to "Other" -> "Engine Parameters", with your HTTP path:
|
||||
|
||||
```
|
||||
{"connect_args": {"http_path": "sql/protocolv1/o/****"}}
|
||||
```
|
||||
|
||||
### ODBC
|
||||
|
||||
For ODBC you first need to install the [ODBC drivers for your platform](https://databricks.com/spark/odbc-drivers-download).
|
||||
|
||||
For a regular connection use this as the SQLAlchemy URI:
|
||||
|
||||
```
|
||||
databricks+pyodbc://token:{access token}@{server hostname}:{port}/{database name}
|
||||
```
|
||||
|
||||
And for the connection arguments:
|
||||
|
||||
```
|
||||
{"connect_args": {"http_path": "sql/protocolv1/o/****", "driver_path": "/path/to/odbc/driver"}}
|
||||
```
|
||||
|
||||
The driver path should be:
|
||||
|
||||
- `/Library/simba/spark/lib/libsparkodbc_sbu.dylib` (Mac OS)
|
||||
- `/opt/simba/spark/lib/64/libsparkodbc_sb64.so` (Linux)
|
||||
|
||||
For a connection to a SQL endpoint you need to use the HTTP path from the endpoint:
|
||||
|
||||
```
|
||||
{"connect_args": {"http_path": "/sql/1.0/endpoints/****", "driver_path": "/path/to/odbc/driver"}}
|
||||
```
|
||||
|
|
@ -0,0 +1,76 @@
|
|||
---
|
||||
title: Using Database Connection UI
|
||||
hide_title: true
|
||||
sidebar_position: 3
|
||||
version: 1
|
||||
---
|
||||
|
||||
Here is the documentation on how to leverage the new DB Connection UI. This will provide admins the ability to enhance the UX for users who want to connect to new databases.
|
||||
|
||||
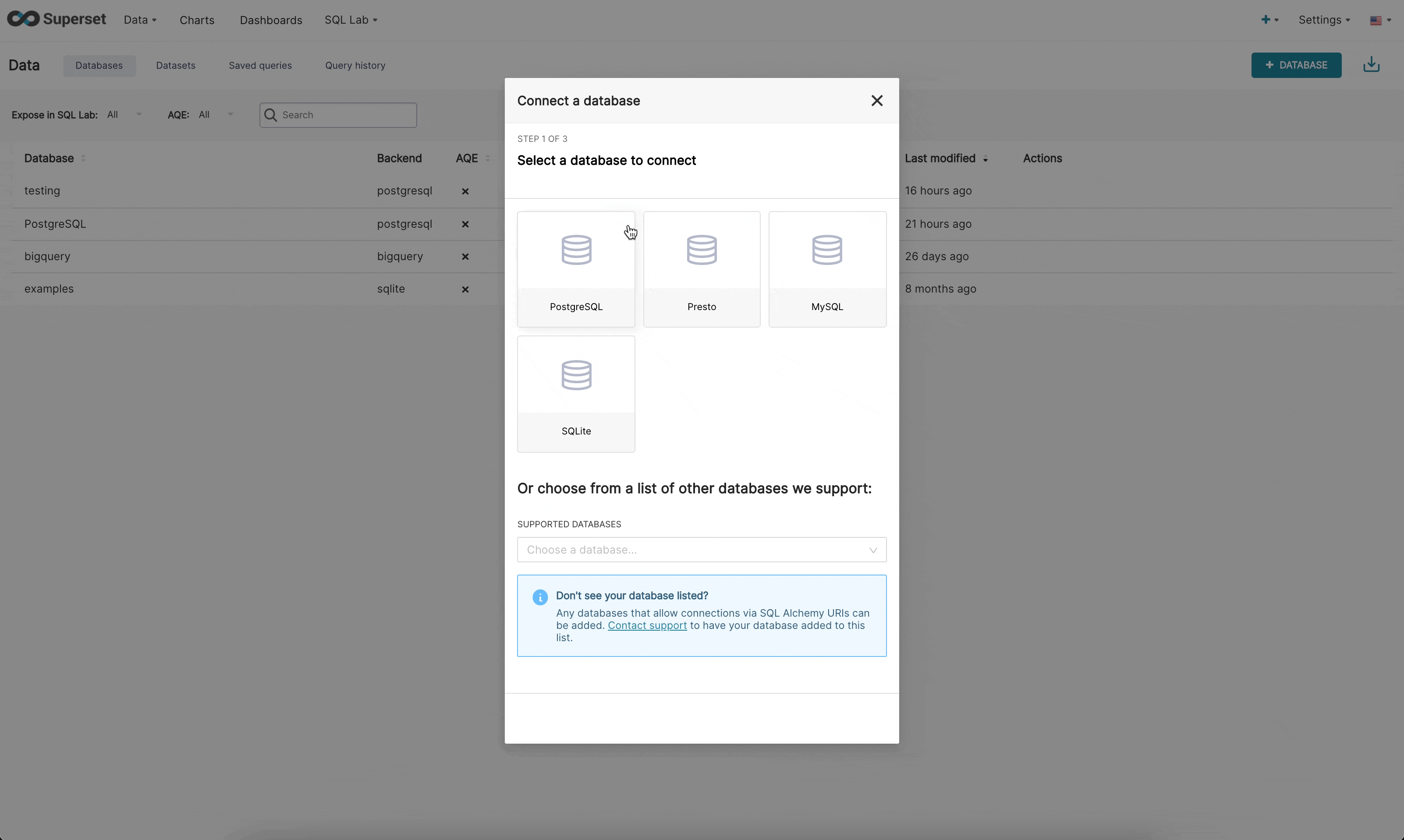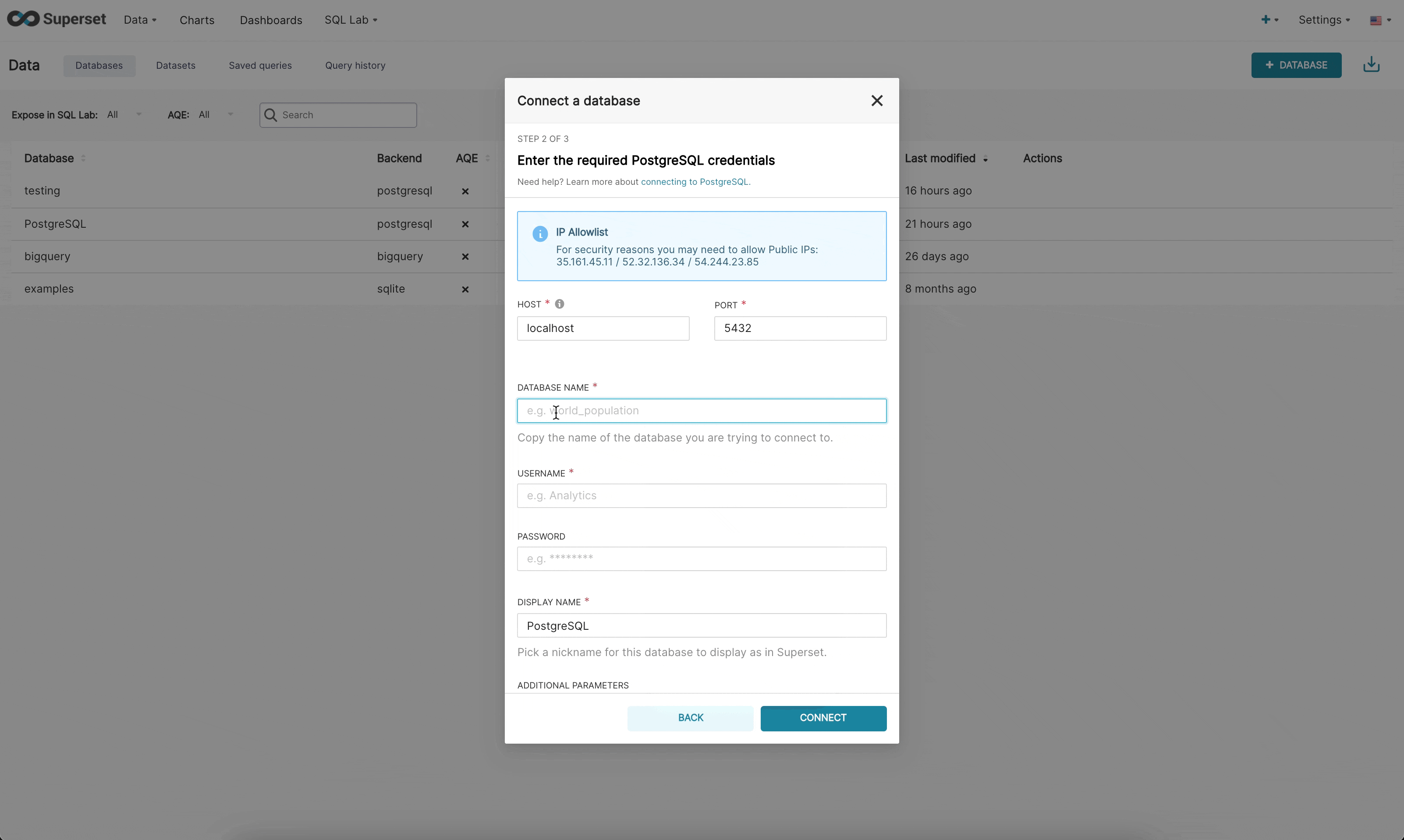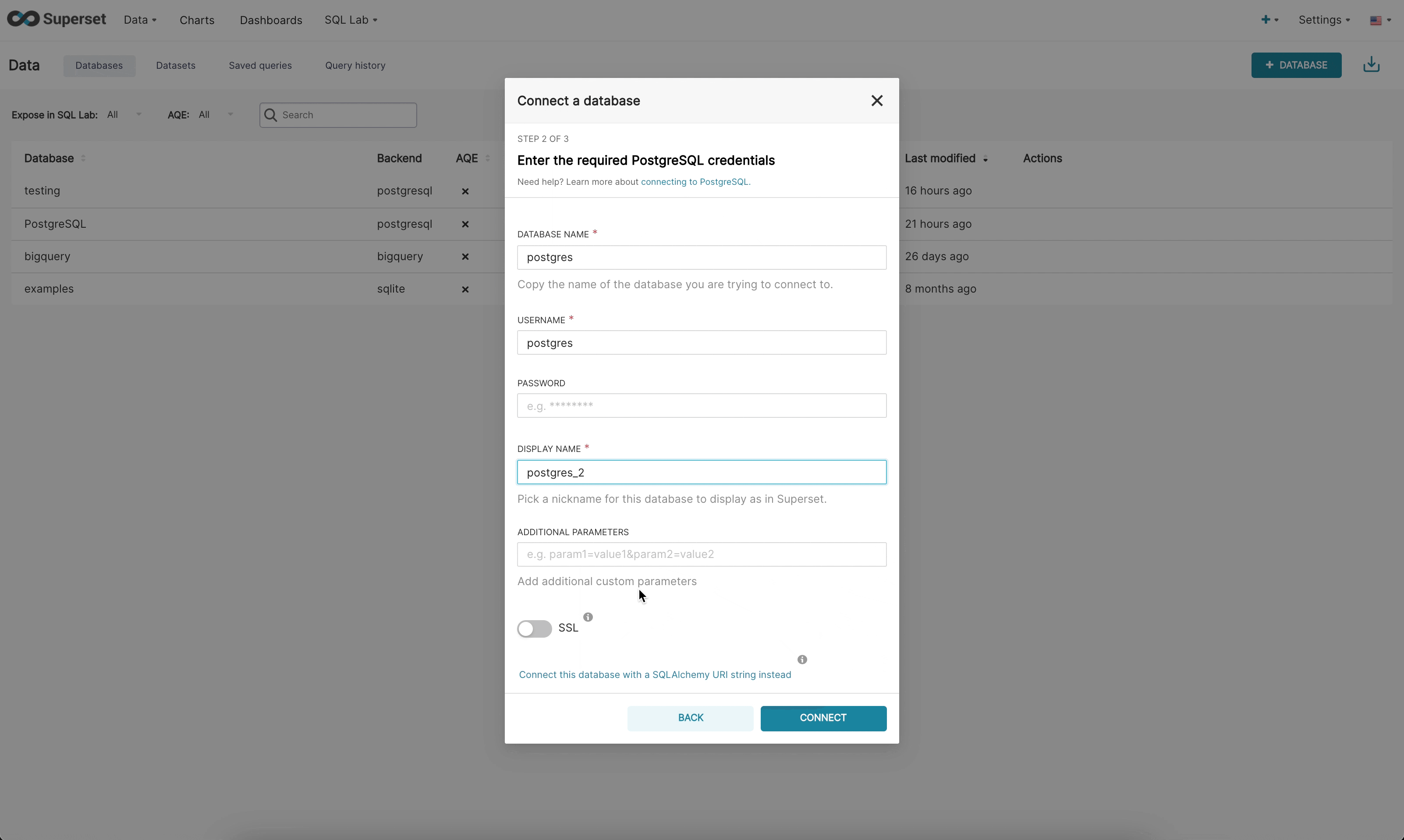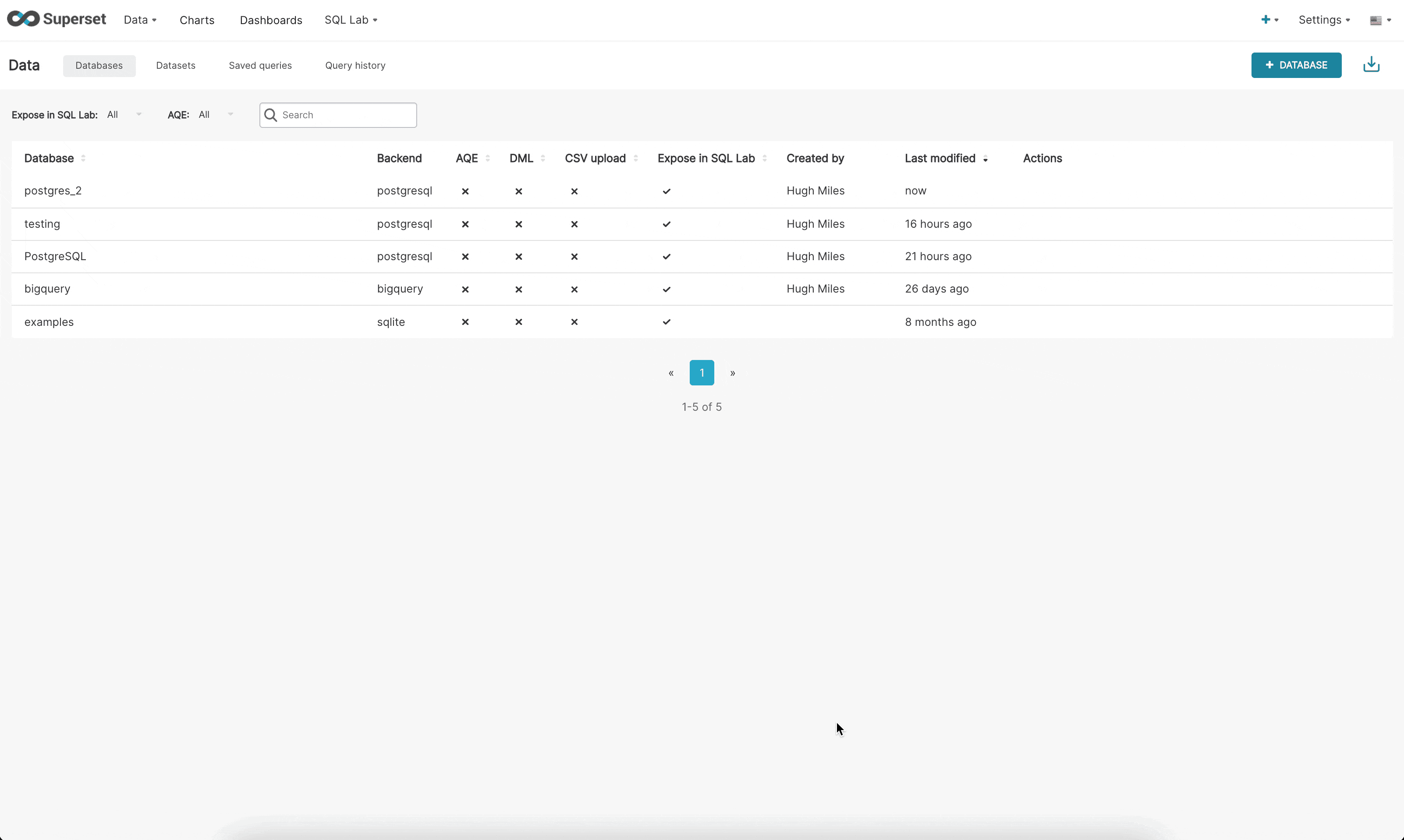
|
||||
|
||||
There are now 3 steps when connecting to a database in the new UI:
|
||||
|
||||
Step 1: First the admin must inform superset what engine they want to connect to. This page is powered by the `/available` endpoint which pulls on the engines currently installed in your environment, so that only supported databases are shown.
|
||||
|
||||
Step 2: Next, the admin is prompted to enter database specific parameters. Depending on whether there is a dynamic form available for that specific engine, the admin will either see the new custom form or the legacy SQLAlchemy form. We currently have built dynamic forms for (Redshift, MySQL, Postgres, and BigQuery). The new form prompts the user for the parameters needed to connect (for example, username, password, host, port, etc.) and provides immediate feedback on errors.
|
||||
|
||||
Step 3: Finally, once the admin has connected to their DB using the dynamic form they have the opportunity to update any optional advanced settings.
|
||||
|
||||
We hope this feature will help eliminate a huge bottleneck for users to get into the application and start crafting datasets.
|
||||
|
||||
### How to setup up preferred database options and images
|
||||
|
||||
We added a new configuration option where the admin can define their preferred databases, in order:
|
||||
|
||||
```python
|
||||
# A list of preferred databases, in order. These databases will be
|
||||
# displayed prominently in the "Add Database" dialog. You should
|
||||
# use the "engine_name" attribute of the corresponding DB engine spec
|
||||
# in `superset/db_engine_specs/`.
|
||||
PREFERRED_DATABASES: List[str] = [
|
||||
"PostgreSQL",
|
||||
"Presto",
|
||||
"MySQL",
|
||||
"SQLite",
|
||||
]
|
||||
```
|
||||
|
||||
For copyright reasons the logos for each database are not distributed with Superset.
|
||||
|
||||
### Setting images
|
||||
|
||||
- To set the images of your preferred database, admins must create a mapping in the `superset_text.yml` file with engine and location of the image. The image can be host locally inside your static/file directory or online (e.g. S3)
|
||||
|
||||
```python
|
||||
DB_IMAGES:
|
||||
postgresql: "path/to/image/postgres.jpg"
|
||||
bigquery: "path/to/s3bucket/bigquery.jpg"
|
||||
snowflake: "path/to/image/snowflake.jpg"
|
||||
```
|
||||
|
||||
### How to add new database engines to available endpoint
|
||||
|
||||
Currently the new modal supports the following databases:
|
||||
|
||||
- Postgres
|
||||
- Redshift
|
||||
- MySQL
|
||||
- BigQuery
|
||||
|
||||
When the user selects a database not in this list they will see the old dialog asking for the SQLAlchemy URI. New databases can be added gradually to the new flow. In order to support the rich configuration a DB engine spec needs to have the following attributes:
|
||||
|
||||
1. `parameters_schema`: a Marshmallow schema defining the parameters needed to configure the database. For Postgres this includes username, password, host, port, etc. ([see](https://github.com/apache/superset/blob/accee507c0819cd0d7bcfb5a3e1199bc81eeebf2/superset/db_engine_specs/base.py#L1309-L1320)).
|
||||
2. `default_driver`: the name of the recommended driver for the DB engine spec. Many SQLAlchemy dialects support multiple drivers, but usually one is the official recommendation. For Postgres we use "psycopg2".
|
||||
3. `sqlalchemy_uri_placeholder`: a string that helps the user in case they want to type the URI directly.
|
||||
4. `encryption_parameters`: parameters used to build the URI when the user opts for an encrypted connection. For Postgres this is `{"sslmode": "require"}`.
|
||||
|
||||
In addition, the DB engine spec must implement these class methods:
|
||||
|
||||
- `build_sqlalchemy_uri(cls, parameters, encrypted_extra)`: this method receives the distinct parameters and builds the URI from them.
|
||||
- `get_parameters_from_uri(cls, uri, encrypted_extra)`: this method does the opposite, extracting the parameters from a given URI.
|
||||
- `validate_parameters(cls, parameters)`: this method is used for `onBlur` validation of the form. It should return a list of `SupersetError` indicating which parameters are missing, and which parameters are definitely incorrect ([example](https://github.com/apache/superset/blob/accee507c0819cd0d7bcfb5a3e1199bc81eeebf2/superset/db_engine_specs/base.py#L1404)).
|
||||
|
||||
For databases like MySQL and Postgres that use the standard format of `engine+driver://user:password@host:port/dbname` all you need to do is add the `BasicParametersMixin` to the DB engine spec, and then define the parameters 2-4 (`parameters_schema` is already present in the mixin).
|
||||
|
||||
For other databases you need to implement these methods yourself. The BigQuery DB engine spec is a good example of how to do that.
|
||||
|
|
@ -0,0 +1,92 @@
|
|||
---
|
||||
title: Adding New Drivers in Docker
|
||||
hide_title: true
|
||||
sidebar_position: 2
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Adding New Database Drivers in Docker
|
||||
|
||||
Superset requires a Python database driver to be installed for each additional type of database you
|
||||
want to connect to. When setting up Superset locally via `docker-compose`, the drivers and packages
|
||||
contained in
|
||||
[requirements.txt](https://github.com/apache/superset/blob/master/requirements.txt) and
|
||||
[requirements-dev.txt](https://github.com/apache/superset/blob/master/requirements-dev.txt)
|
||||
will be installed automatically.
|
||||
|
||||
In this section, we'll walk through how to install the MySQL connector library. The connector
|
||||
library installation process is the same for all additional libraries and we'll end this section
|
||||
with the recommended connector library for each database.
|
||||
|
||||
### 1. Determine the driver you need
|
||||
|
||||
To figure out how to install the [database driver](/docs/databases/installing-database-drivers) of your choice.
|
||||
|
||||
In the example, we'll walk through the process of installing a MySQL driver in Superset.
|
||||
|
||||
### 2. Install MySQL Driver
|
||||
|
||||
As we are currently running inside of a Docker container via `docker compose`, we cannot simply run
|
||||
`pip install mysqlclient` on our local shell and expect the drivers to be installed within the
|
||||
Docker containers for superset.
|
||||
|
||||
In order to address this, the Superset `docker compose` setup comes with a mechanism for you to
|
||||
install packages locally, which will be ignored by Git for the purposes of local development. Please
|
||||
follow these steps:
|
||||
|
||||
Create `requirements-local.txt`
|
||||
|
||||
```
|
||||
# From the repo root...
|
||||
touch ./docker/requirements-local.txt
|
||||
```
|
||||
|
||||
Add the driver selected in step above:
|
||||
|
||||
```
|
||||
echo "mysqlclient" >> ./docker/requirements-local.txt
|
||||
```
|
||||
|
||||
Rebuild your local image with the new driver baked in:
|
||||
|
||||
```
|
||||
docker-compose build --force-rm
|
||||
```
|
||||
|
||||
After the rebuild of the Docker images is complete (which make take a few minutes) you can relaunch using the following command:
|
||||
|
||||
```
|
||||
docker-compose up
|
||||
```
|
||||
|
||||
The other option is to start Superset via Docker Compose is using the recipe in `docker-compose-non-dev.yml`, which will use pre-built frontend assets and skip the building of front-end assets:
|
||||
|
||||
```
|
||||
docker-compose -f docker-compose-non-dev.yml up
|
||||
```
|
||||
|
||||
### 3. Connect to MySQL
|
||||
|
||||
Now that you've got a MySQL driver installed locally, you should be able to test it out.
|
||||
|
||||
We can now create a Datasource in Superset that can be used to connect to a MySQL instance. Assuming
|
||||
your MySQL instance is running locally and can be accessed via localhost, use the following
|
||||
connection string in “SQL Alchemy URI”, by going to Sources > Databases > + icon (to add a new
|
||||
datasource) in Superset.
|
||||
|
||||
For Docker running in Linux:
|
||||
|
||||
```
|
||||
mysql://mysqluser:mysqluserpassword@localhost/example?charset=utf8
|
||||
```
|
||||
|
||||
For Docker running in OSX:
|
||||
|
||||
```
|
||||
mysql://mysqluser:mysqluserpassword@docker.for.mac.host.internal/example?charset=utf8
|
||||
```
|
||||
|
||||
Then click “Test Connection”, which should give you an “OK” message. If not, please look at your
|
||||
terminal for error messages, and reach out for help.
|
||||
|
||||
You can repeat this process for every database you want superset to be able to connect to.
|
||||
|
|
@ -0,0 +1,26 @@
|
|||
---
|
||||
title: Dremio
|
||||
hide_title: true
|
||||
sidebar_position: 17
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Dremio
|
||||
|
||||
The recommended connector library for Dremio is
|
||||
[sqlalchemy_dremio](https://pypi.org/project/sqlalchemy-dremio/).
|
||||
|
||||
The expected connection string for ODBC (Default port is 31010) is formatted as follows:
|
||||
|
||||
```
|
||||
dremio://{username}:{password}@{host}:{port}/{database_name}/dremio?SSL=1
|
||||
```
|
||||
|
||||
The expected connection string for Arrow Flight (Dremio 4.9.1+. Default port is 32010) is formatted as follows:
|
||||
|
||||
```
|
||||
dremio+flight://{username}:{password}@{host}:{port}/dremio
|
||||
```
|
||||
|
||||
This [blog post by Dremio](https://www.dremio.com/tutorials/dremio-apache-superset/) has some
|
||||
additional helpful instructions on connecting Superset to Dremio.
|
||||
|
|
@ -0,0 +1,47 @@
|
|||
---
|
||||
title: Apache Drill
|
||||
hide_title: true
|
||||
sidebar_position: 6
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Apache Drill
|
||||
|
||||
### SQLAlchemy
|
||||
|
||||
The recommended way to connect to Apache Drill is through SQLAlchemy. You can use the
|
||||
[sqlalchemy-drill](https://github.com/JohnOmernik/sqlalchemy-drill) package.
|
||||
|
||||
Once that is done, you can connect to Drill in two ways, either via the REST interface or by JDBC.
|
||||
If you are connecting via JDBC, you must have the Drill JDBC Driver installed.
|
||||
|
||||
The basic connection string for Drill looks like this:
|
||||
|
||||
```
|
||||
drill+sadrill://<username>:<password>@<host>:<port>/<storage_plugin>?use_ssl=True
|
||||
```
|
||||
|
||||
To connect to Drill running on a local machine running in embedded mode you can use the following
|
||||
connection string:
|
||||
|
||||
```
|
||||
drill+sadrill://localhost:8047/dfs?use_ssl=False
|
||||
```
|
||||
|
||||
### JDBC
|
||||
|
||||
Connecting to Drill through JDBC is more complicated and we recommend following
|
||||
[this tutorial](https://drill.apache.org/docs/using-the-jdbc-driver/).
|
||||
|
||||
The connection string looks like:
|
||||
|
||||
```
|
||||
drill+jdbc://<username>:<passsword>@<host>:<port>
|
||||
```
|
||||
|
||||
### ODBC
|
||||
|
||||
We recommend reading the
|
||||
[Apache Drill documentation](https://drill.apache.org/docs/installing-the-driver-on-linux/) and read
|
||||
the [Github README](https://github.com/JohnOmernik/sqlalchemy-drill#usage-with-odbc) to learn how to
|
||||
work with Drill through ODBC.
|
||||
|
|
@ -0,0 +1,65 @@
|
|||
---
|
||||
title: Apache Druid
|
||||
hide_title: true
|
||||
sidebar_position: 7
|
||||
version: 1
|
||||
---
|
||||
|
||||
import useBaseUrl from "@docusaurus/useBaseUrl";
|
||||
|
||||
## Apache Druid
|
||||
|
||||
A native connector to Druid ships with Superset (behind the `DRUID_IS_ACTIVE` flag) but this is
|
||||
slowly getting deprecated in favor of SQLAlchemy / DBAPI connector made available in the
|
||||
[pydruid library](https://pythonhosted.org/pydruid/).
|
||||
|
||||
The connection string looks like:
|
||||
|
||||
```
|
||||
druid://<User>:<password>@<Host>:<Port-default-9088>/druid/v2/sql
|
||||
```
|
||||
|
||||
### Customizing Druid Connection
|
||||
|
||||
When adding a connection to Druid, you can customize the connection a few different ways in the
|
||||
**Add Database** form.
|
||||
|
||||
**Custom Certificate**
|
||||
|
||||
You can add certificates in the **Root Certificate** field when configuring the new database
|
||||
connection to Druid:
|
||||
|
||||
<img src={useBaseUrl("/img/root-cert-example.png")} />{" "}
|
||||
|
||||
When using a custom certificate, pydruid will automatically use https scheme.
|
||||
|
||||
**Disable SSL Verification**
|
||||
|
||||
To disable SSL verification, add the following to the **Extras** field:
|
||||
|
||||
```
|
||||
engine_params:
|
||||
{"connect_args":
|
||||
{"scheme": "https", "ssl_verify_cert": false}}
|
||||
```
|
||||
|
||||
### Aggregations
|
||||
|
||||
Common aggregations or Druid metrics can be defined and used in Superset. The first and simpler use
|
||||
case is to use the checkbox matrix exposed in your datasource’s edit view (**Sources -> Druid
|
||||
Datasources -> [your datasource] -> Edit -> [tab] List Druid Column**).
|
||||
|
||||
Clicking the GroupBy and Filterable checkboxes will make the column appear in the related dropdowns
|
||||
while in the Explore view. Checking Count Distinct, Min, Max or Sum will result in creating new
|
||||
metrics that will appear in the **List Druid Metric** tab upon saving the datasource.
|
||||
|
||||
By editing these metrics, you’ll notice that their JSON element corresponds to Druid aggregation
|
||||
definition. You can create your own aggregations manually from the **List Druid Metric** tab
|
||||
following Druid documentation.
|
||||
|
||||
### Post-Aggregations
|
||||
|
||||
Druid supports post aggregation and this works in Superset. All you have to do is create a metric,
|
||||
much like you would create an aggregation manually, but specify `postagg` as a `Metric Type`. You
|
||||
then have to provide a valid json post-aggregation definition (as specified in the Druid docs) in
|
||||
the JSON field.
|
||||
|
|
@ -0,0 +1,68 @@
|
|||
---
|
||||
title: Elasticsearch
|
||||
hide_title: true
|
||||
sidebar_position: 18
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Elasticsearch
|
||||
|
||||
The recommended connector library for Elasticsearch is
|
||||
[elasticsearch-dbapi](https://github.com/preset-io/elasticsearch-dbapi).
|
||||
|
||||
The connection string for Elasticsearch looks like this:
|
||||
|
||||
```
|
||||
elasticsearch+http://{user}:{password}@{host}:9200/
|
||||
```
|
||||
|
||||
**Using HTTPS**
|
||||
|
||||
```
|
||||
elasticsearch+https://{user}:{password}@{host}:9200/
|
||||
```
|
||||
|
||||
Elasticsearch as a default limit of 10000 rows, so you can increase this limit on your cluster or
|
||||
set Superset’s row limit on config
|
||||
|
||||
```
|
||||
ROW_LIMIT = 10000
|
||||
```
|
||||
|
||||
You can query multiple indices on SQL Lab for example
|
||||
|
||||
```
|
||||
SELECT timestamp, agent FROM "logstash"
|
||||
```
|
||||
|
||||
But, to use visualizations for multiple indices you need to create an alias index on your cluster
|
||||
|
||||
```
|
||||
POST /_aliases
|
||||
{
|
||||
"actions" : [
|
||||
{ "add" : { "index" : "logstash-**", "alias" : "logstash_all" } }
|
||||
]
|
||||
}
|
||||
```
|
||||
|
||||
Then register your table with the alias name logstasg_all
|
||||
|
||||
**Time zone**
|
||||
|
||||
By default, Superset uses UTC time zone for elasticsearch query. If you need to specify a time zone,
|
||||
please edit your Database and enter the settings of your specified time zone in the Other > ENGINE PARAMETERS:
|
||||
|
||||
```
|
||||
{
|
||||
"connect_args": {
|
||||
"time_zone": "Asia/Shanghai"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
Another issue to note about the time zone problem is that before elasticsearch7.8, if you want to convert a string into a `DATETIME` object,
|
||||
you need to use the `CAST` function,but this function does not support our `time_zone` setting. So it is recommended to upgrade to the version after elasticsearch7.8.
|
||||
After elasticsearch7.8, you can use the `DATETIME_PARSE` function to solve this problem.
|
||||
The DATETIME_PARSE function is to support our `time_zone` setting, and here you need to fill in your elasticsearch version number in the Other > VERSION setting.
|
||||
the superset will use the `DATETIME_PARSE` function for conversion.
|
||||
|
|
@ -0,0 +1,17 @@
|
|||
---
|
||||
title: Exasol
|
||||
hide_title: true
|
||||
sidebar_position: 19
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Exasol
|
||||
|
||||
The recommended connector library for Exasol is
|
||||
[sqlalchemy-exasol](https://github.com/exasol/sqlalchemy-exasol).
|
||||
|
||||
The connection string for Exasol looks like this:
|
||||
|
||||
```
|
||||
exa+pyodbc://{username}:{password}@{hostname}:{port}/my_schema?CONNECTIONLCALL=en_US.UTF-8&driver=EXAODBC
|
||||
```
|
||||
|
|
@ -0,0 +1,69 @@
|
|||
---
|
||||
title: Extra Database Settings
|
||||
hide_title: true
|
||||
sidebar_position: 40
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Extra Database Settings
|
||||
|
||||
### Deeper SQLAlchemy Integration
|
||||
|
||||
It is possible to tweak the database connection information using the parameters exposed by
|
||||
SQLAlchemy. In the **Database edit** view, you can edit the **Extra** field as a JSON blob.
|
||||
|
||||
This JSON string contains extra configuration elements. The `engine_params` object gets unpacked
|
||||
into the `sqlalchemy.create_engine` call, while the `metadata_params` get unpacked into the
|
||||
`sqlalchemy.MetaData` call. Refer to the SQLAlchemy docs for more information.
|
||||
|
||||
### Schemas
|
||||
|
||||
Databases like Postgres and Redshift use the **schema** as the logical entity on top of the
|
||||
**database**. For Superset to connect to a specific schema, you can set the **schema** parameter in
|
||||
the **Edit Tables** form (Sources > Tables > Edit record).
|
||||
|
||||
### External Password Store for SQLAlchemy Connections
|
||||
|
||||
Superset can be configured to use an external store for database passwords. This is useful if you a
|
||||
running a custom secret distribution framework and do not wish to store secrets in Superset’s meta
|
||||
database.
|
||||
|
||||
Example: Write a function that takes a single argument of type `sqla.engine.url` and returns the
|
||||
password for the given connection string. Then set `SQLALCHEMY_CUSTOM_PASSWORD_STORE` in your config
|
||||
file to point to that function.
|
||||
|
||||
```python
|
||||
def example_lookup_password(url):
|
||||
secret = <<get password from external framework>>
|
||||
return 'secret'
|
||||
|
||||
SQLALCHEMY_CUSTOM_PASSWORD_STORE = example_lookup_password
|
||||
```
|
||||
|
||||
A common pattern is to use environment variables to make secrets available.
|
||||
`SQLALCHEMY_CUSTOM_PASSWORD_STORE` can also be used for that purpose.
|
||||
|
||||
```python
|
||||
def example_password_as_env_var(url):
|
||||
# assuming the uri looks like
|
||||
# mysql://localhost?superset_user:{SUPERSET_PASSWORD}
|
||||
return url.password.format(os.environ)
|
||||
|
||||
SQLALCHEMY_CUSTOM_PASSWORD_STORE = example_password_as_env_var
|
||||
```
|
||||
|
||||
### SSL Access to Databases
|
||||
|
||||
You can use the `Extra` field in the **Edit Databases** form to configure SSL:
|
||||
|
||||
```JSON
|
||||
{
|
||||
"metadata_params": {},
|
||||
"engine_params": {
|
||||
"connect_args":{
|
||||
"sslmode":"require",
|
||||
"sslrootcert": "/path/to/my/pem"
|
||||
}
|
||||
}
|
||||
}
|
||||
```
|
||||
|
|
@ -0,0 +1,23 @@
|
|||
---
|
||||
title: Firebird
|
||||
hide_title: true
|
||||
sidebar_position: 38
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Firebird
|
||||
|
||||
The recommended connector library for Firebird is [sqlalchemy-firebird](https://pypi.org/project/sqlalchemy-firebird/).
|
||||
Superset has been tested on `sqlalchemy-firebird>=0.7.0, <0.8`.
|
||||
|
||||
The recommended connection string is:
|
||||
|
||||
```
|
||||
firebird+fdb://{username}:{password}@{host}:{port}//{path_to_db_file}
|
||||
```
|
||||
|
||||
Here's a connection string example of Superset connecting to a local Firebird database:
|
||||
|
||||
```
|
||||
firebird+fdb://SYSDBA:masterkey@192.168.86.38:3050//Library/Frameworks/Firebird.framework/Versions/A/Resources/examples/empbuild/employee.fdb
|
||||
```
|
||||
|
|
@ -0,0 +1,27 @@
|
|||
---
|
||||
title: Firebolt
|
||||
hide_title: true
|
||||
sidebar_position: 39
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Firebolt
|
||||
|
||||
The recommended connector library for Firebolt is [firebolt-sqlalchemy](https://pypi.org/project/firebolt-sqlalchemy/).
|
||||
Superset has been tested on `firebolt-sqlalchemy>=0.0.1`.
|
||||
|
||||
The recommended connection string is:
|
||||
|
||||
```
|
||||
firebolt://{username}:{password}@{database}
|
||||
or
|
||||
firebolt://{username}:{password}@{database}/{engine_name}
|
||||
```
|
||||
|
||||
Here's a connection string example of Superset connecting to a Firebolt database:
|
||||
|
||||
```
|
||||
firebolt://email@domain:password@sample_database
|
||||
or
|
||||
firebolt://email@domain:password@sample_database/sample_engine
|
||||
```
|
||||
|
|
@ -0,0 +1,16 @@
|
|||
---
|
||||
title: Google Sheets
|
||||
hide_title: true
|
||||
sidebar_position: 21
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Google Sheets
|
||||
|
||||
Google Sheets has a very limited
|
||||
[SQL API](https://developers.google.com/chart/interactive/docs/querylanguage). The recommended
|
||||
connector library for Google Sheets is [shillelagh](https://github.com/betodealmeida/shillelagh).
|
||||
|
||||
There are a few steps involved in connecting Superset to Google Sheets. This
|
||||
[tutorial](https://preset.io/blog/2020-06-01-connect-superset-google-sheets/) has the most up to date
|
||||
instructions on setting up this connection.
|
||||
|
|
@ -0,0 +1,16 @@
|
|||
---
|
||||
title: Hana
|
||||
hide_title: true
|
||||
sidebar_position: 22
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Hana
|
||||
|
||||
The recommended connector library is [sqlalchemy-hana](https://github.com/SAP/sqlalchemy-hana).
|
||||
|
||||
The connection string is formatted as follows:
|
||||
|
||||
```
|
||||
hana://{username}:{password}@{host}:{port}
|
||||
```
|
||||
|
|
@ -0,0 +1,16 @@
|
|||
---
|
||||
title: Apache Hive
|
||||
hide_title: true
|
||||
sidebar_position: 8
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Apache Hive
|
||||
|
||||
The [pyhive](https://pypi.org/project/PyHive/) library is the recommended way to connect to Hive through SQLAlchemy.
|
||||
|
||||
The expected connection string is formatted as follows:
|
||||
|
||||
```
|
||||
hive://hive@{hostname}:{port}/{database}
|
||||
```
|
||||
|
|
@ -0,0 +1,24 @@
|
|||
---
|
||||
title: Hologres
|
||||
hide_title: true
|
||||
sidebar_position: 33
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Hologres
|
||||
|
||||
Hologres is a real-time interactive analytics service developed by Alibaba Cloud. It is fully compatible with PostgreSQL 11 and integrates seamlessly with the big data ecosystem.
|
||||
|
||||
Hologres sample connection parameters:
|
||||
|
||||
- **User Name**: The AccessKey ID of your Alibaba Cloud account.
|
||||
- **Password**: The AccessKey secret of your Alibaba Cloud account.
|
||||
- **Database Host**: The public endpoint of the Hologres instance.
|
||||
- **Database Name**: The name of the Hologres database.
|
||||
- **Port**: The port number of the Hologres instance.
|
||||
|
||||
The connection string looks like:
|
||||
|
||||
```
|
||||
postgresql+psycopg2://{username}:{password}@{host}:{port}/{database}
|
||||
```
|
||||
|
|
@ -0,0 +1,23 @@
|
|||
---
|
||||
title: IBM DB2
|
||||
hide_title: true
|
||||
sidebar_position: 23
|
||||
version: 1
|
||||
---
|
||||
|
||||
## IBM DB2
|
||||
|
||||
The [IBM_DB_SA](https://github.com/ibmdb/python-ibmdbsa/tree/master/ibm_db_sa) library provides a
|
||||
Python / SQLAlchemy interface to IBM Data Servers.
|
||||
|
||||
Here's the recommended connection string:
|
||||
|
||||
```
|
||||
db2+ibm_db://{username}:{passport}@{hostname}:{port}/{database}
|
||||
```
|
||||
|
||||
There are two DB2 dialect versions implemented in SQLAlchemy. If you are connecting to a DB2 version without `LIMIT [n]` syntax, the recommended connection string to be able to use the SQL Lab is:
|
||||
|
||||
```
|
||||
ibm_db_sa://{username}:{passport}@{hostname}:{port}/{database}
|
||||
```
|
||||
|
|
@ -0,0 +1,16 @@
|
|||
---
|
||||
title: Apache Impala
|
||||
hide_title: true
|
||||
sidebar_position: 9
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Apache Impala
|
||||
|
||||
The recommended connector library to Apache Hive is [impyla](https://github.com/cloudera/impyla).
|
||||
|
||||
The expected connection string is formatted as follows:
|
||||
|
||||
```
|
||||
impala://{hostname}:{port}/{database}
|
||||
```
|
||||
|
|
@ -0,0 +1,73 @@
|
|||
---
|
||||
title: Installing Database Drivers
|
||||
hide_title: true
|
||||
sidebar_position: 1
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Install Database Drivers
|
||||
|
||||
Superset requires a Python DB-API database driver and a SQLAlchemy
|
||||
dialect to be installed for each datastore you want to connect to.
|
||||
|
||||
You can read more [here](/docs/databases/dockeradddrivers) about how to
|
||||
install new database drivers into your Superset configuration.
|
||||
|
||||
### Supported Databases and Dependencies
|
||||
|
||||
Superset does not ship bundled with connectivity to databases, except for SQLite,
|
||||
which is part of the Python standard library. You’ll need to install the required packages for the database you want to use as your metadata database as well as the packages needed to connect to the databases you want to access through Superset.
|
||||
|
||||
A list of some of the recommended packages.
|
||||
|
||||
| Database | PyPI package | Connection String |
|
||||
| --------------------------------------------------------- | ---------------------------------------------------------------------------------- | ----------------------------------------------------------------------------------------------------------- |
|
||||
| [Amazon Athena](/docs/databases/athena) | `pip install "PyAthenaJDBC>1.0.9` , `pip install "PyAthena>1.2.0` | `awsathena+rest://{aws_access_key_id}:{aws_secret_access_key}@athena.{region_name}.amazonaws.com/{ ` |
|
||||
| [Amazon Redshift](/docs/databases/redshift) | `pip install sqlalchemy-redshift` | ` redshift+psycopg2://<userName>:<DBPassword>@<AWS End Point>:5439/<Database Name>` |
|
||||
| [Apache Drill](/docs/databases/drill) | `pip install sqlalchemy-drill` | `drill+sadrill:// For JDBC drill+jdbc://` |
|
||||
| [Apache Druid](/docs/databases/druid) | `pip install pydruid` | `druid://<User>:<password>@<Host>:<Port-default-9088>/druid/v2/sql` |
|
||||
| [Apache Hive](/docs/databases/hive) | `pip install pyhive` | `hive://hive@{hostname}:{port}/{database}` |
|
||||
| [Apache Impala](/docs/databases/impala) | `pip install impyla` | `impala://{hostname}:{port}/{database}` |
|
||||
| [Apache Kylin](/docs/databases/kylin) | `pip install kylinpy` | `kylin://<username>:<password>@<hostname>:<port>/<project>?<param1>=<value1>&<param2>=<value2>` |
|
||||
| [Apache Pinot](/docs/databases/pinot) | `pip install pinotdb` | `pinot://BROKER:5436/query?server=http://CONTROLLER:5983/` |
|
||||
| [Apache Solr](/docs/databases/solr) | `pip install sqlalchemy-solr` | `solr://{username}:{password}@{hostname}:{port}/{server_path}/{collection}` |
|
||||
| [Apache Spark SQL](/docs/databases/spark-sql) | `pip install pyhive` | `hive://hive@{hostname}:{port}/{database}` |
|
||||
| [Ascend.io](/docs/databases/ascend) | `pip install impyla` | `ascend://{username}:{password}@{hostname}:{port}/{database}?auth_mechanism=PLAIN;use_ssl=true` |
|
||||
| [Azure MS SQL](/docs/databases/sql-server) | `pip install pymssql` | `mssql+pymssql://UserName@presetSQL:TestPassword@presetSQL.database.windows.net:1433/TestSchema` |
|
||||
| [Big Query](/docs/databases/bigquery) | `pip install pybigquery` | `bigquery://{project_id}` |
|
||||
| [ClickHouse](/docs/databases/clickhouse) | `pip install clickhouse-driver==0.2.0 && pip install clickhouse-sqlalchemy==0.1.6` | `clickhouse+native://{username}:{password}@{hostname}:{port}/{database}` |
|
||||
| [CockroachDB](/docs/databases/cockroachdb) | `pip install cockroachdb` | `cockroachdb://root@{hostname}:{port}/{database}?sslmode=disable` |
|
||||
| [Dremio](/docs/databases/dremio) | `pip install sqlalchemy_dremio` | `dremio://user:pwd@host:31010/` |
|
||||
| [Elasticsearch](/docs/databases/elasticsearch) | `pip install elasticsearch-dbapi` | `elasticsearch+http://{user}:{password}@{host}:9200/` |
|
||||
| [Exasol](/docs/databases/exasol) | `pip install sqlalchemy-exasol` | `exa+pyodbc://{username}:{password}@{hostname}:{port}/my_schema?CONNECTIONLCALL=en_US.UTF-8&driver=EXAODBC` |
|
||||
| [Google Sheets](/docs/databases/google-sheets) | `pip install shillelagh[gsheetsapi]` | `gsheets://` |
|
||||
| [Firebolt](/docs/databases/firebolt) | `pip install firebolt-sqlalchemy` | `firebolt://{username}:{password}@{database} or firebolt://{username}:{password}@{database}/{engine_name}` |
|
||||
| [Hologres](/docs/databases/hologres) | `pip install psycopg2` | `postgresql+psycopg2://<UserName>:<DBPassword>@<Database Host>/<Database Name>` |
|
||||
| [IBM Db2](/docs/databases/ibm-db2) | `pip install ibm_db_sa` | `db2+ibm_db://` |
|
||||
| [IBM Netezza Performance Server](/docs/databases/netezza) | `pip install nzalchemy` | `netezza+nzpy://<UserName>:<DBPassword>@<Database Host>/<Database Name>` |
|
||||
| [MySQL](/docs/databases/mysql) | `pip install mysqlclient` | `mysql://<UserName>:<DBPassword>@<Database Host>/<Database Name>` |
|
||||
| [Oracle](/docs/databases/oracle) | `pip install cx_Oracle` | `oracle://` |
|
||||
| [PostgreSQL](/docs/databases/postgres) | `pip install psycopg2` | `postgresql://<UserName>:<DBPassword>@<Database Host>/<Database Name>` |
|
||||
| [Trino](/docs/databases/trino) | `pip install sqlalchemy-trino` | `trino://{username}:{password}@{hostname}:{port}/{catalog}` |
|
||||
| [Presto](/docs/databases/presto) | `pip install pyhive` | `presto://` |
|
||||
| [SAP Hana](/docs/databases/hana) | `pip install hdbcli sqlalchemy-hana or pip install apache-superset[hana]` | `hana://{username}:{password}@{host}:{port}` |
|
||||
| [Snowflake](/docs/databases/snowflake) | `pip install snowflake-sqlalchemy` | `snowflake://{user}:{password}@{account}.{region}/{database}?role={role}&warehouse={warehouse}` |
|
||||
| SQLite | | `sqlite://` |
|
||||
| [SQL Server](/docs/databases/sql-server) | `pip install pymssql` | `mssql://` |
|
||||
| [Teradata](/docs/databases/teradata) | `pip install sqlalchemy-teradata` | `teradata://{user}:{password}@{host}` |
|
||||
| [Vertica](/docs/databases/vertica) | `pip install sqlalchemy-vertica-python` | `vertica+vertica_python://<UserName>:<DBPassword>@<Database Host>/<Database Name>` |
|
||||
|
||||
---
|
||||
|
||||
Note that many other databases are supported, the main criteria being the existence of a functional
|
||||
SQLAlchemy dialect and Python driver. Searching for the keyword "sqlalchemy + (database name)"
|
||||
should help get you to the right place.
|
||||
|
||||
If your database or data engine isn't on the list but a SQL interface
|
||||
exists, please file an issue on the
|
||||
[Superset GitHub repo](https://github.com/apache/superset/issues), so we can work on documenting and
|
||||
supporting it.
|
||||
|
||||
[StackOverflow](https://stackoverflow.com/questions/tagged/apache-superset+superset) and the
|
||||
[Superset community Slack](https://join.slack.com/t/apache-superset/shared_invite/zt-uxbh5g36-AISUtHbzOXcu0BIj7kgUaw)
|
||||
are great places to get help with connecting to databases in Superset.
|
||||
|
|
@ -0,0 +1,17 @@
|
|||
---
|
||||
title: Apache Kylin
|
||||
hide_title: true
|
||||
sidebar_position: 11
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Apache Kylin
|
||||
|
||||
The recommended connector library for Apache Kylin is
|
||||
[kylinpy](https://github.com/Kyligence/kylinpy).
|
||||
|
||||
The expected connection string is formatted as follows:
|
||||
|
||||
```
|
||||
kylin://<username>:<password>@<hostname>:<port>/<project>?<param1>=<value1>&<param2>=<value2>
|
||||
```
|
||||
|
|
@ -0,0 +1,29 @@
|
|||
---
|
||||
title: MySQL
|
||||
hide_title: true
|
||||
sidebar_position: 25
|
||||
version: 1
|
||||
---
|
||||
|
||||
## MySQL
|
||||
|
||||
The recommended connector library for MySQL is `[mysqlclient](https://pypi.org/project/mysqlclient/)`.
|
||||
|
||||
Here's the connection string:
|
||||
|
||||
```
|
||||
mysql://{username}:{password}@{host}/{database}
|
||||
```
|
||||
|
||||
Host:
|
||||
|
||||
- For Localhost or Docker running Linux: `localhost` or `127.0.0.1`
|
||||
- For On Prem: IP address or Host name
|
||||
- For Docker running in OSX: `docker.for.mac.host.internal`
|
||||
Port: `3306` by default
|
||||
|
||||
One problem with `mysqlclient` is that it will fail to connect to newer MySQL databases using `caching_sha2_password` for authentication, since the plugin is not included in the client. In this case, you should use `[mysql-connector-python](https://pypi.org/project/mysql-connector-python/)` instead:
|
||||
|
||||
```
|
||||
mysql+mysqlconnector://{username}:{password}@{host}/{database}
|
||||
```
|
||||
|
|
@ -0,0 +1,17 @@
|
|||
---
|
||||
title: IBM Netezza Performance Server
|
||||
hide_title: true
|
||||
sidebar_position: 24
|
||||
version: 1
|
||||
---
|
||||
|
||||
## IBM Netezza Performance Server
|
||||
|
||||
The [nzalchemy](https://pypi.org/project/nzalchemy/) library provides a
|
||||
Python / SQLAlchemy interface to IBM Netezza Performance Server (aka Netezza).
|
||||
|
||||
Here's the recommended connection string:
|
||||
|
||||
```
|
||||
netezza+nzpy://{username}:{password}@{hostname}:{port}/{database}
|
||||
```
|
||||
|
|
@ -0,0 +1,17 @@
|
|||
---
|
||||
title: Oracle
|
||||
hide_title: true
|
||||
sidebar_position: 26
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Oracle
|
||||
|
||||
The recommended connector library is
|
||||
[cx_Oracle](https://cx-oracle.readthedocs.io/en/latest/user_guide/installation.html).
|
||||
|
||||
The connection string is formatted as follows:
|
||||
|
||||
```
|
||||
oracle://<username>:<password>@<hostname>:<port>
|
||||
```
|
||||
|
|
@ -0,0 +1,16 @@
|
|||
---
|
||||
title: Apache Pinot
|
||||
hide_title: true
|
||||
sidebar_position: 12
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Apache Pinot
|
||||
|
||||
The recommended connector library for Apache Pinot is [pinotdb](https://pypi.org/project/pinotdb/).
|
||||
|
||||
The expected connection string is formatted as follows:
|
||||
|
||||
```
|
||||
pinot+http://controller:5436/query?server=http://controller:5983/``
|
||||
```
|
||||
|
|
@ -0,0 +1,42 @@
|
|||
---
|
||||
title: Postgres
|
||||
hide_title: true
|
||||
sidebar_position: 27
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Postgres
|
||||
|
||||
Note that, if you're using docker-compose, the Postgres connector library [psycopg2](https://www.psycopg.org/docs/)
|
||||
comes out of the box with Superset.
|
||||
|
||||
Postgres sample connection parameters:
|
||||
|
||||
- **User Name**: UserName
|
||||
- **Password**: DBPassword
|
||||
- **Database Host**:
|
||||
- For Localhost: localhost or 127.0.0.1
|
||||
- For On Prem: IP address or Host name
|
||||
- For AWS Endpoint
|
||||
- **Database Name**: Database Name
|
||||
- **Port**: default 5432
|
||||
|
||||
The connection string looks like:
|
||||
|
||||
```
|
||||
postgresql://{username}:{password}@{host}:{port}/{database}
|
||||
```
|
||||
|
||||
You can require SSL by adding `?sslmode=require` at the end:
|
||||
|
||||
```
|
||||
postgresql://{username}:{password}@{host}:{port}/{database}?sslmode=require
|
||||
```
|
||||
|
||||
You can read about the other SSL modes that Postgres supports in
|
||||
[Table 31-1 from this documentation](https://www.postgresql.org/docs/9.1/libpq-ssl.html).
|
||||
|
||||
More information about PostgreSQL connection options can be found in the
|
||||
[SQLAlchemy docs](https://docs.sqlalchemy.org/en/13/dialects/postgresql.html#module-sqlalchemy.dialects.postgresql.psycopg2)
|
||||
and the
|
||||
[PostgreSQL docs](https://www.postgresql.org/docs/9.1/libpq-connect.html#LIBPQ-PQCONNECTDBPARAMS).
|
||||
|
|
@ -0,0 +1,37 @@
|
|||
---
|
||||
title: Presto
|
||||
hide_title: true
|
||||
sidebar_position: 28
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Presto
|
||||
|
||||
The [pyhive](https://pypi.org/project/PyHive/) library is the recommended way to connect to Presto through SQLAlchemy.
|
||||
|
||||
The expected connection string is formatted as follows:
|
||||
|
||||
```
|
||||
presto://{hostname}:{port}/{database}
|
||||
```
|
||||
|
||||
You can pass in a username and password as well:
|
||||
|
||||
```
|
||||
presto://{username}:{password}@{hostname}:{port}/{database}
|
||||
```
|
||||
|
||||
Here is an example connection string with values:
|
||||
|
||||
```
|
||||
presto://datascientist:securepassword@presto.example.com:8080/hive
|
||||
```
|
||||
|
||||
By default Superset assumes the most recent version of Presto is being used when querying the
|
||||
datasource. If you’re using an older version of Presto, you can configure it in the extra parameter:
|
||||
|
||||
```
|
||||
{
|
||||
"version": "0.123"
|
||||
}
|
||||
```
|
||||
|
|
@ -0,0 +1,25 @@
|
|||
---
|
||||
title: Amazon Redshift
|
||||
hide_title: true
|
||||
sidebar_position: 5
|
||||
version: 1
|
||||
---
|
||||
|
||||
## AWS Redshift
|
||||
|
||||
The [sqlalchemy-redshift](https://pypi.org/project/sqlalchemy-redshift/) library is the recommended
|
||||
way to connect to Redshift through SQLAlchemy.
|
||||
|
||||
You'll need to the following setting values to form the connection string:
|
||||
|
||||
- **User Name**: userName
|
||||
- **Password**: DBPassword
|
||||
- **Database Host**: AWS Endpoint
|
||||
- **Database Name**: Database Name
|
||||
- **Port**: default 5439
|
||||
|
||||
Here's what the connection string looks like:
|
||||
|
||||
```
|
||||
redshift+psycopg2://<userName>:<DBPassword>@<AWS End Point>:5439/<Database Name>
|
||||
```
|
||||
|
|
@ -0,0 +1,16 @@
|
|||
---
|
||||
title: Rockset
|
||||
hide_title: true
|
||||
sidebar_position: 35
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Rockset
|
||||
|
||||
The connection string for Rockset is:
|
||||
|
||||
```
|
||||
rockset://apikey:{your-apikey}@api.rs2.usw2.rockset.com/
|
||||
```
|
||||
|
||||
For more complete instructions, we recommend the [Rockset documentation](https://docs.rockset.com/apache-superset/).
|
||||
|
|
@ -0,0 +1,31 @@
|
|||
---
|
||||
title: Snowflake
|
||||
hide_title: true
|
||||
sidebar_position: 29
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Snowflake
|
||||
|
||||
The recommended connector library for Snowflake is
|
||||
[snowflake-sqlalchemy](https://pypi.org/project/snowflake-sqlalchemy/1.2.4/)<=1.2.4. (This version is required until Superset migrates to sqlalchemy>=1.4.0)
|
||||
|
||||
The connection string for Snowflake looks like this:
|
||||
|
||||
```
|
||||
snowflake://{user}:{password}@{account}.{region}/{database}?role={role}&warehouse={warehouse}
|
||||
```
|
||||
|
||||
The schema is not necessary in the connection string, as it is defined per table/query. The role and
|
||||
warehouse can be omitted if defaults are defined for the user, i.e.
|
||||
|
||||
```
|
||||
snowflake://{user}:{password}@{account}.{region}/{database}
|
||||
```
|
||||
|
||||
Make sure the user has privileges to access and use all required
|
||||
databases/schemas/tables/views/warehouses, as the Snowflake SQLAlchemy engine does not test for
|
||||
user/role rights during engine creation by default. However, when pressing the “Test Connection”
|
||||
button in the Create or Edit Database dialog, user/role credentials are validated by passing
|
||||
“validate_default_parameters”: True to the connect() method during engine creation. If the user/role
|
||||
is not authorized to access the database, an error is recorded in the Superset logs.
|
||||
|
|
@ -0,0 +1,17 @@
|
|||
---
|
||||
title: Apache Solr
|
||||
hide_title: true
|
||||
sidebar_position: 13
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Apache Solr
|
||||
|
||||
The [sqlalchemy-solr](https://pypi.org/project/sqlalchemy-solr/) library provides a
|
||||
Python / SQLAlchemy interface to Apache Solr.
|
||||
|
||||
The connection string for Solr looks like this:
|
||||
|
||||
```
|
||||
solr://{username}:{password}@{host}:{port}/{server_path}/{collection}[/?use_ssl=true|false]
|
||||
```
|
||||
|
|
@ -0,0 +1,16 @@
|
|||
---
|
||||
title: Apache Spark SQL
|
||||
hide_title: true
|
||||
sidebar_position: 14
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Apache Spark SQL
|
||||
|
||||
The recommended connector library for Apache Spark SQL [pyhive](https://pypi.org/project/PyHive/).
|
||||
|
||||
The expected connection string is formatted as follows:
|
||||
|
||||
```
|
||||
hive://hive@{hostname}:{port}/{database}
|
||||
```
|
||||
|
|
@ -0,0 +1,16 @@
|
|||
---
|
||||
title: Microsoft SQL Server
|
||||
hide_title: true
|
||||
sidebar_position: 30
|
||||
version: 1
|
||||
---
|
||||
|
||||
## SQL Server
|
||||
|
||||
The recommended connector library for SQL Server is [pymssql](https://github.com/pymssql/pymssql).
|
||||
|
||||
The connection string for SQL Server looks like this:
|
||||
|
||||
```
|
||||
mssql+pymssql://<Username>:<Password>@<Host>:<Port-default:1433>/<Database Name>/?Encrypt=yes
|
||||
```
|
||||
|
|
@ -0,0 +1,28 @@
|
|||
---
|
||||
title: Teradata
|
||||
hide_title: true
|
||||
sidebar_position: 31
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Teradata
|
||||
|
||||
The recommended connector library is
|
||||
[sqlalchemy-teradata](https://github.com/Teradata/sqlalchemy-teradata).
|
||||
|
||||
The connection string for Teradata looks like this:
|
||||
|
||||
```
|
||||
teradata://{user}:{password}@{host}
|
||||
```
|
||||
|
||||
Note: Its required to have Teradata ODBC drivers installed and environment variables configured for
|
||||
proper work of sqlalchemy dialect. Teradata ODBC Drivers available here:
|
||||
https://downloads.teradata.com/download/connectivity/odbc-driver/linux
|
||||
|
||||
Required environment variables:
|
||||
|
||||
```
|
||||
export ODBCINI=/.../teradata/client/ODBC_64/odbc.ini
|
||||
export ODBCINST=/.../teradata/client/ODBC_64/odbcinst.ini
|
||||
```
|
||||
|
|
@ -0,0 +1,27 @@
|
|||
---
|
||||
title: Trino
|
||||
hide_title: true
|
||||
sidebar_position: 34
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Trino
|
||||
|
||||
Supported trino version 352 and higher
|
||||
|
||||
The [sqlalchemy-trino](https://pypi.org/project/sqlalchemy-trino/) library is the recommended way to connect to Trino through SQLAlchemy.
|
||||
|
||||
The expected connection string is formatted as follows:
|
||||
|
||||
```
|
||||
trino://{username}:{password}@{hostname}:{port}/{catalog}
|
||||
```
|
||||
|
||||
If you are running trino with docker on local machine please use the following connection URL
|
||||
|
||||
```
|
||||
trino://trino@host.docker.internal:8080
|
||||
```
|
||||
|
||||
Reference:
|
||||
[Trino-Superset-Podcast](https://trino.io/episodes/12.html)
|
||||
|
|
@ -0,0 +1,31 @@
|
|||
---
|
||||
title: Vertica
|
||||
hide_title: true
|
||||
sidebar_position: 32
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Vertica
|
||||
|
||||
The recommended connector library is
|
||||
[sqlalchemy-vertica-python](https://pypi.org/project/sqlalchemy-vertica-python/). The
|
||||
[Vertica](http://www.vertica.com/) connection parameters are:
|
||||
|
||||
- **User Name:** UserName
|
||||
- **Password:** DBPassword
|
||||
- **Database Host:**
|
||||
- For Localhost : localhost or 127.0.0.1
|
||||
- For On Prem : IP address or Host name
|
||||
- For Cloud: IP Address or Host Name
|
||||
- **Database Name:** Database Name
|
||||
- **Port:** default 5433
|
||||
|
||||
The connection string is formatted as follows:
|
||||
|
||||
```
|
||||
vertica+vertica_python://{username}:{password}@{host}/{database}
|
||||
```
|
||||
|
||||
Other parameters:
|
||||
|
||||
- Load Balancer - Backup Host
|
||||
|
|
@ -0,0 +1,295 @@
|
|||
---
|
||||
title: Frequently Asked Questions
|
||||
hide_title: true
|
||||
sidebar_position: 7
|
||||
---
|
||||
|
||||
## Frequently Asked Questions
|
||||
|
||||
### Can I join / query multiple tables at one time?
|
||||
|
||||
Not in the Explore or Visualization UI. A Superset SQLAlchemy datasource can only be a single table
|
||||
or a view.
|
||||
|
||||
When working with tables, the solution would be to materialize a table that contains all the fields
|
||||
needed for your analysis, most likely through some scheduled batch process.
|
||||
|
||||
A view is a simple logical layer that abstract an arbitrary SQL queries as a virtual table. This can
|
||||
allow you to join and union multiple tables, and to apply some transformation using arbitrary SQL
|
||||
expressions. The limitation there is your database performance as Superset effectively will run a
|
||||
query on top of your query (view). A good practice may be to limit yourself to joining your main
|
||||
large table to one or many small tables only, and avoid using _GROUP BY_ where possible as Superset
|
||||
will do its own _GROUP BY_ and doing the work twice might slow down performance.
|
||||
|
||||
Whether you use a table or a view, the important factor is whether your database is fast enough to
|
||||
serve it in an interactive fashion to provide a good user experience in Superset.
|
||||
|
||||
However, if you are using the SQL Lab, there is no such limitation, you can write sql query to join
|
||||
multiple tables as long as your db account has access to the tables.
|
||||
|
||||
### How BIG can my datasource be?
|
||||
|
||||
It can be gigantic! Superset acts as a thin layer above your underlying databases or data engines.
|
||||
|
||||
As mentioned above, the main criteria is whether your database can execute queries and return
|
||||
results in a time frame that is acceptable to your users. Many distributed databases out there can
|
||||
execute queries that scan through terabytes in an interactive fashion.
|
||||
|
||||
### How do I create my own visualization?
|
||||
|
||||
We recommend reading the instructions in
|
||||
[Building Custom Viz Plugins](/docs/installation/building-custom-viz-plugins).
|
||||
|
||||
### Can I upload and visualize CSV data?
|
||||
|
||||
Absolutely! Read the instructions [here](/docs/creating-charts-dashboards/exploring-data) to learn
|
||||
how to enable and use CSV upload.
|
||||
|
||||
### Why are my queries timing out?
|
||||
|
||||
There are many reasons may cause long query timing out.
|
||||
|
||||
For running long query from Sql Lab, by default Superset allows it run as long as 6 hours before it
|
||||
being killed by celery. If you want to increase the time for running query, you can specify the
|
||||
timeout in configuration. For example:
|
||||
|
||||
```
|
||||
SQLLAB_ASYNC_TIME_LIMIT_SEC = 60 * 60 * 6
|
||||
```
|
||||
|
||||
Superset is running on gunicorn web server, which may time out web requests. If you want to increase
|
||||
the default (50), you can specify the timeout when starting the web server with the -t flag, which
|
||||
is expressed in seconds.
|
||||
|
||||
```
|
||||
superset runserver -t 300
|
||||
```
|
||||
|
||||
If you are seeing timeouts (504 Gateway Time-out) when loading dashboard or explore slice, you are
|
||||
probably behind gateway or proxy server (such as Nginx). If it did not receive a timely response
|
||||
from Superset server (which is processing long queries), these web servers will send 504 status code
|
||||
to clients directly. Superset has a client-side timeout limit to address this issue. If query didn’t
|
||||
come back within client-side timeout (60 seconds by default), Superset will display warning message
|
||||
to avoid gateway timeout message. If you have a longer gateway timeout limit, you can change the
|
||||
timeout settings in **superset_config.py**:
|
||||
|
||||
```
|
||||
SUPERSET_WEBSERVER_TIMEOUT = 60
|
||||
```
|
||||
|
||||
### Why is the map not visible in the geospatial visualization?
|
||||
|
||||
You need to register a free account at [Mapbox.com](https://www.mapbox.com), obtain an API key, and add it
|
||||
to **superset_config.py** at the key MAPBOX_API_KEY:
|
||||
|
||||
```
|
||||
MAPBOX_API_KEY = "longstringofalphanumer1c"
|
||||
```
|
||||
|
||||
### How to add dynamic filters to a dashboard?
|
||||
|
||||
Use the **Filter Box** widget, build a slice, and add it to your dashboard.
|
||||
|
||||
The **Filter Box** widget allows you to define a query to populate dropdowns that can be used for
|
||||
filtering. To build the list of distinct values, we run a query, and sort the result by the metric
|
||||
you provide, sorting descending.
|
||||
|
||||
The widget also has a checkbox **Date Filter**, which enables time filtering capabilities to your
|
||||
dashboard. After checking the box and refreshing, you’ll see a from and a to dropdown show up.
|
||||
|
||||
By default, the filtering will be applied to all the slices that are built on top of a datasource
|
||||
that shares the column name that the filter is based on. It’s also a requirement for that column to
|
||||
be checked as “filterable” in the column tab of the table editor.
|
||||
|
||||
But what about if you don’t want certain widgets to get filtered on your dashboard? You can do that
|
||||
by editing your dashboard, and in the form, edit the JSON Metadata field, more specifically the
|
||||
`filter_immune_slices` key, that receives an array of sliceIds that should never be affected by any
|
||||
dashboard level filtering.
|
||||
|
||||
```
|
||||
{
|
||||
"filter_immune_slices": [324, 65, 92],
|
||||
"expanded_slices": {},
|
||||
"filter_immune_slice_fields": {
|
||||
"177": ["country_name", "__time_range"],
|
||||
"32": ["__time_range"]
|
||||
},
|
||||
"timed_refresh_immune_slices": [324]
|
||||
}
|
||||
```
|
||||
|
||||
In the json blob above, slices 324, 65 and 92 won’t be affected by any dashboard level filtering.
|
||||
|
||||
Now note the `filter_immune_slice_fields` key. This one allows you to be more specific and define
|
||||
for a specific slice_id, which filter fields should be disregarded.
|
||||
|
||||
Note the use of the `__time_range` keyword, which is reserved for dealing with the time boundary
|
||||
filtering mentioned above.
|
||||
|
||||
But what happens with filtering when dealing with slices coming from different tables or databases?
|
||||
If the column name is shared, the filter will be applied, it’s as simple as that.
|
||||
|
||||
### How to limit the timed refresh on a dashboard?
|
||||
|
||||
By default, the dashboard timed refresh feature allows you to automatically re-query every slice on
|
||||
a dashboard according to a set schedule. Sometimes, however, you won’t want all of the slices to be
|
||||
refreshed - especially if some data is slow moving, or run heavy queries. To exclude specific slices
|
||||
from the timed refresh process, add the `timed_refresh_immune_slices` key to the dashboard JSON
|
||||
Metadata field:
|
||||
|
||||
```
|
||||
{
|
||||
"filter_immune_slices": [],
|
||||
"expanded_slices": {},
|
||||
"filter_immune_slice_fields": {},
|
||||
"timed_refresh_immune_slices": [324]
|
||||
}
|
||||
```
|
||||
|
||||
In the example above, if a timed refresh is set for the dashboard, then every slice except 324 will
|
||||
be automatically re-queried on schedule.
|
||||
|
||||
Slice refresh will also be staggered over the specified period. You can turn off this staggering by
|
||||
setting the `stagger_refresh` to false and modify the stagger period by setting `stagger_time` to a
|
||||
value in milliseconds in the JSON Metadata field:
|
||||
|
||||
```
|
||||
{
|
||||
"stagger_refresh": false,
|
||||
"stagger_time": 2500
|
||||
}
|
||||
```
|
||||
|
||||
Here, the entire dashboard will refresh at once if periodic refresh is on. The stagger time of 2.5
|
||||
seconds is ignored.
|
||||
|
||||
**Why does ‘flask fab’ or superset freezed/hung/not responding when started (my home directory is
|
||||
NFS mounted)?**
|
||||
|
||||
By default, Superset creates and uses an SQLite database at `~/.superset/superset.db`. SQLite is
|
||||
known to [not work well if used on NFS](https://www.sqlite.org/lockingv3.html) due to broken file
|
||||
locking implementation on NFS.
|
||||
|
||||
You can override this path using the **SUPERSET_HOME** environment variable.
|
||||
|
||||
Another workaround is to change where superset stores the sqlite database by adding the following in
|
||||
`superset_config.py`:
|
||||
|
||||
```
|
||||
SQLALCHEMY_DATABASE_URI = 'sqlite:////new/location/superset.db'
|
||||
```
|
||||
|
||||
You can read more about customizing Superset using the configuration file
|
||||
[here](/docs/installation/configuring-superset).
|
||||
|
||||
### What if the table schema changed?
|
||||
|
||||
Table schemas evolve, and Superset needs to reflect that. It’s pretty common in the life cycle of a
|
||||
dashboard to want to add a new dimension or metric. To get Superset to discover your new columns,
|
||||
all you have to do is to go to **Data -> Datasets**, click the edit icon next to the dataset
|
||||
whose schema has changed, and hit **Sync columns from source** from the **Columns** tab.
|
||||
Behind the scene, the new columns will get merged it. Following this, you may want to re-edit the
|
||||
table afterwards to configure the Columns tab, check the appropriate boxes and save again.
|
||||
|
||||
### What database engine can I use as a backend for Superset?
|
||||
|
||||
To clarify, the database backend is an OLTP database used by Superset to store its internal
|
||||
information like your list of users, slices and dashboard definitions.
|
||||
|
||||
Superset is tested using Mysql, Postgresql and Sqlite for its backend. It’s recommended you install
|
||||
Superset on one of these database server for production.
|
||||
|
||||
Using a column-store, non-OLTP databases like Vertica, Redshift or Presto as a database backend
|
||||
simply won’t work as these databases are not designed for this type of workload. Installation on
|
||||
Oracle, Microsoft SQL Server, or other OLTP databases may work but isn’t tested.
|
||||
|
||||
Please note that pretty much any databases that have a SqlAlchemy integration should work perfectly
|
||||
fine as a datasource for Superset, just not as the OLTP backend.
|
||||
|
||||
### How can I configure OAuth authentication and authorization?
|
||||
|
||||
You can take a look at this Flask-AppBuilder
|
||||
[configuration example](https://github.com/dpgaspar/Flask-AppBuilder/blob/master/examples/oauth/config.py).
|
||||
|
||||
### How can I set a default filter on my dashboard?
|
||||
|
||||
Simply apply the filter and save the dashboard while the filter is active.
|
||||
|
||||
### Is there a way to force the use specific colors?
|
||||
|
||||
It is possible on a per-dashboard basis by providing a mapping of labels to colors in the JSON
|
||||
Metadata attribute using the `label_colors` key.
|
||||
|
||||
```
|
||||
{
|
||||
"label_colors": {
|
||||
"Girls": "#FF69B4",
|
||||
"Boys": "#ADD8E6"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
### Does Superset work with [insert database engine here]?
|
||||
|
||||
The [Connecting to Databases section](/docs/databases/installing-database-drivers) provides the best
|
||||
overview for supported databases. Database engines not listed on that page may work too. We rely on
|
||||
the community to contribute to this knowledge base.
|
||||
|
||||
For a database engine to be supported in Superset through the SQLAlchemy connector, it requires
|
||||
having a Python compliant [SQLAlchemy dialect](https://docs.sqlalchemy.org/en/13/dialects/) as well
|
||||
as a [DBAPI driver](https://www.python.org/dev/peps/pep-0249/) defined. Database that have limited
|
||||
SQL support may work as well. For instance it’s possible to connect to Druid through the SQLAlchemy
|
||||
connector even though Druid does not support joins and subqueries. Another key element for a
|
||||
database to be supported is through the Superset Database Engine Specification interface. This
|
||||
interface allows for defining database-specific configurations and logic that go beyond the
|
||||
SQLAlchemy and DBAPI scope. This includes features like:
|
||||
|
||||
- date-related SQL function that allow Superset to fetch different time granularities when running
|
||||
time-series queries
|
||||
- whether the engine supports subqueries. If false, Superset may run 2-phase queries to compensate
|
||||
for the limitation
|
||||
- methods around processing logs and inferring the percentage of completion of a query
|
||||
- technicalities as to how to handle cursors and connections if the driver is not standard DBAPI
|
||||
|
||||
Beyond the SQLAlchemy connector, it’s also possible, though much more involved, to extend Superset
|
||||
and write your own connector. The only example of this at the moment is the Druid connector, which
|
||||
is getting superseded by Druid’s growing SQL support and the recent availability of a DBAPI and
|
||||
SQLAlchemy driver. If the database you are considering integrating has any kind of of SQL support,
|
||||
it’s probably preferable to go the SQLAlchemy route. Note that for a native connector to be possible
|
||||
the database needs to have support for running OLAP-type queries and should be able to things that
|
||||
are typical in basic SQL:
|
||||
|
||||
- aggregate data
|
||||
- apply filters
|
||||
- apply HAVING-type filters
|
||||
- be schema-aware, expose columns and types
|
||||
|
||||
### Does Superset offer a public API?
|
||||
|
||||
Yes, a public REST API, and the surface of that API formal is expanding steadily. You can read more about this API and
|
||||
interact with it using Swagger [here](/docs/rest-api).
|
||||
|
||||
Some of the
|
||||
original vision for the collection of endpoints under **/api/v1** was originally specified in
|
||||
[SIP-17](https://github.com/apache/superset/issues/7259) and constant progress has been
|
||||
made to cover more and more use cases.
|
||||
|
||||
The API available is documented using [Swagger](https://swagger.io/) and the documentation can be
|
||||
made available under **/swagger/v1** by enabling the following flag in `superset_config.py`:
|
||||
|
||||
```
|
||||
FAB_API_SWAGGER_UI = True
|
||||
```
|
||||
|
||||
There are other undocumented [private] ways to interact with Superset programmatically that offer no
|
||||
guarantees and are not recommended but may fit your use case temporarily:
|
||||
|
||||
- using the ORM (SQLAlchemy) directly
|
||||
- using the internal FAB ModelView API (to be deprecated in Superset)
|
||||
- altering the source code in your fork
|
||||
|
||||
### What Does Hours Offset in the Edit Dataset view do?
|
||||
|
||||
In the Edit Dataset view, you can specify a time offset. This field lets you configure the
|
||||
number of hours to be added or subtracted from the time column.
|
||||
This can be used, for example, to convert UTC time to local time.
|
||||
|
|
@ -0,0 +1,4 @@
|
|||
{
|
||||
"label": "Installation and Configuration",
|
||||
"position": 2
|
||||
}
|
||||
|
|
@ -0,0 +1,483 @@
|
|||
---
|
||||
title: Alerts and Reports
|
||||
hide_title: true
|
||||
sidebar_position: 9
|
||||
version: 2
|
||||
---
|
||||
|
||||
## Alerts and Reports
|
||||
|
||||
(version 1.0.1 and above)
|
||||
|
||||
Users can configure automated alerts and reports to send dashboards or charts to an email recipient or Slack channel.
|
||||
|
||||
- Alerts are sent when a SQL condition is reached
|
||||
- Reports are sent on a schedule
|
||||
|
||||
Alerts and reports are disabled by default. To turn them on, you need to do some setup, described here.
|
||||
|
||||
### Requirements
|
||||
|
||||
#### Commons
|
||||
|
||||
##### In your `superset_config.py`
|
||||
|
||||
- `"ALERT_REPORTS"` feature flag must be turned to True.
|
||||
- `CELERYBEAT_SCHEDULE` in CeleryConfig must contain schedule for `reports.scheduler`.
|
||||
- At least one of those must be configured, depending on what you want to use:
|
||||
- emails: `SMTP_*` settings
|
||||
- Slack messages: `SLACK_API_TOKEN`
|
||||
|
||||
##### In your `Dockerfile`
|
||||
|
||||
- You must install a headless browser, for taking screenshots of the charts and dashboards. Only Firefox and Chrome are currently supported.
|
||||
> If you choose Chrome, you must also change the value of `WEBDRIVER_TYPE` to `"chrome"` in your `superset_config.py`.
|
||||
|
||||
#### Slack integration
|
||||
|
||||
To send alerts and reports to Slack channels, you need to create a new Slack Application on your workspace.
|
||||
|
||||
1. Connect to your Slack workspace, then head to <https://api.slack.com/apps>.
|
||||
2. Create a new app.
|
||||
3. Go to "OAuth & Permissions" section, and give the following scopes to your app:
|
||||
- `incoming-webhook`
|
||||
- `files:write`
|
||||
- `chat:write`
|
||||
4. At the top of the "OAuth and Permissions" section, click "install to workspace".
|
||||
5. Select a default channel for your app and continue.
|
||||
(You can post to any channel by inviting your Superset app into that channel).
|
||||
6. The app should now be installed in your workspace, and a "Bot User OAuth Access Token" should have been created. Copy that token in the `SLACK_API_TOKEN` variable of your `superset_config.py`.
|
||||
7. Restart the service (or run `superset init`) to pull in the new configuration.
|
||||
|
||||
Note: when you configure an alert or a report, the Slack channel list take channel names without the leading '#' e.g. use `alerts` instead of `#alerts`.
|
||||
|
||||
#### Kubernetes specific
|
||||
|
||||
- You must have a `celery beat` pod running. If you're using the chart included in the GitHub repository under [helm/superset](https://github.com/apache/superset/tree/master/helm/superset), you need to put `supersetCeleryBeat.enabled = true` in your values override.
|
||||
- You can see the dedicated docs about [Kubernetes installation](/docs/installation/running-on-kubernetes) for more generic details.
|
||||
|
||||
#### Docker-compose specific
|
||||
|
||||
##### You must have in your`docker-compose.yaml`
|
||||
|
||||
- a redis message broker
|
||||
- PostgreSQL DB instead of SQLlite
|
||||
- one or more `celery worker`
|
||||
- a single `celery beat`
|
||||
|
||||
### Detailed config
|
||||
|
||||
The following configurations need to be added to the `superset_config.py` file. This file is loaded when the image runs, and any configurations in it will override the default configurations found in the `config.py`.
|
||||
|
||||
You can find documentation about each field in the default `config.py` in the GitHub repository under [superset/config.py](https://github.com/apache/superset/blob/master/superset/config.py).
|
||||
|
||||
You need to replace default values with your custom Redis, Slack and/or SMTP config.
|
||||
|
||||
In the `CeleryConfig`, only the `CELERYBEAT_SCHEDULE` is relative to this feature, the rest of the `CeleryConfig` can be changed for your needs.
|
||||
|
||||
```python
|
||||
from celery.schedules import crontab
|
||||
|
||||
FEATURE_FLAGS = {
|
||||
"ALERT_REPORTS": True
|
||||
}
|
||||
|
||||
REDIS_HOST = "redis-superset"
|
||||
REDIS_PORT = "6379"
|
||||
|
||||
class CeleryConfig:
|
||||
BROKER_URL = 'redis://%s:%s/0' % (REDIS_HOST, REDIS_PORT)
|
||||
CELERY_IMPORTS = ('superset.sql_lab', "superset.tasks", "superset.tasks.thumbnails", )
|
||||
CELERY_RESULT_BACKEND = 'redis://%s:%s/0' % (REDIS_HOST, REDIS_PORT)
|
||||
CELERYD_PREFETCH_MULTIPLIER = 10
|
||||
CELERY_ACKS_LATE = True
|
||||
CELERY_ANNOTATIONS = {
|
||||
'sql_lab.get_sql_results': {
|
||||
'rate_limit': '100/s',
|
||||
},
|
||||
'email_reports.send': {
|
||||
'rate_limit': '1/s',
|
||||
'time_limit': 600,
|
||||
'soft_time_limit': 600,
|
||||
'ignore_result': True,
|
||||
},
|
||||
}
|
||||
CELERYBEAT_SCHEDULE = {
|
||||
'reports.scheduler': {
|
||||
'task': 'reports.scheduler',
|
||||
'schedule': crontab(minute='*', hour='*'),
|
||||
},
|
||||
'reports.prune_log': {
|
||||
'task': 'reports.prune_log',
|
||||
'schedule': crontab(minute=0, hour=0),
|
||||
},
|
||||
}
|
||||
CELERY_CONFIG = CeleryConfig
|
||||
|
||||
SCREENSHOT_LOCATE_WAIT = 100
|
||||
SCREENSHOT_LOAD_WAIT = 600
|
||||
|
||||
# Slack configuration
|
||||
SLACK_API_TOKEN = "xoxb-"
|
||||
|
||||
# Email configuration
|
||||
SMTP_HOST = "smtp.sendgrid.net" #change to your host
|
||||
SMTP_STARTTLS = True
|
||||
SMTP_SSL = False
|
||||
SMTP_USER = "your_user"
|
||||
SMTP_PORT = 2525 # your port eg. 587
|
||||
SMTP_PASSWORD = "your_password"
|
||||
SMTP_MAIL_FROM = "noreply@youremail.com"
|
||||
|
||||
# WebDriver configuration
|
||||
# If you use Firefox, you can stick with default values
|
||||
# If you use Chrome, then add the following WEBDRIVER_TYPE and WEBDRIVER_OPTION_ARGS
|
||||
WEBDRIVER_TYPE = "chrome"
|
||||
WEBDRIVER_OPTION_ARGS = [
|
||||
"--force-device-scale-factor=2.0",
|
||||
"--high-dpi-support=2.0",
|
||||
"--headless",
|
||||
"--disable-gpu",
|
||||
"--disable-dev-shm-usage",
|
||||
"--no-sandbox",
|
||||
"--disable-setuid-sandbox",
|
||||
"--disable-extensions",
|
||||
]
|
||||
|
||||
# This is for internal use, you can keep http
|
||||
WEBDRIVER_BASEURL="http://superset:8088"
|
||||
# This is the link sent to the recipient, change to your domain eg. https://superset.mydomain.com
|
||||
WEBDRIVER_BASEURL_USER_FRIENDLY="http://localhost:8088"
|
||||
```
|
||||
|
||||
### Custom Dockerfile
|
||||
|
||||
A webdriver (and headless browser) is needed to capture screenshots of the charts and dashboards which are then sent to the recipient. As the base superset image does not have a webdriver installed, we need to extend it and install the webdriver.
|
||||
|
||||
#### Using Firefox
|
||||
|
||||
```docker
|
||||
FROM apache/superset:1.0.1
|
||||
|
||||
USER root
|
||||
|
||||
RUN apt-get update && \
|
||||
apt-get install --no-install-recommends -y firefox-esr
|
||||
|
||||
ENV GECKODRIVER_VERSION=0.29.0
|
||||
RUN wget -q https://github.com/mozilla/geckodriver/releases/download/v${GECKODRIVER_VERSION}/geckodriver-v${GECKODRIVER_VERSION}-linux64.tar.gz && \
|
||||
tar -x geckodriver -zf geckodriver-v${GECKODRIVER_VERSION}-linux64.tar.gz -O > /usr/bin/geckodriver && \
|
||||
chmod 755 /usr/bin/geckodriver && \
|
||||
rm geckodriver-v${GECKODRIVER_VERSION}-linux64.tar.gz
|
||||
|
||||
RUN pip install --no-cache gevent psycopg2 redis
|
||||
|
||||
USER superset
|
||||
```
|
||||
|
||||
#### Using Chrome
|
||||
|
||||
```docker
|
||||
FROM apache/superset:1.0.1
|
||||
|
||||
USER root
|
||||
|
||||
RUN apt-get update && \
|
||||
wget -q https://dl.google.com/linux/direct/google-chrome-stable_current_amd64.deb && \
|
||||
apt-get install -y --no-install-recommends ./google-chrome-stable_current_amd64.deb && \
|
||||
rm -f google-chrome-stable_current_amd64.deb
|
||||
|
||||
RUN export CHROMEDRIVER_VERSION=$(curl --silent https://chromedriver.storage.googleapis.com/LATEST_RELEASE_88) && \
|
||||
wget -q https://chromedriver.storage.googleapis.com/${CHROMEDRIVER_VERSION}/chromedriver_linux64.zip && \
|
||||
unzip chromedriver_linux64.zip -d /usr/bin && \
|
||||
chmod 755 /usr/bin/chromedriver && \
|
||||
rm -f chromedriver_linux64.zip
|
||||
|
||||
RUN pip install --no-cache gevent psycopg2 redis
|
||||
|
||||
USER superset
|
||||
```
|
||||
|
||||
> Don't forget to set `WEBDRIVER_TYPE` and `WEBDRIVER_OPTION_ARGS` in your config if you use Chrome.
|
||||
|
||||
### Summary of steps to turn on alerts and reporting:
|
||||
|
||||
Using the templates below,
|
||||
|
||||
1. Create a new directory and create the Dockerfile
|
||||
2. Build the extended image using the Dockerfile
|
||||
3. Create the `docker-compose.yaml` file in the same directory
|
||||
4. Create a new subdirectory called `config`
|
||||
5. Create the `superset_config.py` file in the `config` subdirectory
|
||||
6. Run the image using `docker-compose up` in the same directory as the `docker-compose.py` file
|
||||
7. In a new terminal window, upgrade the DB by running `docker exec -it superset-1.0.1-extended superset db upgrade`
|
||||
8. Then run `docker exec -it superset-1.0.1-extended superset init`
|
||||
9. Then setup your admin user if need be, `docker exec -it superset-1.0.1-extended superset fab create-admin`
|
||||
10. Finally, restart the running instance - `CTRL-C`, then `docker-compose up`
|
||||
|
||||
(note: v 1.0.1 is current at time of writing, you can change the version number to the latest version if a newer version is available)
|
||||
|
||||
### Docker compose
|
||||
|
||||
The docker compose file lists the services that will be used when running the image. The specific services needed for alerts and reporting are outlined below.
|
||||
|
||||
#### Redis message broker
|
||||
|
||||
To ferry requests between the celery worker and the Superset instance, we use a message broker. This template uses Redis.
|
||||
|
||||
#### Replacing SQLite with Postgres
|
||||
|
||||
While it might be possible to use SQLite for alerts and reporting, it is highly recommended using a more production ready DB for Superset in general. Our template uses Postgres.
|
||||
|
||||
#### Celery worker
|
||||
|
||||
The worker will process the tasks that need to be performed when an alert or report is fired.
|
||||
|
||||
#### Celery beat
|
||||
|
||||
The beat is the scheduler that tells the worker when to perform its tasks. This schedule is defined when you create the alert or report.
|
||||
|
||||
#### Full `docker-compose.yaml` configuration
|
||||
|
||||
The Redis, Postgres, Celery worker and Celery beat services are defined in the template:
|
||||
|
||||
Config for `docker-compose.yaml`:
|
||||
|
||||
```docker
|
||||
version: '3.6'
|
||||
services:
|
||||
redis:
|
||||
image: redis:6.0.9-buster
|
||||
restart: on-failure
|
||||
volumes:
|
||||
- redis:/data
|
||||
postgres:
|
||||
image: postgres
|
||||
restart: on-failure
|
||||
environment:
|
||||
POSTGRES_DB: superset
|
||||
POSTGRES_PASSWORD: superset
|
||||
POSTGRES_USER: superset
|
||||
volumes:
|
||||
- db:/var/lib/postgresql/data
|
||||
worker:
|
||||
image: superset-1.0.1-extended
|
||||
restart: on-failure
|
||||
healthcheck:
|
||||
disable: true
|
||||
depends_on:
|
||||
- superset
|
||||
- postgres
|
||||
- redis
|
||||
command: "celery --app=superset.tasks.celery_app:app worker --pool=gevent --concurrency=500"
|
||||
volumes:
|
||||
- ./config/:/app/pythonpath/
|
||||
beat:
|
||||
image: superset-1.0.1-extended
|
||||
restart: on-failure
|
||||
healthcheck:
|
||||
disable: true
|
||||
depends_on:
|
||||
- superset
|
||||
- postgres
|
||||
- redis
|
||||
command: "celery --app=superset.tasks.celery_app:app beat --pidfile /tmp/celerybeat.pid --schedule /tmp/celerybeat-schedule"
|
||||
volumes:
|
||||
- ./config/:/app/pythonpath/
|
||||
superset:
|
||||
image: superset-1.0.1-extended
|
||||
restart: on-failure
|
||||
environment:
|
||||
- SUPERSET_PORT=8088
|
||||
ports:
|
||||
- "8088:8088"
|
||||
depends_on:
|
||||
- postgres
|
||||
- redis
|
||||
command: gunicorn --bind 0.0.0.0:8088 --access-logfile - --error-logfile - --workers 5 --worker-class gthread --threads 4 --timeout 200 --limit-request-line 4094 --limit-request-field_size 8190 superset.app:create_app()
|
||||
volumes:
|
||||
- ./config/:/app/pythonpath/
|
||||
volumes:
|
||||
db:
|
||||
external: true
|
||||
redis:
|
||||
external: false
|
||||
```
|
||||
|
||||
### Summary
|
||||
|
||||
With the extended image created by using the `Dockerfile`, and then running that image using `docker-compose.yaml`, plus the required configurations in the `superset_config.py` you should now have alerts and reporting working correctly.
|
||||
|
||||
- The above templates also work in a Docker swarm environment, you would just need to add `Deploy:` to the Superset, Redis and Postgres services along with your specific configs for your swarm
|
||||
|
||||
# Old Reports feature
|
||||
|
||||
## Scheduling and Emailing Reports
|
||||
|
||||
(version 0.38 and below)
|
||||
|
||||
### Email Reports
|
||||
|
||||
Email reports allow users to schedule email reports for:
|
||||
|
||||
- chart and dashboard visualization (attachment or inline)
|
||||
- chart data (CSV attachment on inline table)
|
||||
|
||||
Enable email reports in your `superset_config.py` file:
|
||||
|
||||
```python
|
||||
ENABLE_SCHEDULED_EMAIL_REPORTS = True
|
||||
```
|
||||
|
||||
This flag enables some permissions that are stored in your database, so you'll want to run `superset init` again if you are running this in a dev environment.
|
||||
Now you will find two new items in the navigation bar that allow you to schedule email reports:
|
||||
|
||||
- **Manage > Dashboard Emails**
|
||||
- **Manage > Chart Email Schedules**
|
||||
|
||||
Schedules are defined in [crontab format](https://crontab.guru/) and each schedule can have a list
|
||||
of recipients (all of them can receive a single mail, or separate mails). For audit purposes, all
|
||||
outgoing mails can have a mandatory BCC.
|
||||
|
||||
In order get picked up you need to configure a celery worker and a celery beat (see section above
|
||||
“Celery Tasks”). Your celery configuration also needs an entry `email_reports.schedule_hourly` for
|
||||
`CELERYBEAT_SCHEDULE`.
|
||||
|
||||
To send emails you need to configure SMTP settings in your `superset_config.py` configuration file.
|
||||
|
||||
```python
|
||||
EMAIL_NOTIFICATIONS = True
|
||||
|
||||
SMTP_HOST = "email-smtp.eu-west-1.amazonaws.com"
|
||||
SMTP_STARTTLS = True
|
||||
SMTP_SSL = False
|
||||
SMTP_USER = "smtp_username"
|
||||
SMTP_PORT = 25
|
||||
SMTP_PASSWORD = os.environ.get("SMTP_PASSWORD")
|
||||
SMTP_MAIL_FROM = "insights@komoot.com"
|
||||
```
|
||||
|
||||
To render dashboards you need to install a local browser on your Superset instance:
|
||||
|
||||
- [geckodriver](https://github.com/mozilla/geckodriver) for Firefox
|
||||
- [chromedriver](http://chromedriver.chromium.org/) for Chrome
|
||||
|
||||
You'll need to adjust the `WEBDRIVER_TYPE` accordingly in your configuration. You also need
|
||||
to specify on behalf of which username to render the dashboards. In general dashboards and charts
|
||||
are not accessible to unauthorized requests, that is why the worker needs to take over credentials
|
||||
of an existing user to take a snapshot.
|
||||
|
||||
```python
|
||||
THUMBNAIL_SELENIUM_USER = 'username_with_permission_to_access_dashboards'
|
||||
```
|
||||
|
||||
**Important notes**
|
||||
|
||||
- Be mindful of the concurrency setting for celery (using `-c 4`). Selenium/webdriver instances can
|
||||
consume a lot of CPU / memory on your servers.
|
||||
- In some cases, if you notice a lot of leaked geckodriver processes, try running your celery
|
||||
processes with `celery worker --pool=prefork --max-tasks-per-child=128 ...`
|
||||
- It is recommended to run separate workers for the `sql_lab` and `email_reports` tasks. This can be
|
||||
done using the `queue` field in `CELERY_ANNOTATIONS`.
|
||||
- Adjust `WEBDRIVER_BASEURL` in your configuration file if celery workers can’t access Superset via
|
||||
its default value of `http://0.0.0.0:8080/`.
|
||||
|
||||
### Schedule Reports
|
||||
|
||||
You can optionally allow your users to schedule queries directly in SQL Lab. This is done by addding
|
||||
extra metadata to saved queries, which are then picked up by an external scheduled (like
|
||||
[Apache Airflow](https://airflow.apache.org/)).
|
||||
|
||||
To allow scheduled queries, add the following to your configuration file:
|
||||
|
||||
```python
|
||||
FEATURE_FLAGS = {
|
||||
# Configuration for scheduling queries from SQL Lab. This information is
|
||||
# collected when the user clicks "Schedule query", and saved into the `extra`
|
||||
# field of saved queries.
|
||||
# See: https://github.com/mozilla-services/react-jsonschema-form
|
||||
'SCHEDULED_QUERIES': {
|
||||
'JSONSCHEMA': {
|
||||
'title': 'Schedule',
|
||||
'description': (
|
||||
'In order to schedule a query, you need to specify when it '
|
||||
'should start running, when it should stop running, and how '
|
||||
'often it should run. You can also optionally specify '
|
||||
'dependencies that should be met before the query is '
|
||||
'executed. Please read the documentation for best practices '
|
||||
'and more information on how to specify dependencies.'
|
||||
),
|
||||
'type': 'object',
|
||||
'properties': {
|
||||
'output_table': {
|
||||
'type': 'string',
|
||||
'title': 'Output table name',
|
||||
},
|
||||
'start_date': {
|
||||
'type': 'string',
|
||||
'title': 'Start date',
|
||||
# date-time is parsed using the chrono library, see
|
||||
# https://www.npmjs.com/package/chrono-node#usage
|
||||
'format': 'date-time',
|
||||
'default': 'tomorrow at 9am',
|
||||
},
|
||||
'end_date': {
|
||||
'type': 'string',
|
||||
'title': 'End date',
|
||||
# date-time is parsed using the chrono library, see
|
||||
# https://www.npmjs.com/package/chrono-node#usage
|
||||
'format': 'date-time',
|
||||
'default': '9am in 30 days',
|
||||
},
|
||||
'schedule_interval': {
|
||||
'type': 'string',
|
||||
'title': 'Schedule interval',
|
||||
},
|
||||
'dependencies': {
|
||||
'type': 'array',
|
||||
'title': 'Dependencies',
|
||||
'items': {
|
||||
'type': 'string',
|
||||
},
|
||||
},
|
||||
},
|
||||
},
|
||||
'UISCHEMA': {
|
||||
'schedule_interval': {
|
||||
'ui:placeholder': '@daily, @weekly, etc.',
|
||||
},
|
||||
'dependencies': {
|
||||
'ui:help': (
|
||||
'Check the documentation for the correct format when '
|
||||
'defining dependencies.'
|
||||
),
|
||||
},
|
||||
},
|
||||
'VALIDATION': [
|
||||
# ensure that start_date <= end_date
|
||||
{
|
||||
'name': 'less_equal',
|
||||
'arguments': ['start_date', 'end_date'],
|
||||
'message': 'End date cannot be before start date',
|
||||
# this is where the error message is shown
|
||||
'container': 'end_date',
|
||||
},
|
||||
],
|
||||
# link to the scheduler; this example links to an Airflow pipeline
|
||||
# that uses the query id and the output table as its name
|
||||
'linkback': (
|
||||
'https://airflow.example.com/admin/airflow/tree?'
|
||||
'dag_id=query_${id}_${extra_json.schedule_info.output_table}'
|
||||
),
|
||||
},
|
||||
}
|
||||
```
|
||||
|
||||
This feature flag is based on
|
||||
[react-jsonschema-form](https://github.com/mozilla-services/react-jsonschema-form) and will add a
|
||||
button called “Schedule Query” to SQL Lab. When the button is clicked, a modal will show up where
|
||||
the user can add the metadata required for scheduling the query.
|
||||
|
||||
This information can then be retrieved from the endpoint `/savedqueryviewapi/api/read` and used to
|
||||
schedule the queries that have `scheduled_queries` in their JSON metadata. For schedulers other than
|
||||
Airflow, additional fields can be easily added to the configuration file above.
|
||||
|
|
@ -0,0 +1,117 @@
|
|||
---
|
||||
title: Async Queries via Celery
|
||||
hide_title: true
|
||||
sidebar_position: 8
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Async Queries via Celery
|
||||
|
||||
### Celery
|
||||
|
||||
On large analytic databases, it’s common to run queries that execute for minutes or hours. To enable
|
||||
support for long running queries that execute beyond the typical web request’s timeout (30-60
|
||||
seconds), it is necessary to configure an asynchronous backend for Superset which consists of:
|
||||
|
||||
- one or many Superset workers (which is implemented as a Celery worker), and can be started with
|
||||
the `celery worker` command, run `celery worker --help` to view the related options.
|
||||
- a celery broker (message queue) for which we recommend using Redis or RabbitMQ
|
||||
- a results backend that defines where the worker will persist the query results
|
||||
|
||||
Configuring Celery requires defining a `CELERY_CONFIG` in your `superset_config.py`. Both the worker
|
||||
and web server processes should have the same configuration.
|
||||
|
||||
```python
|
||||
class CeleryConfig(object):
|
||||
BROKER_URL = 'redis://localhost:6379/0'
|
||||
CELERY_IMPORTS = (
|
||||
'superset.sql_lab',
|
||||
'superset.tasks',
|
||||
)
|
||||
CELERY_RESULT_BACKEND = 'redis://localhost:6379/0'
|
||||
CELERYD_LOG_LEVEL = 'DEBUG'
|
||||
CELERYD_PREFETCH_MULTIPLIER = 10
|
||||
CELERY_ACKS_LATE = True
|
||||
CELERY_ANNOTATIONS = {
|
||||
'sql_lab.get_sql_results': {
|
||||
'rate_limit': '100/s',
|
||||
},
|
||||
'email_reports.send': {
|
||||
'rate_limit': '1/s',
|
||||
'time_limit': 120,
|
||||
'soft_time_limit': 150,
|
||||
'ignore_result': True,
|
||||
},
|
||||
}
|
||||
CELERYBEAT_SCHEDULE = {
|
||||
'email_reports.schedule_hourly': {
|
||||
'task': 'email_reports.schedule_hourly',
|
||||
'schedule': crontab(minute=1, hour='*'),
|
||||
},
|
||||
}
|
||||
|
||||
CELERY_CONFIG = CeleryConfig
|
||||
```
|
||||
|
||||
To start a Celery worker to leverage the configuration, run the following command:
|
||||
|
||||
```
|
||||
celery --app=superset.tasks.celery_app:app worker --pool=prefork -O fair -c 4
|
||||
```
|
||||
|
||||
To start a job which schedules periodic background jobs, run the following command:
|
||||
|
||||
```
|
||||
celery --app=superset.tasks.celery_app:app beat
|
||||
```
|
||||
|
||||
To setup a result backend, you need to pass an instance of a derivative of from
|
||||
cachelib.base.BaseCache to the RESULTS_BACKEND configuration key in your superset_config.py. You can
|
||||
use Memcached, Redis, S3 (https://pypi.python.org/pypi/s3werkzeugcache), memory or the file system
|
||||
(in a single server-type setup or for testing), or to write your own caching interface. Your
|
||||
`superset_config.py` may look something like:
|
||||
|
||||
```python
|
||||
# On S3
|
||||
from s3cache.s3cache import S3Cache
|
||||
S3_CACHE_BUCKET = 'foobar-superset'
|
||||
S3_CACHE_KEY_PREFIX = 'sql_lab_result'
|
||||
RESULTS_BACKEND = S3Cache(S3_CACHE_BUCKET, S3_CACHE_KEY_PREFIX)
|
||||
|
||||
# On Redis
|
||||
from cachelib.redis import RedisCache
|
||||
RESULTS_BACKEND = RedisCache(
|
||||
host='localhost', port=6379, key_prefix='superset_results')
|
||||
```
|
||||
|
||||
For performance gains, [MessagePack](https://github.com/msgpack/msgpack-python) and
|
||||
[PyArrow](https://arrow.apache.org/docs/python/) are now used for results serialization. This can be
|
||||
disabled by setting `RESULTS_BACKEND_USE_MSGPACK = False` in your `superset_config.py`, should any
|
||||
issues arise. Please clear your existing results cache store when upgrading an existing environment.
|
||||
|
||||
**Important Notes**
|
||||
|
||||
- It is important that all the worker nodes and web servers in the Superset cluster _share a common
|
||||
metadata database_. This means that SQLite will not work in this context since it has limited
|
||||
support for concurrency and typically lives on the local file system.
|
||||
|
||||
- There should _only be one instance of celery beat running_ in your entire setup. If not,
|
||||
background jobs can get scheduled multiple times resulting in weird behaviors like duplicate
|
||||
delivery of reports, higher than expected load / traffic etc.
|
||||
|
||||
- SQL Lab will _only run your queries asynchronously if_ you enable **Asynchronous Query Execution**
|
||||
in your database settings (Sources > Databases > Edit record).
|
||||
|
||||
### Celery Flower
|
||||
|
||||
Flower is a web based tool for monitoring the Celery cluster which you can install from pip:
|
||||
|
||||
```python
|
||||
pip install flower
|
||||
```
|
||||
|
||||
You can run flower using:
|
||||
|
||||
```
|
||||
celery --app=superset.tasks.celery_app:app flower
|
||||
```
|
||||
|
|
@ -0,0 +1,232 @@
|
|||
---
|
||||
title: Building Custom Viz Plugins
|
||||
hide_title: true
|
||||
sidebar_position: 11
|
||||
version: 1
|
||||
---
|
||||
|
||||
import useBaseUrl from "@docusaurus/useBaseUrl";
|
||||
|
||||
This is a tutorial to help you build a "Hello World" viz plugin. The intent is to provide a basic
|
||||
scaffolding to build any sort of data visualization, using any viz libary you'd like (e.g. ECharts,
|
||||
AntV, HighCharts, VX, and D3.).
|
||||
|
||||
You can build the Hello World plugin by running a [Yeoman](https://yeoman.io/) generator, which
|
||||
takes a few simple options, and provides this plugin scaffolding.
|
||||
|
||||
## Getting Set Up
|
||||
|
||||
### Install Yeoman and the Superset Package Generator
|
||||
|
||||
This Hello World plugin we'll be building is generated automatically with
|
||||
[Yeoman](https://yeoman.io/). Let's first get that installed by opening up a terminal and installing
|
||||
both the `yo` module and the
|
||||
[superset package generator](https://github.com/apache-superset/superset-ui/tree/master/packages/generator-superset)
|
||||
(`v0.14.7`) to create the new plugin.
|
||||
|
||||
```
|
||||
npm install -g yo @superset-ui/generator-superset
|
||||
```
|
||||
|
||||
### Install Superset
|
||||
|
||||
There are
|
||||
[complete instructions](https://github.com/apache/superset#installation-and-configuration)
|
||||
available on the [Superset Github repository](https://github.com/apache/superset). In a
|
||||
nutshell, the easiest way is to:
|
||||
|
||||
1. Have a Mac or linux-based machine
|
||||
2. Install [Docker](https://docs.docker.com/get-docker/)
|
||||
3. Clone [the repository](https://github.com/apache/superset) to your computer
|
||||
4. Use your terminal to `cd` into the `superset` directory
|
||||
5. Run `docker-compose up`
|
||||
6. Open _another_ terminal, and `cd` into `superset/superset-frontend`
|
||||
7. Run `npm install` to load up all the npm packages.
|
||||
8. Run `npm run dev-server` to spin up the Webpack hot-reloading server
|
||||
9. Wait for it to build, and then open your browser to `http://localhost:9000` and log in with
|
||||
`admin`/`admin`. You're off to the races! (Note: we'll be restarting this later)
|
||||
|
||||
### Install Superset-UI
|
||||
|
||||
1. Clone [the `superset-ui` repository](https://github.com/apache-superset/superset-ui) to your
|
||||
computer. It can sit in the same parent directory as your `superset` repo
|
||||
2. Use your terminal to `cd` into `superset-ui`
|
||||
3. Run `yarn install` and wait for all the packages to get installed
|
||||
|
||||
## Build Your "Hello, World"
|
||||
|
||||
### ~~Write~~ _generate_ some code!
|
||||
|
||||
1. Using your terminal, `cd` into your local `superset-ui` repo folder and then into the `plugins`
|
||||
subdirectory.
|
||||
2. Make a new directory for your plugin, i.e. `mkdir plugin-chart-hello-world`. **Note:** we
|
||||
_highly_ recommend following the `plugin-chart-your-plugin-name` pattern.
|
||||
3. Now `cd plugin-chart-hello-world`
|
||||
4. Finally, run `yo @superset-ui/superset`
|
||||
5. Select `Create superset-ui chart plugin package` on the following screen:
|
||||
|
||||
<img src={useBaseUrl("/img/custom-plugins/plugin-1-yeoman-select.png")} />{" "}
|
||||
|
||||
6. Give it a name (in our case, go with the default, based on the folder name):
|
||||
|
||||
<img
|
||||
src={useBaseUrl("/img/custom-plugins/plugin-2-yeoman-package-name.png")}
|
||||
/>
|
||||
|
||||
7. Give it a description (again, default is fine!)
|
||||
|
||||
<img
|
||||
src={useBaseUrl("/img/custom-plugins/plugin-3-yeoman-description.png")}
|
||||
/>{" "}
|
||||
|
||||
8. Choose which type of React component you want to make (Class, or Function component).
|
||||
|
||||
<img
|
||||
src={useBaseUrl("/img/custom-plugins/plugin-4-yeoman-component-type.png")}
|
||||
/>{" "}
|
||||
|
||||
9. Select whether you'd like your visualization to be timeseries-based or not
|
||||
|
||||
<img
|
||||
src={useBaseUrl("/img/custom-plugins/plugin-5-yeoman-timeseries.png")}
|
||||
/>{" "}
|
||||
|
||||
10. Select whether or not you want to include badges at the top of your README file (really only
|
||||
needed if you intend to contribute your plugin to the `superset-ui` repo).
|
||||
|
||||
<img src={useBaseUrl("/img/custom-plugins/plugin-6-yeoman-badges.png")} />{" "}
|
||||
|
||||
11. Admire all the files the generator has created for you. Note that EACH of these is chock full of
|
||||
comments about what they're for, and how best to use them.
|
||||
|
||||
<img src={useBaseUrl("/img/custom-plugins/plugin-7-yeoman-files.png")} />{" "}
|
||||
|
||||
### Add your Plugin to Superset (with NPM Link)
|
||||
|
||||
Now, we want to see this thing actually RUN! To do that, we'll add your package to Superset and
|
||||
embrace the magic power of `npm link` to see it in-situ, without needing to **build** the plugin, or
|
||||
open any PRs on Github.
|
||||
|
||||
1. Add your package to the `package.json` file in `superset/superset-frontend`.
|
||||
|
||||
<img src={useBaseUrl("/img/custom-plugins/plugin-8-package-json.png")} />{" "}
|
||||
|
||||
Note: Do _not_ run `npm install`... explanation below.
|
||||
|
||||
2. Add your plugin to the `MainPreset.js` file (located in
|
||||
`superset/superset-frontend/src/visualizations/presets/MainPreset.js`) in two places,
|
||||
alongside the other plugins.
|
||||
|
||||
<img
|
||||
src={useBaseUrl("/img/custom-plugins/plugin-9-mainpreset-import.png")}
|
||||
/>{" "}
|
||||
|
||||
{' '}
|
||||
|
||||
<img
|
||||
src={useBaseUrl("/img/custom-plugins/plugin-9-mainpreset-register.png")}
|
||||
/>
|
||||
|
||||
3. Open a terminal window to `superset/superset-frontend`. If you did the Install Superset
|
||||
steps above, you may still have webpack running there, and you can just stop it with `ctrol-c`.
|
||||
If not, just open a new window and or `cd` to that directory path.
|
||||
|
||||
4) Use `npm link` to symlink plugin, using a relative path to `superset-ui` and your plugin folder,
|
||||
e.g. `npm link ../../superset-ui/plugins/plugin-chart-hello-world`.
|
||||
|
||||
5. Restart your webpack dev server with `npm run dev-server`. You'll know it worked if you see a
|
||||
line stating
|
||||
`[Superset Plugin] Use symlink source for @superset-ui/plugin-chart-hello-world @ ^0.0.0`.
|
||||
|
||||
**NOTE:** If/when you do an `npm install` that erases the symlink generated by `npm link`, so you'll
|
||||
have to redo those steps.
|
||||
|
||||
**NOTE:** Dynamic import is a work in progress. We hope you won't even need to DO this soon. We'll
|
||||
be blogging again when that day comes, we assure you. In short, we have a goal to make editing
|
||||
`package.json` and `MainPreset.js` unnecessary, so all the code changes are made in ONE repo.
|
||||
|
||||
### See it with your own eyes!
|
||||
|
||||
You should now be able to go to the Explore view in your local Superset and add a new chart! You'll
|
||||
see your new plugin when you go to select your viz type.
|
||||
|
||||
<img
|
||||
src={useBaseUrl("/img/custom-plugins/plugin-10-hello-thumbnail.png")}
|
||||
/>{" "}
|
||||
|
||||
Now you can load up some data, and you'll see it appear in the plugin!
|
||||
|
||||
<img src={useBaseUrl("/img/custom-plugins/plugin-11-explore-view.png")} />{" "}
|
||||
|
||||
The plugin also outputs three things to your browser's console:
|
||||
|
||||
- `formData`, a.k.a. everything sent into your viz from the controls
|
||||
- `props`, as output from the `transformProps` file for your plugin's consumption
|
||||
- The actual HTML element, which your plugin has hooks into for any necessary DOM maniupluation
|
||||
|
||||
<img src={useBaseUrl("/img/custom-plugins/plugin-12-console-logs.png")} />{" "}
|
||||
|
||||
## Make it Your Own
|
||||
|
||||
Now you're free to run wild with your new plugin! Here are a few places to start digging in:
|
||||
|
||||
### Read the comments and docs
|
||||
|
||||
Take a look through the full file tree of the plugin. The Readme gives details for the job of each
|
||||
file. EACH of these files has been annotated with extensive comments of what the file is for, and
|
||||
the basics of what you can do with it.
|
||||
|
||||
### Take control!
|
||||
|
||||
The plugin includes a couple of example controls, but you can certainly continue to add as many as
|
||||
you need to. The comments/documentation within the controls file is a start, but we recommend
|
||||
looking at existing `superset-ui` plugins for more examples of how you can implement controls to
|
||||
enhance your queries, work with your data, and change your visualization's display.
|
||||
|
||||
### Build the perfect query
|
||||
|
||||
The `buildQuery` file where your plugin actually fetches data from the Superset backend. This file
|
||||
builds he query "context" for your plugin. For a simple plugin, this file needn't do much. There are
|
||||
a couple changes that need to be made for a timeseries plugin, thus the option in the Yeoman
|
||||
generator.
|
||||
|
||||
This file also allows you to add various post-processing operations, to have the Superset backend
|
||||
process your data in various ways (pivoting, etc), but that's a whole other topic we'll cover
|
||||
separately in the near future.
|
||||
|
||||
### Style with Emotion
|
||||
|
||||
Each of these methods lets you add custom CSS styles using Emotion 👩🎤(a CSS-in-JS approach) which
|
||||
has access to Superset's burgeoning set of theme variables, and also automatically scopes the styles
|
||||
to your plugin, so they don't "leak" to other areas of Superset.
|
||||
|
||||
In the Hello World plugin, we've included a few example Theme variables (`colors`, `gridUnit`s, and
|
||||
typographic weights/sizes). We'll be continuing to add more variables to this theme file as we
|
||||
continue to push Superset (and the viz plugins) toward the standards of the Superset redesign (see
|
||||
[SIP-34](https://github.com/apache/superset/issues/8976))
|
||||
|
||||
### Give it a thumbnail
|
||||
|
||||
Because come on... that's the fun part, right?
|
||||
|
||||
### Build it!
|
||||
|
||||
In this tutorial, you built your plugin in the `superset-ui` repo. This means you can use the
|
||||
built-in build scripts that the repo provides. With your terminal of choice, simply `cd` into the
|
||||
root directory of `supeset-ui` and run `yarn build`. This will kick off a build of ALL the Superset
|
||||
plugins and packages, including yours.
|
||||
|
||||
### Test early, test often!
|
||||
|
||||
The Hello World plugin includes some basic Jest tests to act as a starting point to add unit tests
|
||||
to your plugin. These do a quick sanity check that the plugin actually loads correctly, and then run
|
||||
through the basics of making sure that your controls are properly respected by modifying the
|
||||
resulting data and/or props of the plugin. Running `yarn test` from the root directory of
|
||||
`superset-ui` will run all the tests for plugins/packages, including your Hello World.
|
||||
|
||||
### Deploying Custom Visualization to Production
|
||||
|
||||
To deploy plugins to a production environment, you must have additional code
|
||||
inside Superset that includes the npm packages of your plugins so they can be installed in the frontend.
|
||||
|
||||
One option is to build your Dockerfile so it contains your custom visualization packages.
|
||||
|
|
@ -0,0 +1,123 @@
|
|||
---
|
||||
title: Caching
|
||||
hide_title: true
|
||||
sidebar_position: 5
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Caching
|
||||
|
||||
Superset uses [Flask-Caching](https://flask-caching.readthedocs.io/) for caching purpose. For security reasons,
|
||||
there are two separate cache configs for Superset's own metadata (`CACHE_CONFIG`) and charting data queried from
|
||||
connected datasources (`DATA_CACHE_CONFIG`). However, Query results from SQL Lab are stored in another backend
|
||||
called `RESULTS_BACKEND`, See [Async Queries via Celery](/docs/installation/async-queries-celery) for details.
|
||||
|
||||
Configuring caching is as easy as providing `CACHE_CONFIG` and `DATA_CACHE_CONFIG` in your
|
||||
`superset_config.py` that complies with [the Flask-Caching specifications](https://flask-caching.readthedocs.io/en/latest/#configuring-flask-caching).
|
||||
|
||||
Flask-Caching supports various caching backends, including Redis, Memcached, SimpleCache (in-memory), or the
|
||||
local filesystem.
|
||||
|
||||
- Memcached: we recommend using [pylibmc](https://pypi.org/project/pylibmc/) client library as
|
||||
`python-memcached` does not handle storing binary data correctly.
|
||||
- Redis: we recommend the [redis](https://pypi.python.org/pypi/redis) Python package
|
||||
|
||||
Both of these libraries can be installed using pip.
|
||||
|
||||
For chart data, Superset goes up a “timeout search path”, from a slice's configuration
|
||||
to the datasource’s, the database’s, then ultimately falls back to the global default
|
||||
defined in `DATA_CACHE_CONFIG`.
|
||||
|
||||
```
|
||||
DATA_CACHE_CONFIG = {
|
||||
'CACHE_TYPE': 'redis',
|
||||
'CACHE_DEFAULT_TIMEOUT': 60 * 60 * 24, # 1 day default (in secs)
|
||||
'CACHE_KEY_PREFIX': 'superset_results',
|
||||
'CACHE_REDIS_URL': 'redis://localhost:6379/0',
|
||||
}
|
||||
```
|
||||
|
||||
Custom cache backends are also supported. See [here](https://flask-caching.readthedocs.io/en/latest/#custom-cache-backends) for specifics.
|
||||
|
||||
Superset has a Celery task that will periodically warm up the cache based on different strategies.
|
||||
To use it, add the following to the `CELERYBEAT_SCHEDULE` section in `config.py`:
|
||||
|
||||
```python
|
||||
CELERYBEAT_SCHEDULE = {
|
||||
'cache-warmup-hourly': {
|
||||
'task': 'cache-warmup',
|
||||
'schedule': crontab(minute=0, hour='*'), # hourly
|
||||
'kwargs': {
|
||||
'strategy_name': 'top_n_dashboards',
|
||||
'top_n': 5,
|
||||
'since': '7 days ago',
|
||||
},
|
||||
},
|
||||
}
|
||||
```
|
||||
|
||||
This will cache all the charts in the top 5 most popular dashboards every hour. For other
|
||||
strategies, check the `superset/tasks/cache.py` file.
|
||||
|
||||
### Caching Thumbnails
|
||||
|
||||
This is an optional feature that can be turned on by activating it’s feature flag on config:
|
||||
|
||||
```
|
||||
FEATURE_FLAGS = {
|
||||
"THUMBNAILS": True,
|
||||
"THUMBNAILS_SQLA_LISTENERS": True,
|
||||
}
|
||||
```
|
||||
|
||||
For this feature you will need a cache system and celery workers. All thumbnails are stored on cache
|
||||
and are processed asynchronously by the workers.
|
||||
|
||||
An example config where images are stored on S3 could be:
|
||||
|
||||
```python
|
||||
from flask import Flask
|
||||
from s3cache.s3cache import S3Cache
|
||||
|
||||
...
|
||||
|
||||
class CeleryConfig(object):
|
||||
BROKER_URL = "redis://localhost:6379/0"
|
||||
CELERY_IMPORTS = ("superset.sql_lab", "superset.tasks", "superset.tasks.thumbnails")
|
||||
CELERY_RESULT_BACKEND = "redis://localhost:6379/0"
|
||||
CELERYD_PREFETCH_MULTIPLIER = 10
|
||||
CELERY_ACKS_LATE = True
|
||||
|
||||
|
||||
CELERY_CONFIG = CeleryConfig
|
||||
|
||||
def init_thumbnail_cache(app: Flask) -> S3Cache:
|
||||
return S3Cache("bucket_name", 'thumbs_cache/')
|
||||
|
||||
|
||||
THUMBNAIL_CACHE_CONFIG = init_thumbnail_cache
|
||||
# Async selenium thumbnail task will use the following user
|
||||
THUMBNAIL_SELENIUM_USER = "Admin"
|
||||
```
|
||||
|
||||
Using the above example cache keys for dashboards will be `superset_thumb__dashboard__{ID}`. You can
|
||||
override the base URL for selenium using:
|
||||
|
||||
```
|
||||
WEBDRIVER_BASEURL = "https://superset.company.com"
|
||||
```
|
||||
|
||||
Additional selenium web drive configuration can be set using `WEBDRIVER_CONFIGURATION`. You can
|
||||
implement a custom function to authenticate selenium. The default function uses the `flask-login`
|
||||
session cookie. Here's an example of a custom function signature:
|
||||
|
||||
```python
|
||||
def auth_driver(driver: WebDriver, user: "User") -> WebDriver:
|
||||
pass
|
||||
```
|
||||
|
||||
Then on configuration:
|
||||
|
||||
```
|
||||
WEBDRIVER_AUTH_FUNC = auth_driver
|
||||
```
|
||||
|
|
@ -0,0 +1,304 @@
|
|||
---
|
||||
title: Configuring Superset
|
||||
hide_title: true
|
||||
sidebar_position: 3
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Configuring Superset
|
||||
|
||||
### Configuration
|
||||
|
||||
To configure your application, you need to create a file `superset_config.py` and add it to your
|
||||
`PYTHONPATH`. Here are some of the parameters you can set in that file:
|
||||
|
||||
```
|
||||
# Superset specific config
|
||||
ROW_LIMIT = 5000
|
||||
|
||||
SUPERSET_WEBSERVER_PORT = 8088
|
||||
|
||||
# Flask App Builder configuration
|
||||
# Your App secret key
|
||||
SECRET_KEY = '\2\1thisismyscretkey\1\2\e\y\y\h'
|
||||
|
||||
# The SQLAlchemy connection string to your database backend
|
||||
# This connection defines the path to the database that stores your
|
||||
# superset metadata (slices, connections, tables, dashboards, ...).
|
||||
# Note that the connection information to connect to the datasources
|
||||
# you want to explore are managed directly in the web UI
|
||||
SQLALCHEMY_DATABASE_URI = 'sqlite:////path/to/superset.db'
|
||||
|
||||
# Flask-WTF flag for CSRF
|
||||
WTF_CSRF_ENABLED = True
|
||||
# Add endpoints that need to be exempt from CSRF protection
|
||||
WTF_CSRF_EXEMPT_LIST = []
|
||||
# A CSRF token that expires in 1 year
|
||||
WTF_CSRF_TIME_LIMIT = 60 * 60 * 24 * 365
|
||||
|
||||
# Set this API key to enable Mapbox visualizations
|
||||
MAPBOX_API_KEY = ''
|
||||
```
|
||||
|
||||
All the parameters and default values defined in
|
||||
[https://github.com/apache/superset/blob/master/superset/config.py](https://github.com/apache/superset/blob/master/superset/config.py)
|
||||
can be altered in your local `superset_config.py`. Administrators will want to read through the file
|
||||
to understand what can be configured locally as well as the default values in place.
|
||||
|
||||
Since `superset_config.py` acts as a Flask configuration module, it can be used to alter the
|
||||
settings Flask itself, as well as Flask extensions like `flask-wtf`, `flask-caching`, `flask-migrate`,
|
||||
and `flask-appbuilder`. Flask App Builder, the web framework used by Superset, offers many
|
||||
configuration settings. Please consult the
|
||||
[Flask App Builder Documentation](https://flask-appbuilder.readthedocs.org/en/latest/config.html)
|
||||
for more information on how to configure it.
|
||||
|
||||
Make sure to change:
|
||||
|
||||
- `SQLALCHEMY_DATABASE_URI`: by default it is stored at ~/.superset/superset.db
|
||||
- `SECRET_KEY`: to a long random string
|
||||
|
||||
If you need to exempt endpoints from CSRF (e.g. if you are running a custom auth postback endpoint),
|
||||
you can add the endpoints to `WTF_CSRF_EXEMPT_LIST`:
|
||||
|
||||
```
|
||||
WTF_CSRF_EXEMPT_LIST = [‘’]
|
||||
```
|
||||
|
||||
### Running on a WSGI HTTP Server
|
||||
|
||||
While you can run Superset on NGINX or Apache, we recommend using Gunicorn in async mode. This
|
||||
enables impressive concurrency even and is fairly easy to install and configure. Please refer to the
|
||||
documentation of your preferred technology to set up this Flask WSGI application in a way that works
|
||||
well in your environment. Here’s an async setup known to work well in production:
|
||||
|
||||
```
|
||||
-w 10 \
|
||||
-k gevent \
|
||||
--timeout 120 \
|
||||
-b 0.0.0.0:6666 \
|
||||
--limit-request-line 0 \
|
||||
--limit-request-field_size 0 \
|
||||
--statsd-host localhost:8125 \
|
||||
"superset.app:create_app()"
|
||||
```
|
||||
|
||||
Refer to the [Gunicorn documentation](https://docs.gunicorn.org/en/stable/design.html) for more
|
||||
information. _Note that the development web server (`superset run` or `flask run`) is not intended
|
||||
for production use._
|
||||
|
||||
If you're not using Gunicorn, you may want to disable the use of `flask-compress` by setting
|
||||
`COMPRESS_REGISTER = False` in your `superset_config.py`.
|
||||
|
||||
### Configuration Behind a Load Balancer
|
||||
|
||||
If you are running superset behind a load balancer or reverse proxy (e.g. NGINX or ELB on AWS), you
|
||||
may need to utilize a healthcheck endpoint so that your load balancer knows if your superset
|
||||
instance is running. This is provided at `/health` which will return a 200 response containing “OK”
|
||||
if the the webserver is running.
|
||||
|
||||
If the load balancer is inserting `X-Forwarded-For/X-Forwarded-Proto` headers, you should set
|
||||
`ENABLE_PROXY_FIX = True` in the superset config file (`superset_config.py`) to extract and use the
|
||||
headers.
|
||||
|
||||
In case the reverse proxy is used for providing SSL encryption, an explicit definition of the
|
||||
`X-Forwarded-Proto` may be required. For the Apache webserver this can be set as follows:
|
||||
|
||||
```
|
||||
RequestHeader set X-Forwarded-Proto "https"
|
||||
```
|
||||
|
||||
### Custom OAuth2 Configuration
|
||||
|
||||
Beyond FAB supported providers (Github, Twitter, LinkedIn, Google, Azure, etc), its easy to connect
|
||||
Superset with other OAuth2 Authorization Server implementations that support “code” authorization.
|
||||
|
||||
Make sure the pip package [`Authlib`](https://authlib.org/) is installed on the webserver.
|
||||
|
||||
First, configure authorization in Superset `superset_config.py`.
|
||||
|
||||
```python
|
||||
AUTH_TYPE = AUTH_OAUTH
|
||||
OAUTH_PROVIDERS = [
|
||||
{ 'name':'egaSSO',
|
||||
'token_key':'access_token', # Name of the token in the response of access_token_url
|
||||
'icon':'fa-address-card', # Icon for the provider
|
||||
'remote_app': {
|
||||
'client_id':'myClientId', # Client Id (Identify Superset application)
|
||||
'client_secret':'MySecret', # Secret for this Client Id (Identify Superset application)
|
||||
'client_kwargs':{
|
||||
'scope': 'read' # Scope for the Authorization
|
||||
},
|
||||
'access_token_method':'POST', # HTTP Method to call access_token_url
|
||||
'access_token_params':{ # Additional parameters for calls to access_token_url
|
||||
'client_id':'myClientId'
|
||||
},
|
||||
'access_token_headers':{ # Additional headers for calls to access_token_url
|
||||
'Authorization': 'Basic Base64EncodedClientIdAndSecret'
|
||||
},
|
||||
'api_base_url':'https://myAuthorizationServer/oauth2AuthorizationServer/',
|
||||
'access_token_url':'https://myAuthorizationServer/oauth2AuthorizationServer/token',
|
||||
'authorize_url':'https://myAuthorizationServer/oauth2AuthorizationServer/authorize'
|
||||
}
|
||||
}
|
||||
]
|
||||
|
||||
# Will allow user self registration, allowing to create Flask users from Authorized User
|
||||
AUTH_USER_REGISTRATION = True
|
||||
|
||||
# The default user self registration role
|
||||
AUTH_USER_REGISTRATION_ROLE = "Public"
|
||||
```
|
||||
|
||||
Then, create a `CustomSsoSecurityManager` that extends `SupersetSecurityManager` and overrides
|
||||
`oauth_user_info`:
|
||||
|
||||
```python
|
||||
import logging
|
||||
from superset.security import SupersetSecurityManager
|
||||
|
||||
class CustomSsoSecurityManager(SupersetSecurityManager):
|
||||
|
||||
def oauth_user_info(self, provider, response=None):
|
||||
logging.debug("Oauth2 provider: {0}.".format(provider))
|
||||
if provider == 'egaSSO':
|
||||
# As example, this line request a GET to base_url + '/' + userDetails with Bearer Authentication,
|
||||
# and expects that authorization server checks the token, and response with user details
|
||||
me = self.appbuilder.sm.oauth_remotes[provider].get('userDetails').data
|
||||
logging.debug("user_data: {0}".format(me))
|
||||
return { 'name' : me['name'], 'email' : me['email'], 'id' : me['user_name'], 'username' : me['user_name'], 'first_name':'', 'last_name':''}
|
||||
...
|
||||
```
|
||||
|
||||
This file must be located at the same directory than `superset_config.py` with the name
|
||||
`custom_sso_security_manager.py`. Finally, add the following 2 lines to `superset_config.py`:
|
||||
|
||||
```
|
||||
from custom_sso_security_manager import CustomSsoSecurityManager
|
||||
CUSTOM_SECURITY_MANAGER = CustomSsoSecurityManager
|
||||
```
|
||||
|
||||
**Notes**
|
||||
|
||||
- The redirect URL will be `https://<superset-webserver>/oauth-authorized/<provider-name>`
|
||||
When configuring an OAuth2 authorization provider if needed. For instance, the redirect URL will
|
||||
be `https://<superset-webserver>/oauth-authorized/egaSSO` for the above configuration.
|
||||
|
||||
- If an OAuth2 authorization server supports OpenID Connect 1.0, you could configure its configuration
|
||||
document URL only without providing `api_base_url`, `access_token_url`, `authorize_url` and other
|
||||
required options like user info endpoint, jwks uri etc. For instance:
|
||||
```python
|
||||
OAUTH_PROVIDERS = [
|
||||
{ 'name':'egaSSO',
|
||||
'token_key':'access_token', # Name of the token in the response of access_token_url
|
||||
'icon':'fa-address-card', # Icon for the provider
|
||||
'remote_app': {
|
||||
'client_id':'myClientId', # Client Id (Identify Superset application)
|
||||
'client_secret':'MySecret', # Secret for this Client Id (Identify Superset application)
|
||||
'server_metadata_url': 'https://myAuthorizationServer/.well-known/openid-configuration'
|
||||
}
|
||||
}
|
||||
]
|
||||
```
|
||||
|
||||
### Flask app Configuration Hook
|
||||
|
||||
`FLASK_APP_MUTATOR` is a configuration function that can be provided in your environment, receives
|
||||
the app object and can alter it in any way. For example, add `FLASK_APP_MUTATOR` into your
|
||||
`superset_config.py` to setup session cookie expiration time to 24 hours:
|
||||
|
||||
```python
|
||||
from flask import session
|
||||
from flask import Flask
|
||||
|
||||
|
||||
def make_session_permanent():
|
||||
'''
|
||||
Enable maxAge for the cookie 'session'
|
||||
'''
|
||||
session.permanent = True
|
||||
|
||||
# Set up max age of session to 24 hours
|
||||
PERMANENT_SESSION_LIFETIME = timedelta(hours=24)
|
||||
def FLASK_APP_MUTATOR(app: Flask) -> None:
|
||||
app.before_request_funcs.setdefault(None, []).append(make_session_permanent)
|
||||
```
|
||||
|
||||
### Feature Flags
|
||||
|
||||
To support a diverse set of users, Superset has some features that are not enabled by default. For
|
||||
example, some users have stronger security restrictions, while some others may not. So Superset
|
||||
allow users to enable or disable some features by config. For feature owners, you can add optional
|
||||
functionalities in Superset, but will be only affected by a subset of users.
|
||||
|
||||
You can enable or disable features with flag from `superset_config.py`:
|
||||
|
||||
```python
|
||||
FEATURE_FLAGS = {
|
||||
'CLIENT_CACHE': False,
|
||||
'ENABLE_EXPLORE_JSON_CSRF_PROTECTION': False,
|
||||
'PRESTO_EXPAND_DATA': False,
|
||||
}
|
||||
```
|
||||
|
||||
A current list of feature flags can be found in [RESOURCES/FEATURE_FLAGS.md](https://github.com/apache/superset/blob/master/RESOURCES/FEATURE_FLAGS.md).
|
||||
|
||||
### SIP 15
|
||||
|
||||
[Superset Improvement Proposal 15](https://github.com/apache/superset/issues/6360) aims to
|
||||
ensure that time intervals are handled in a consistent and transparent manner for both the Druid and
|
||||
SQLAlchemy connectors.
|
||||
|
||||
Prior to SIP-15 SQLAlchemy used inclusive endpoints however these may behave like exclusive for
|
||||
string columns (due to lexicographical ordering) if no formatting was defined and the column
|
||||
formatting did not conform to an ISO 8601 date-time (refer to the SIP for details).
|
||||
|
||||
To remedy this rather than having to define the date/time format for every non-IS0 8601 date-time
|
||||
column, once can define a default column mapping on a per database level via the `extra` parameter:
|
||||
|
||||
```
|
||||
{
|
||||
"python_date_format_by_column_name": {
|
||||
"ds": "%Y-%m-%d"
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
**New Deployments**
|
||||
|
||||
All new deployments should enable SIP-15 by setting this value in `superset_config.py`:
|
||||
|
||||
```
|
||||
SIP_15_ENABLED = True
|
||||
|
||||
```
|
||||
|
||||
**Existing Deployments**
|
||||
|
||||
Given that it is not apparent whether the chart creator was aware of the time range inconsistencies
|
||||
(and adjusted the endpoints accordingly) changing the behavior of all charts is overly aggressive.
|
||||
Instead SIP-15 proivides a soft transistion allowing producers (chart owners) to see the impact of
|
||||
the proposed change and adjust their charts accordingly.
|
||||
|
||||
Prior to enabling SIP-15, existing deployments should communicate to their users the impact of the
|
||||
change and define a grace period end date (exclusive of course) after which all charts will conform
|
||||
to the [start, end) interval.
|
||||
|
||||
```python
|
||||
from dateime import date
|
||||
|
||||
SIP_15_ENABLED = True
|
||||
SIP_15_GRACE_PERIOD_END = date(<YYYY>, <MM>, <DD>)
|
||||
```
|
||||
|
||||
To aid with transparency the current endpoint behavior is explicitly called out in the chart time
|
||||
range (post SIP-15 this will be [start, end) for all connectors and databases). One can override the
|
||||
defaults on a per database level via the `extra` parameter.
|
||||
|
||||
```python
|
||||
{
|
||||
"time_range_endpoints": ["inclusive", "inclusive"]
|
||||
}
|
||||
```
|
||||
|
||||
Note in a future release the interim SIP-15 logic will be removed (including the
|
||||
`time_grain_endpoints` form-data field) via a code change and Alembic migration.
|
||||
|
|
@ -0,0 +1,58 @@
|
|||
---
|
||||
title: Event Logging
|
||||
hide_title: true
|
||||
sidebar_position: 6
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Logging
|
||||
|
||||
### Event Logging
|
||||
|
||||
Superset by default logs special action events in its internal database. These logs can be accessed
|
||||
on the UI by navigating to **Security > Action Log**. You can freely customize these logs by
|
||||
implementing your own event log class.
|
||||
|
||||
Here's an example of a simple JSON-to-stdout class:
|
||||
|
||||
```python
|
||||
def log(self, user_id, action, *args, **kwargs):
|
||||
records = kwargs.get('records', list())
|
||||
dashboard_id = kwargs.get('dashboard_id')
|
||||
slice_id = kwargs.get('slice_id')
|
||||
duration_ms = kwargs.get('duration_ms')
|
||||
referrer = kwargs.get('referrer')
|
||||
|
||||
for record in records:
|
||||
log = dict(
|
||||
action=action,
|
||||
json=record,
|
||||
dashboard_id=dashboard_id,
|
||||
slice_id=slice_id,
|
||||
duration_ms=duration_ms,
|
||||
referrer=referrer,
|
||||
user_id=user_id
|
||||
)
|
||||
print(json.dumps(log))
|
||||
```
|
||||
|
||||
End by updating your config to pass in an instance of the logger you want to use:
|
||||
|
||||
```
|
||||
EVENT_LOGGER = JSONStdOutEventLogger()
|
||||
```
|
||||
|
||||
### StatsD Logging
|
||||
|
||||
Superset can be instrumented to log events to StatsD if desired. Most endpoints hit are logged as
|
||||
well as key events like query start and end in SQL Lab.
|
||||
|
||||
To setup StatsD logging, it’s a matter of configuring the logger in your `superset_config.py`.
|
||||
|
||||
```python
|
||||
from superset.stats_logger import StatsdStatsLogger
|
||||
STATS_LOGGER = StatsdStatsLogger(host='localhost', port=8125, prefix='superset')
|
||||
```
|
||||
|
||||
Note that it’s also possible to implement you own logger by deriving
|
||||
`superset.stats_logger.BaseStatsLogger`.
|
||||
|
|
@ -0,0 +1,161 @@
|
|||
---
|
||||
title: Installing From Scratch
|
||||
hide_title: true
|
||||
sidebar_position: 2
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Installing Superset from Scratch
|
||||
|
||||
### OS Dependencies
|
||||
|
||||
Superset stores database connection information in its metadata database. For that purpose, we use
|
||||
the cryptography Python library to encrypt connection passwords. Unfortunately, this library has OS
|
||||
level dependencies.
|
||||
|
||||
**Debian and Ubuntu**
|
||||
|
||||
The following command will ensure that the required dependencies are installed:
|
||||
|
||||
```
|
||||
sudo apt-get install build-essential libssl-dev libffi-dev python-dev python-pip libsasl2-dev libldap2-dev
|
||||
```
|
||||
|
||||
In Ubuntu 20.04 the following command will ensure that the required dependencies are installed:
|
||||
|
||||
```
|
||||
sudo apt-get install build-essential libssl-dev libffi-dev python3-dev python3-pip libsasl2-dev libldap2-dev
|
||||
```
|
||||
|
||||
**Fedora and RHEL-derivative Linux distributions**
|
||||
|
||||
Install the following packages using the `yum` package manager:
|
||||
|
||||
```
|
||||
sudo yum install gcc gcc-c++ libffi-devel python-devel python-pip python-wheel openssl-devel cyrus-sasl-devel openldap-devel
|
||||
```
|
||||
|
||||
In more recent versions of CentOS and Fedora, you may need to install a slightly different set of packages using `dnf`:
|
||||
|
||||
```
|
||||
sudo dnf install gcc gcc-c++ libffi-devel python3-devel python3-pip python3-wheel openssl-devel cyrus-sasl-devel openldap-devel
|
||||
```
|
||||
|
||||
Also, on CentOS, you may need to upgrade pip for the install to work:
|
||||
|
||||
```
|
||||
pip3 install --upgrade pip
|
||||
```
|
||||
|
||||
**Mac OS X**
|
||||
|
||||
If you're not on the latest version of OS X, we recommend upgrading because we've found that many
|
||||
issues people have run into are linked to older versions of Mac OS X. After updating, install the
|
||||
latest version of XCode command line tools:
|
||||
|
||||
```
|
||||
xcode-select --install
|
||||
```
|
||||
|
||||
We don't recommend using the system installed Python. Instead, first install the
|
||||
[homebrew](https://brew.sh/) manager and then run the following commands:
|
||||
|
||||
```
|
||||
brew install readline pkg-config libffi openssl mysql postgres
|
||||
```
|
||||
|
||||
You should install a recent version of Python (the official docker image uses 3.8.12). We'd recommend using a Python version manager like [pyenv](https://github.com/pyenv/pyenv) (and also [pyenv-virtualenv](https://github.com/pyenv/pyenv-virtualenv)).
|
||||
|
||||
Let's also make sure we have the latest version of `pip` and `setuptools`:
|
||||
|
||||
```
|
||||
pip install --upgrade setuptools pip
|
||||
```
|
||||
|
||||
Lastly, you may need to set LDFLAGS and CFLAGS for certain Python packages to properly build. You can export these variables with:
|
||||
|
||||
```
|
||||
export LDFLAGS="-L$(brew --prefix openssl)/lib"
|
||||
export CFLAGS="-I$(brew --prefix openssl)/include"
|
||||
```
|
||||
|
||||
These will now be available when pip installing requirements.
|
||||
|
||||
### Python Virtual Environment
|
||||
|
||||
We highly recommend installing Superset inside of a virtual environment. Python ships with
|
||||
`virtualenv` out of the box. If you're using [pyenv](https://github.com/pyenv/pyenv), you can install [pyenv-virtualenv](https://github.com/pyenv/pyenv-virtualenv). Or you can install it with `pip`:
|
||||
|
||||
```
|
||||
pip install virtualenv
|
||||
```
|
||||
|
||||
You can create and activate a virtual environment using:
|
||||
|
||||
```
|
||||
# virtualenv is shipped in Python 3.6+ as venv instead of pyvenv.
|
||||
# See https://docs.python.org/3.6/library/venv.html
|
||||
python3 -m venv venv
|
||||
. venv/bin/activate
|
||||
```
|
||||
|
||||
Or with pyenv-virtualenv:
|
||||
|
||||
```
|
||||
# Here we name the virtual env 'superset'
|
||||
pyenv virtualenv superset
|
||||
pyenv activate superset
|
||||
```
|
||||
|
||||
Once you activated your virtual environment, all of the Python packages you install or uninstall
|
||||
will be confined to this environment. You can exit the environment by running `deactivate` on the
|
||||
command line.
|
||||
|
||||
### Installing and Initializing Superset
|
||||
|
||||
First, start by installing `apache-superset`:
|
||||
|
||||
```
|
||||
pip install apache-superset
|
||||
```
|
||||
|
||||
Then, you need to initialize the database:
|
||||
|
||||
```
|
||||
superset db upgrade
|
||||
```
|
||||
|
||||
Finish installing by running through the following commands:
|
||||
|
||||
```
|
||||
# Create an admin user in your metadata database (use `admin` as username to be able to load the examples)
|
||||
$ export FLASK_APP=superset
|
||||
superset fab create-admin
|
||||
|
||||
# Load some data to play with
|
||||
superset load_examples
|
||||
|
||||
# Create default roles and permissions
|
||||
superset init
|
||||
|
||||
# To start a development web server on port 8088, use -p to bind to another port
|
||||
superset run -p 8088 --with-threads --reload --debugger
|
||||
```
|
||||
|
||||
If everything worked, you should be able to navigate to `hostname:port` in your browser (e.g.
|
||||
locally by default at `localhost:8088`) and login using the username and password you created.
|
||||
|
||||
### Installing Superset with Helm in Kubernetes
|
||||
|
||||
You can install Superset into Kubernetes with [Helm](https://helm.sh/). The chart is located in
|
||||
the `helm/` directory.
|
||||
|
||||
To install Superset in your Kubernetes cluster with Helm 3, run:
|
||||
|
||||
```
|
||||
helm dep up ./helm/superset
|
||||
helm upgrade --install superset ./helm/superset
|
||||
```
|
||||
|
||||
Note that the above command will install Superset into `default` namespace of your Kubernetes
|
||||
cluster.
|
||||
|
|
@ -0,0 +1,108 @@
|
|||
---
|
||||
title: Installing Locally Using Docker Compose
|
||||
hide_title: true
|
||||
sidebar_position: 1
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Installing Superset Locally Using Docker Compose
|
||||
|
||||
The fastest way to try Superset locally is using Docker and Docker Compose on a Linux or Mac OSX
|
||||
computer. Superset does not have official support for Windows, so we have provided a VM workaround
|
||||
below.
|
||||
|
||||
### 1. Install a Docker Engine and Docker Compose
|
||||
|
||||
**Mac OSX**
|
||||
|
||||
[Install Docker for Mac](https://docs.docker.com/docker-for-mac/install/), which includes the Docker
|
||||
engine and a recent version of `docker-compose` out of the box.
|
||||
|
||||
Once you have Docker for Mac installed, open up the preferences pane for Docker, go to the
|
||||
"Resources" section and increase the allocated memory to 6GB. With only the 2GB of RAM allocated by
|
||||
default, Superset will fail to start.
|
||||
|
||||
**Linux**
|
||||
|
||||
[Install Docker on Linux](https://docs.docker.com/engine/install/) by following Docker’s
|
||||
instructions for whichever flavor of Linux suits you. Because `docker-compose` is not installed as
|
||||
part of the base Docker installation on Linux, once you have a working engine, follow the
|
||||
[docker-compose installation instructions](https://docs.docker.com/compose/install/) for Linux.
|
||||
|
||||
**Windows**
|
||||
|
||||
Superset is not officially supported on Windows unfortunately. One option for Windows users to
|
||||
try out Superset locally is to install an Ubuntu Desktop VM via
|
||||
[VirtualBox](https://www.virtualbox.org/) and proceed with the Docker on Linux instructions inside
|
||||
of that VM. We recommend assigning at least 8GB of RAM to the virtual machine as well as
|
||||
provisioning a hard drive of at least 40GB, so that there will be enough space for both the OS and
|
||||
all of the required dependencies. Docker Desktop [recently added support for Windows Subsystem for Linux (WSL) 2](https://docs.docker.com/docker-for-windows/wsl/), which may be another option.
|
||||
|
||||
### 2. Clone Superset's Github repository
|
||||
|
||||
[Clone Superset's repo](https://github.com/apache/superset) in your terminal with the
|
||||
following command:
|
||||
|
||||
```bash
|
||||
$ git clone https://github.com/apache/superset.git
|
||||
```
|
||||
|
||||
Once that command completes successfully, you should see a new `superset` folder in your
|
||||
current directory.
|
||||
|
||||
### 3. Launch Superset Through Docker Compose
|
||||
|
||||
Navigate to the folder you created in step 1:
|
||||
|
||||
```bash
|
||||
$ cd superset
|
||||
```
|
||||
|
||||
Then, run the following command:
|
||||
|
||||
```bash
|
||||
$ docker-compose -f docker-compose-non-dev.yml up
|
||||
```
|
||||
|
||||
You should see a wall of logging output from the containers being launched on your machine. Once
|
||||
this output slows, you should have a running instance of Superset on your local machine!
|
||||
|
||||
**Note:** This will bring up superset in a non-dev mode, changes to the codebase will not be reflected.
|
||||
If you would like to run superset in dev mode to test local changes, simply replace the previous command with: `docker-compose up`,
|
||||
and wait for the `superset_node` container to finish building the assets.
|
||||
|
||||
#### Configuring Docker Compose
|
||||
|
||||
The following is for users who want to configure how Superset starts up in Docker Compose; otherwise, you can skip to the next section.
|
||||
|
||||
You can configure the Docker Compose settings for dev and non-dev mode with `docker/.env` and `docker/.env-non-dev` respectively. These environment files set the environment for most containers in the Docker Compose setup, and some variables affect multiple containers and others only single ones.
|
||||
|
||||
One important variable is `SUPERSET_LOAD_EXAMPLES` which determines whether the `superset_init` container will load example data and visualizations into the database and Superset. These examples are quite helpful for most people, but probably unnecessary for experienced users. The loading process can sometimes take a few minutes and a good amount of CPU, so you may want to disable it on a resource-constrained device.
|
||||
|
||||
**Note:** Users often want to connect to other databases from Superset. Currently, the easiest way to do this is to modify the `docker-compose-non-dev.yml` file and add your database as a service that the other services depend on (via `x-superset-depends-on`). Others have attempted to set `network_mode: host` on the Superset services, but these generally break the installation, because the configuration requires use of the Docker Compose DNS resolver for the service names. If you have a good solution for this, let us know!
|
||||
|
||||
### 4. Log in to Superset
|
||||
|
||||
Your local Superset instance also includes a Postgres server to store your data and is already
|
||||
pre-loaded with some example datasets that ship with Superset. You can access Superset now via your
|
||||
web browser by visiting `http://localhost:8088`. Note that many browsers now default to `https` - if
|
||||
yours is one of them, please make sure it uses `http`.
|
||||
|
||||
Log in with the default username and password:
|
||||
|
||||
```bash
|
||||
username: admin
|
||||
```
|
||||
|
||||
```bash
|
||||
password: admin
|
||||
```
|
||||
|
||||
### 5. Connecting your local database instance to superset
|
||||
|
||||
When running Superset using `docker` or `docker-compose` it runs in its own docker container, as if the Superset was running in a separate machine entirely. Therefore attempts to connect to your local database with hostname `localhost` won't work as `localhost` refers to the docker container Superset is running in, and not your actual host machine. Fortunately, docker provides an easy way to access network resources in the host machine from inside a container, and we will leverage this capability to connect to our local database instance.
|
||||
|
||||
Here the instructions are for connecting to postgresql (which is running on your host machine) from Superset (which is running in its docker container). Other databases may have slightly different configurations but gist would be same and boils down to 2 steps -
|
||||
|
||||
1. **(Mac users may skip this step)** Configuring the local postgresql/database instance to accept public incoming connections. By default postgresql only allows incoming connections from `localhost` only, but re-iterating once again, `localhosts` are different for host machine and docker container. For postgresql this involves make one-line changes to the files `postgresql.conf` and `pg_hba.conf`, you can find helpful links tailored to your OS / PG version on the web easily for this task. For docker it suffices to only whitelist IPs `172.0.0.0/8` instead of `*`, but in any case you are _warned_ that doing this in a production database _may_ have disastrous consequences as you are opening your database to the public internet.
|
||||
2. Instead of `localhost`, try using `host.docker.internal` (Mac users) or `172.18.0.1` (Linux users) as the host name when attempting to connect to the database. This is docker internal detail, what is happening is that in Mac systems docker creates a dns entry for the host name `host.docker.internal` which resolves to the correct address for the host machine, whereas in linux this is not the case (at least by default). If neither of these 2 hostnames work then you may want to find the exact host name you want to use, for that you can do `ifconfig` or `ip addr show` and look at the IP address of `docker0` interface that must have been created by docker for you. Alternately if you don't even see the `docker0` interface try (if needed with sudo) `docker network inspect bridge` and see if there is an entry for `"Gateway"` and note the IP address.
|
||||
|
|
@ -0,0 +1,44 @@
|
|||
---
|
||||
title: Additional Networking Settings
|
||||
hide_title: true
|
||||
sidebar_position: 4
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Additional Networking Settings
|
||||
|
||||
### CORS
|
||||
|
||||
To configure CORS, or cross-origin resource sharing, the following dependency must be installed:
|
||||
|
||||
```python
|
||||
pip install apache-superset[cors]
|
||||
```
|
||||
|
||||
The following keys in `superset_config.py` can be specified to configure CORS:
|
||||
|
||||
- `ENABLE_CORS`: Must be set to `True` in order to enable CORS
|
||||
- `CORS_OPTIONS`: options passed to Flask-CORS
|
||||
([documentation](https://flask-cors.corydolphin.com/en/latest/api.html#extension))
|
||||
|
||||
### Domain Sharding
|
||||
|
||||
Chrome allows up to 6 open connections per domain at a time. When there are more than 6 slices in
|
||||
dashboard, a lot of time fetch requests are queued up and wait for next available socket.
|
||||
[PR 5039](https://github.com/apache/superset/pull/5039) adds domain sharding to Superset,
|
||||
and this feature will be enabled by configuration only (by default Superset doesn’t allow
|
||||
cross-domain request).
|
||||
|
||||
Add the following setting in your `superset_config.py` file:
|
||||
|
||||
- `SUPERSET_WEBSERVER_DOMAINS`: list of allowed hostnames for domain sharding feature.
|
||||
|
||||
### Middleware
|
||||
|
||||
Superset allows you to add your own middleware. To add your own middleware, update the
|
||||
`ADDITIONAL_MIDDLEWARE` key in your `superset_config.py`. `ADDITIONAL_MIDDLEWARE` should be a list
|
||||
of your additional middleware classes.
|
||||
|
||||
For example, to use `AUTH_REMOTE_USER` from behind a proxy server like nginx, you have to add a
|
||||
simple middleware class to add the value of `HTTP_X_PROXY_REMOTE_USER` (or any other custom header
|
||||
from the proxy) to Gunicorn’s `REMOTE_USER` environment variable:
|
||||
|
|
@ -0,0 +1,371 @@
|
|||
---
|
||||
title: Running on Kubernetes
|
||||
hide_title: true
|
||||
sidebar_position: 12
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Running on Kubernetes
|
||||
|
||||
Running on Kubernetes is supported with the provided [Helm](https://helm.sh/) chart found in the official [Superset helm repository](https://apache.github.io/superset/index.yaml).
|
||||
|
||||
### Prerequisites
|
||||
|
||||
- A Kubernetes cluster
|
||||
- Helm installed
|
||||
|
||||
### Running
|
||||
|
||||
1. Add the Superset helm repository
|
||||
|
||||
```sh
|
||||
helm repo add superset https://apache.github.io/superset
|
||||
"superset" has been added to your repositories
|
||||
```
|
||||
|
||||
2. View charts in repo
|
||||
|
||||
```sh
|
||||
helm search repo superset
|
||||
NAME CHART VERSION APP VERSION DESCRIPTION
|
||||
superset/superset 0.1.1 1.0 Apache Superset is a modern, enterprise-ready b...
|
||||
```
|
||||
|
||||
3. Configure your setting overrides
|
||||
|
||||
Just like any typical Helm chart, you'll need to craft a `values.yaml` file that would define/override any of the values exposed into the default [values.yaml](https://github.com/apache/superset/tree/master/helm/superset/values.yaml), or from any of the dependent charts it depends on:
|
||||
|
||||
- [bitnami/redis](https://artifacthub.io/packages/helm/bitnami/redis)
|
||||
- [bitnami/postgresql](https://artifacthub.io/packages/helm/bitnami/postgresql)
|
||||
|
||||
More info down below on some important overrides you might need.
|
||||
|
||||
4. Install and run
|
||||
|
||||
```sh
|
||||
helm upgrade --install --values my-values.yaml superset superset/superset
|
||||
```
|
||||
|
||||
You should see various pods popping up, such as:
|
||||
|
||||
```sh
|
||||
kubectl get pods
|
||||
NAME READY STATUS RESTARTS AGE
|
||||
superset-celerybeat-7cdcc9575f-k6xmc 1/1 Running 0 119s
|
||||
superset-f5c9c667-dw9lp 1/1 Running 0 4m7s
|
||||
superset-f5c9c667-fk8bk 1/1 Running 0 4m11s
|
||||
superset-init-db-zlm9z 0/1 Completed 0 111s
|
||||
superset-postgresql-0 1/1 Running 0 6d20h
|
||||
superset-redis-master-0 1/1 Running 0 6d20h
|
||||
superset-worker-75b48bbcc-jmmjr 1/1 Running 0 4m8s
|
||||
superset-worker-75b48bbcc-qrq49 1/1 Running 0 4m12s
|
||||
```
|
||||
|
||||
The exact list will depend on some of your specific configuration overrides but you should generally expect:
|
||||
|
||||
- N `superset-xxxx-yyyy` and `superset-worker-xxxx-yyyy` pods (depending on your `replicaCount` value)
|
||||
- 1 `superset-postgresql-0` depending on your postgres settings
|
||||
- 1 `superset-redis-master-0` depending on your redis settings
|
||||
- 1 `superset-celerybeat-xxxx-yyyy` pod if you have `supersetCeleryBeat.enabled = true` in your values overrides
|
||||
|
||||
1. Access it
|
||||
|
||||
The chart will publish appropriate services to expose the Superset UI internally within your k8s cluster. To access it externally you will have to either:
|
||||
|
||||
- Configure the Service as a `LoadBalancer` or `NodePort`
|
||||
- Set up an `Ingress` for it - the chart includes a definition, but will need to be tuned to your needs (hostname, tls, annotations etc...)
|
||||
- Run `kubectl port-forward superset-xxxx-yyyy :8088` to directly tunnel one pod's port into your localhost
|
||||
|
||||
Depending how you configured external access, the URL will vary. Once you've identified the appropriate URL you can log in with:
|
||||
|
||||
- user: `admin`
|
||||
- password: `admin`
|
||||
|
||||
### Important settings
|
||||
|
||||
#### Security settings
|
||||
|
||||
Default security settings and passwords are included but you **SHOULD** override those with your own, in particular:
|
||||
|
||||
```yaml
|
||||
postgresql:
|
||||
postgresqlPassword: superset
|
||||
```
|
||||
|
||||
#### Dependencies
|
||||
|
||||
Install additional packages and do any other bootstrap configuration in this script. For production clusters it's
|
||||
recommended to build own image with this step done in CI. The following example installs the Big Query and Elasticsearch
|
||||
database drivers so that you can connect to those datasources in your Superset installation.
|
||||
|
||||
```yaml
|
||||
bootstrapScript: |
|
||||
#!/bin/bash
|
||||
pip install psycopg2==2.8.5 \
|
||||
redis==3.2.1 \
|
||||
pybigquery==2.26.0 \
|
||||
elasticsearch-dbapi==0.2.5 &&\
|
||||
if [ ! -f ~/bootstrap ]; then echo "Running Superset with uid {{ .Values.runAsUser }}" > ~/bootstrap; fi
|
||||
```
|
||||
|
||||
#### superset_config.py
|
||||
|
||||
The default `superset_config.py` is fairly minimal and you will very likely need to extend it. This is done by specifying one or more key/value entries in `configOverrides`, e.g.:
|
||||
|
||||
```yaml
|
||||
configOverrides:
|
||||
my_override: |
|
||||
# This will make sure the redirect_uri is properly computed, even with SSL offloading
|
||||
ENABLE_PROXY_FIX = True
|
||||
FEATURE_FLAGS = {
|
||||
"DYNAMIC_PLUGINS": True
|
||||
}
|
||||
```
|
||||
|
||||
Those will be evaluated as Helm templates and therefore will be able to reference other `values.yaml` variables e.g. `{{ .Values.ingress.hosts[0] }}` will resolve to your ingress external domain.
|
||||
|
||||
The entire `superset_config.py` will be installed as a secret, so it is safe to pass sensitive parameters directly... however it might be more readable to use secret env variables for that.
|
||||
|
||||
Full python files can be provided by running `helm upgrade --install --values my-values.yaml --set-file configOverrides.oauth=set_oauth.py`
|
||||
|
||||
#### Environment Variables
|
||||
|
||||
Those can be passed as key/values either with `extraEnv` or `extraSecretEnv` if they're sensitive. They can then be referenced from `superset_config.py` using e.g. `os.environ.get("VAR")`.
|
||||
|
||||
```yaml
|
||||
extraEnv:
|
||||
SMTP_HOST: smtp.gmail.com
|
||||
SMTP_USER: user@gmail.com
|
||||
SMTP_PORT: "587"
|
||||
SMTP_MAIL_FROM: user@gmail.com
|
||||
|
||||
extraSecretEnv:
|
||||
SMTP_PASSWORD: xxxx
|
||||
|
||||
configOverrides:
|
||||
smtp: |
|
||||
import ast
|
||||
SMTP_HOST = os.getenv("SMTP_HOST","localhost")
|
||||
SMTP_STARTTLS = ast.literal_eval(os.getenv("SMTP_STARTTLS", "True"))
|
||||
SMTP_SSL = ast.literal_eval(os.getenv("SMTP_SSL", "False"))
|
||||
SMTP_USER = os.getenv("SMTP_USER","superset")
|
||||
SMTP_PORT = os.getenv("SMTP_PORT",25)
|
||||
SMTP_PASSWORD = os.getenv("SMTP_PASSWORD","superset")
|
||||
```
|
||||
|
||||
#### System packages
|
||||
|
||||
If new system packages are required, they can be installed before application startup by overriding the container's `command`, e.g.:
|
||||
|
||||
```yaml
|
||||
supersetWorker:
|
||||
command:
|
||||
- /bin/sh
|
||||
- -c
|
||||
- |
|
||||
apt update
|
||||
apt install -y somepackage
|
||||
apt autoremove -yqq --purge
|
||||
apt clean
|
||||
|
||||
# Run celery worker
|
||||
. {{ .Values.configMountPath }}/superset_bootstrap.sh; celery --app=superset.tasks.celery_app:app worker
|
||||
```
|
||||
|
||||
#### Data sources
|
||||
|
||||
Data source definitions can be automatically declared by providing key/value yaml definitions in `extraConfigs`:
|
||||
|
||||
```yaml
|
||||
extraConfigs:
|
||||
datasources-init.yaml: |
|
||||
databases:
|
||||
- allow_file_upload: true
|
||||
allow_ctas: true
|
||||
allow_cvas: true
|
||||
database_name: example-db
|
||||
extra: "{\r\n \"metadata_params\": {},\r\n \"engine_params\": {},\r\n \"\
|
||||
metadata_cache_timeout\": {},\r\n \"schemas_allowed_for_file_upload\": []\r\n\
|
||||
}"
|
||||
sqlalchemy_uri: example://example-db.local
|
||||
tables: []
|
||||
```
|
||||
|
||||
Those will also be mounted as secrets and can include sensitive parameters.
|
||||
|
||||
### Configuration Examples
|
||||
|
||||
#### Setting up OAuth
|
||||
|
||||
```yaml
|
||||
extraEnv:
|
||||
AUTH_DOMAIN: example.com
|
||||
|
||||
extraSecretEnv:
|
||||
GOOGLE_KEY: xxxxxxxxxxxx-xxxxxxxxxxxxxxxxxxxxxxxxxxxxxxxx.apps.googleusercontent.com
|
||||
GOOGLE_SECRET: xxxxxxxxxxxxxxxxxxxxxxxx
|
||||
|
||||
configOverrides:
|
||||
enable_oauth: |
|
||||
# This will make sure the redirect_uri is properly computed, even with SSL offloading
|
||||
ENABLE_PROXY_FIX = True
|
||||
|
||||
from flask_appbuilder.security.manager import (AUTH_OAUTH, AUTH_DB)
|
||||
AUTH_TYPE = AUTH_OAUTH
|
||||
OAUTH_PROVIDERS = [
|
||||
{
|
||||
"name": "google",
|
||||
"icon": "fa-google",
|
||||
"token_key": "access_token",
|
||||
"remote_app": {
|
||||
"client_id": os.getenv("GOOGLE_KEY"),
|
||||
"client_secret": os.getenv("GOOGLE_SECRET"),
|
||||
"api_base_url": "https://www.googleapis.com/oauth2/v2/",
|
||||
"client_kwargs": {"scope": "email profile"},
|
||||
"request_token_url": None,
|
||||
"access_token_url": "https://accounts.google.com/o/oauth2/token",
|
||||
"authorize_url": "https://accounts.google.com/o/oauth2/auth",
|
||||
"authorize_params": {"hd": os.getenv("AUTH_DOMAIN", "")}
|
||||
},
|
||||
}
|
||||
]
|
||||
|
||||
# Map Authlib roles to superset roles
|
||||
AUTH_ROLE_ADMIN = 'Admin'
|
||||
AUTH_ROLE_PUBLIC = 'Public'
|
||||
|
||||
# Will allow user self registration, allowing to create Flask users from Authorized User
|
||||
AUTH_USER_REGISTRATION = True
|
||||
|
||||
# The default user self registration role
|
||||
AUTH_USER_REGISTRATION_ROLE = "Admin"
|
||||
```
|
||||
|
||||
#### Enable Alerts and Reports
|
||||
|
||||
For this, as per the [Alerts and Reports doc](/docs/installation/email-reports), you will need to:
|
||||
|
||||
##### Install a supported webdriver in the Celery worker
|
||||
|
||||
This is done either by using a custom image that has the webdriver pre-installed, or installing at startup time by overriding the `command`. Here's a working example for `chromedriver`:
|
||||
|
||||
```yaml
|
||||
supersetWorker:
|
||||
command:
|
||||
- /bin/sh
|
||||
- -c
|
||||
- |
|
||||
# Install chrome webdriver
|
||||
# See https://github.com/apache/superset/blob/4fa3b6c7185629b87c27fc2c0e5435d458f7b73d/docs/src/pages/docs/installation/email_reports.mdx
|
||||
apt update
|
||||
wget https://dl.google.com/linux/direct/google-chrome-stable_current_amd64.deb
|
||||
apt install -y --no-install-recommends ./google-chrome-stable_current_amd64.deb
|
||||
wget https://chromedriver.storage.googleapis.com/88.0.4324.96/chromedriver_linux64.zip
|
||||
unzip chromedriver_linux64.zip
|
||||
chmod +x chromedriver
|
||||
mv chromedriver /usr/bin
|
||||
apt autoremove -yqq --purge
|
||||
apt clean
|
||||
rm -f google-chrome-stable_current_amd64.deb chromedriver_linux64.zip
|
||||
|
||||
# Run
|
||||
. {{ .Values.configMountPath }}/superset_bootstrap.sh; celery --app=superset.tasks.celery_app:app worker
|
||||
```
|
||||
|
||||
##### Run the Celery beat
|
||||
|
||||
This pod will trigger the scheduled tasks configured in the alerts and reports UI section:
|
||||
|
||||
```yaml
|
||||
supersetCeleryBeat:
|
||||
enabled: true
|
||||
```
|
||||
|
||||
##### Configure the appropriate Celery jobs and SMTP/Slack settings
|
||||
|
||||
```yaml
|
||||
extraEnv:
|
||||
SMTP_HOST: smtp.gmail.com
|
||||
SMTP_USER: user@gmail.com
|
||||
SMTP_PORT: "587"
|
||||
SMTP_MAIL_FROM: user@gmail.com
|
||||
|
||||
extraSecretEnv:
|
||||
SLACK_API_TOKEN: xoxb-xxxx-yyyy
|
||||
SMTP_PASSWORD: xxxx-yyyy
|
||||
|
||||
configOverrides:
|
||||
feature_flags: |
|
||||
import ast
|
||||
|
||||
FEATURE_FLAGS = {
|
||||
"ALERT_REPORTS": True
|
||||
}
|
||||
|
||||
SMTP_HOST = os.getenv("SMTP_HOST","localhost")
|
||||
SMTP_STARTTLS = ast.literal_eval(os.getenv("SMTP_STARTTLS", "True"))
|
||||
SMTP_SSL = ast.literal_eval(os.getenv("SMTP_SSL", "False"))
|
||||
SMTP_USER = os.getenv("SMTP_USER","superset")
|
||||
SMTP_PORT = os.getenv("SMTP_PORT",25)
|
||||
SMTP_PASSWORD = os.getenv("SMTP_PASSWORD","superset")
|
||||
SMTP_MAIL_FROM = os.getenv("SMTP_MAIL_FROM","superset@superset.com")
|
||||
|
||||
SLACK_API_TOKEN = os.getenv("SLACK_API_TOKEN",None)
|
||||
celery_conf: |
|
||||
from celery.schedules import crontab
|
||||
|
||||
class CeleryConfig(object):
|
||||
BROKER_URL = f"redis://{env('REDIS_HOST')}:{env('REDIS_PORT')}/0"
|
||||
CELERY_IMPORTS = ('superset.sql_lab', )
|
||||
CELERY_RESULT_BACKEND = f"redis://{env('REDIS_HOST')}:{env('REDIS_PORT')}/0"
|
||||
CELERY_ANNOTATIONS = {'tasks.add': {'rate_limit': '10/s'}}
|
||||
CELERY_IMPORTS = ('superset.sql_lab', "superset.tasks", "superset.tasks.thumbnails", )
|
||||
CELERY_ANNOTATIONS = {
|
||||
'sql_lab.get_sql_results': {
|
||||
'rate_limit': '100/s',
|
||||
},
|
||||
'email_reports.send': {
|
||||
'rate_limit': '1/s',
|
||||
'time_limit': 600,
|
||||
'soft_time_limit': 600,
|
||||
'ignore_result': True,
|
||||
},
|
||||
}
|
||||
CELERYBEAT_SCHEDULE = {
|
||||
'reports.scheduler': {
|
||||
'task': 'reports.scheduler',
|
||||
'schedule': crontab(minute='*', hour='*'),
|
||||
},
|
||||
'reports.prune_log': {
|
||||
'task': 'reports.prune_log',
|
||||
'schedule': crontab(minute=0, hour=0),
|
||||
},
|
||||
'cache-warmup-hourly': {
|
||||
'task': 'cache-warmup',
|
||||
'schedule': crontab(minute='*/30', hour='*'),
|
||||
'kwargs': {
|
||||
'strategy_name': 'top_n_dashboards',
|
||||
'top_n': 10,
|
||||
'since': '7 days ago',
|
||||
},
|
||||
}
|
||||
}
|
||||
|
||||
CELERY_CONFIG = CeleryConfig
|
||||
reports: |
|
||||
EMAIL_PAGE_RENDER_WAIT = 60
|
||||
WEBDRIVER_BASEURL = "http://{{ template "superset.fullname" . }}:{{ .Values.service.port }}/"
|
||||
WEBDRIVER_BASEURL_USER_FRIENDLY = "https://www.example.com/"
|
||||
WEBDRIVER_TYPE= "chrome"
|
||||
WEBDRIVER_OPTION_ARGS = [
|
||||
"--force-device-scale-factor=2.0",
|
||||
"--high-dpi-support=2.0",
|
||||
"--headless",
|
||||
"--disable-gpu",
|
||||
"--disable-dev-shm-usage",
|
||||
# This is required because our process runs as root (in order to install pip packages)
|
||||
"--no-sandbox",
|
||||
"--disable-setuid-sandbox",
|
||||
"--disable-extensions",
|
||||
]
|
||||
```
|
||||
|
|
@ -0,0 +1,273 @@
|
|||
---
|
||||
title: SQL Templating
|
||||
hide_title: true
|
||||
sidebar_position: 10
|
||||
version: 1
|
||||
---
|
||||
|
||||
## SQL Templating
|
||||
|
||||
### Jinja Templates
|
||||
|
||||
SQL Lab and Explore supports [Jinja templating](https://jinja.palletsprojects.com/en/2.11.x/) in queries.
|
||||
To enable templating, the `ENABLE_TEMPLATE_PROCESSING` feature flag needs to be enabled in
|
||||
`superset_config.py`. When templating is enabled, python code can be embedded in virtual datasets and
|
||||
in Custom SQL in the filter and metric controls in Explore. By default, the following variables are
|
||||
made available in the Jinja context:
|
||||
|
||||
- `columns`: columns which to group by in the query
|
||||
- `filter`: filters applied in the query
|
||||
- `from_dttm`: start `datetime` value from the selected time range (`None` if undefined)
|
||||
- `to_dttm`: end `datetime` value from the selected time range (`None` if undefined)
|
||||
- `groupby`: columns which to group by in the query (deprecated)
|
||||
- `metrics`: aggregate expressions in the query
|
||||
- `row_limit`: row limit of the query
|
||||
- `row_offset`: row offset of the query
|
||||
- `table_columns`: columns available in the dataset
|
||||
- `time_column`: temporal column of the query (`None` if undefined)
|
||||
- `time_grain`: selected time grain (`None` if undefined)
|
||||
|
||||
For example, to add a time range to a virtual dataset, you can write the following:
|
||||
|
||||
```sql
|
||||
SELECT * from tbl where dttm_col > '{{ from_dttm }}' and dttm_col < '{{ to_dttm }}'
|
||||
```
|
||||
|
||||
To add custom functionality to the Jinja context, you need to to to overload the default Jinja
|
||||
context in your environment by defining the `JINJA_CONTEXT_ADDONS` in your superset configuration
|
||||
(`superset_config.py`). Objects referenced in this dictionary are made available for users to use
|
||||
where the Jinja context is made available.
|
||||
|
||||
```python
|
||||
JINJA_CONTEXT_ADDONS = {
|
||||
'my_crazy_macro': lambda x: x*2,
|
||||
}
|
||||
```
|
||||
|
||||
Besides default Jinja templating, SQL lab also supports self-defined template processor by setting
|
||||
the `CUSTOM_TEMPLATE_PROCESSORS` in your superset configuration. The values in this dictionary
|
||||
overwrite the default Jinja template processors of the specified database engine. The example below
|
||||
configures a custom presto template processor which implements its own logic of processing macro
|
||||
template with regex parsing. It uses the `$` style macro instead of `{{ }}` style in Jinja
|
||||
templating.
|
||||
|
||||
By configuring it with `CUSTOM_TEMPLATE_PROCESSORS`, a SQL template on a presto database is
|
||||
processed by the custom one rather than the default one.
|
||||
|
||||
```python
|
||||
def DATE(
|
||||
ts: datetime, day_offset: SupportsInt = 0, hour_offset: SupportsInt = 0
|
||||
) -> str:
|
||||
"""Current day as a string."""
|
||||
day_offset, hour_offset = int(day_offset), int(hour_offset)
|
||||
offset_day = (ts + timedelta(days=day_offset, hours=hour_offset)).date()
|
||||
return str(offset_day)
|
||||
|
||||
class CustomPrestoTemplateProcessor(PrestoTemplateProcessor):
|
||||
"""A custom presto template processor."""
|
||||
|
||||
engine = "presto"
|
||||
|
||||
def process_template(self, sql: str, **kwargs) -> str:
|
||||
"""Processes a sql template with $ style macro using regex."""
|
||||
# Add custom macros functions.
|
||||
macros = {
|
||||
"DATE": partial(DATE, datetime.utcnow())
|
||||
} # type: Dict[str, Any]
|
||||
# Update with macros defined in context and kwargs.
|
||||
macros.update(self.context)
|
||||
macros.update(kwargs)
|
||||
|
||||
def replacer(match):
|
||||
"""Expand $ style macros with corresponding function calls."""
|
||||
macro_name, args_str = match.groups()
|
||||
args = [a.strip() for a in args_str.split(",")]
|
||||
if args == [""]:
|
||||
args = []
|
||||
f = macros[macro_name[1:]]
|
||||
return f(*args)
|
||||
|
||||
macro_names = ["$" + name for name in macros.keys()]
|
||||
pattern = r"(%s)\s*\(([^()]*)\)" % "|".join(map(re.escape, macro_names))
|
||||
return re.sub(pattern, replacer, sql)
|
||||
|
||||
CUSTOM_TEMPLATE_PROCESSORS = {
|
||||
CustomPrestoTemplateProcessor.engine: CustomPrestoTemplateProcessor
|
||||
}
|
||||
```
|
||||
|
||||
SQL Lab also includes a live query validation feature with pluggable backends. You can configure
|
||||
which validation implementation is used with which database engine by adding a block like the
|
||||
following to your configuration file:
|
||||
|
||||
```python
|
||||
FEATURE_FLAGS = {
|
||||
'SQL_VALIDATORS_BY_ENGINE': {
|
||||
'presto': 'PrestoDBSQLValidator',
|
||||
}
|
||||
}
|
||||
```
|
||||
|
||||
The available validators and names can be found in
|
||||
[sql_validators](https://github.com/apache/superset/tree/master/superset/sql_validators).
|
||||
|
||||
### Available Macros
|
||||
|
||||
In this section, we'll walkthrough the pre-defined Jinja macros in Superset.
|
||||
|
||||
**Current Username**
|
||||
|
||||
The `{{ current_username() }}` macro returns the username of the currently logged in user.
|
||||
|
||||
If you have caching enabled in your Superset configuration, then by defaul the the `username` value will be used
|
||||
by Superset when calculating the cache key. A cache key is a unique identifer that determines if there's a
|
||||
cache hit in the future and Superset can retrieve cached data.
|
||||
|
||||
You can disable the inclusion of the `username` value in the calculation of the
|
||||
cache key by adding the following parameter to your Jinja code:
|
||||
|
||||
```
|
||||
{{ current_username(add_to_cache_keys=False) }}
|
||||
```
|
||||
|
||||
**Current User ID**
|
||||
|
||||
The `{{ current_user_id()}}` macro returns the user_id of the currently logged in user.
|
||||
|
||||
If you have caching enabled in your Superset configuration, then by defaul the the `user_id` value will be used
|
||||
by Superset when calculating the cache key. A cache key is a unique identifer that determines if there's a
|
||||
cache hit in the future and Superset can retrieve cached data.
|
||||
|
||||
You can disable the inclusion of the `user_id` value in the calculation of the
|
||||
cache key by adding the following parameter to your Jinja code:
|
||||
|
||||
```
|
||||
{{ current_user_id(add_to_cache_keys=False) }}
|
||||
```
|
||||
|
||||
**Custom URL Parameters**
|
||||
|
||||
The `{{ url_param('custom_variable') }}` macro lets you define arbitrary URL
|
||||
parameters and reference them in your SQL code.
|
||||
|
||||
Here's a concrete example:
|
||||
|
||||
- You write the following query in SQL Lab:
|
||||
|
||||
```
|
||||
SELECT count(*)
|
||||
FROM ORDERS
|
||||
WHERE country_code = '{{ url_param('countrycode') }}'
|
||||
```
|
||||
|
||||
- You're hosting Superset at the domain www.example.com and you send your
|
||||
coworker in Spain the following SQL Lab URL `www.example.com/superset/sqllab?countrycode=ES`
|
||||
and your coworker in the USA the following SQL Lab URL `www.example.com/superset/sqllab?countrycode=US`
|
||||
- For your coworker in Spain, the SQL Lab query will be rendered as:
|
||||
|
||||
```
|
||||
SELECT count(*)
|
||||
FROM ORDERS
|
||||
WHERE country_code = 'ES'
|
||||
```
|
||||
|
||||
- For your coworker in the USA, the SQL Lab query will be rendered as:
|
||||
|
||||
```
|
||||
SELECT count(*)
|
||||
FROM ORDERS
|
||||
WHERE country_code = 'US'
|
||||
```
|
||||
|
||||
**Explicitly Including Values in Cache Key**
|
||||
|
||||
The `{{ cache_key_wrapper() }}` function explicitly instructs Superset to add a value to the
|
||||
accumulated list of values used in the the calculation of the cache key.
|
||||
|
||||
This function is only needed when you want to wrap your own custom function return values
|
||||
in the cache key. You can gain more context
|
||||
[here](https://github.com/apache/superset/blob/efd70077014cbed62e493372d33a2af5237eaadf/superset/jinja_context.py#L133-L148).
|
||||
|
||||
Note that this function powers the caching of the `user_id` and `username` values
|
||||
in the `current_user_id()` and `current_username()` function calls (if you have caching enabled).
|
||||
|
||||
**Filter Values**
|
||||
|
||||
You can retrieve the value for a specific filter as a list using `{{ filter_values() }}`.
|
||||
|
||||
This is useful if:
|
||||
|
||||
- you want to use a filter component to filter a query where the name of filter component column doesn't match the one in the select statement
|
||||
- you want to have the ability for filter inside the main query for performance purposes
|
||||
|
||||
Here's a concrete example:
|
||||
|
||||
```
|
||||
SELECT action, count(*) as times
|
||||
FROM logs
|
||||
WHERE
|
||||
action in ({{ "'" + "','".join(filter_values('action_type')) + "'" }})
|
||||
GROUP BY action
|
||||
```
|
||||
|
||||
**Filters for a Specific Column**
|
||||
|
||||
The `{{ get_filters() }}` macro returns the filters applied to a given column. In addition to
|
||||
returning the values (similar to how `filter_values()` does), the `get_filters()` macro
|
||||
returns the operator specified in the Explore UI.
|
||||
|
||||
This is useful if:
|
||||
|
||||
- you want to handle more than the IN operator in your SQL clause
|
||||
- you want to handle generating custom SQL conditions for a filter
|
||||
- you want to have the ability to filter inside the main query for speed purposes
|
||||
|
||||
Here's a concrete example:
|
||||
|
||||
```
|
||||
WITH RECURSIVE
|
||||
superiors(employee_id, manager_id, full_name, level, lineage) AS (
|
||||
SELECT
|
||||
employee_id,
|
||||
manager_id,
|
||||
full_name,
|
||||
1 as level,
|
||||
employee_id as lineage
|
||||
FROM
|
||||
employees
|
||||
WHERE
|
||||
1=1
|
||||
|
||||
{# Render a blank line #}
|
||||
{%- for filter in get_filters('full_name', remove_filter=True) -%}
|
||||
|
||||
{%- if filter.get('op') == 'IN' -%}
|
||||
AND
|
||||
full_name IN ( {{ "'" + "', '".join(filter.get('val')) + "'" }} )
|
||||
{%- endif -%}
|
||||
|
||||
{%- if filter.get('op') == 'LIKE' -%}
|
||||
AND
|
||||
full_name LIKE {{ "'" + filter.get('val') + "'" }}
|
||||
{%- endif -%}
|
||||
|
||||
{%- endfor -%}
|
||||
UNION ALL
|
||||
SELECT
|
||||
e.employee_id,
|
||||
e.manager_id,
|
||||
e.full_name,
|
||||
s.level + 1 as level,
|
||||
s.lineage
|
||||
FROM
|
||||
employees e,
|
||||
superiors s
|
||||
WHERE s.manager_id = e.employee_id
|
||||
)
|
||||
|
||||
SELECT
|
||||
employee_id, manager_id, full_name, level, lineage
|
||||
FROM
|
||||
superiors
|
||||
order by lineage, level
|
||||
```
|
||||
|
|
@ -0,0 +1,43 @@
|
|||
---
|
||||
title: Upgrading Superset
|
||||
hide_title: true
|
||||
sidebar_position: 7
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Upgrading Superset
|
||||
|
||||
### Docker Compose
|
||||
|
||||
First make sure to wind down the running containers in Docker Compose:
|
||||
|
||||
```bash
|
||||
docker-compose down
|
||||
```
|
||||
|
||||
Then, update the folder that mirrors the `superset` repo through git:
|
||||
|
||||
```bash
|
||||
cd superset/
|
||||
git pull origin master
|
||||
```
|
||||
|
||||
Then, restart the containers and any changed Docker images will be automatically pulled down:
|
||||
|
||||
```bash
|
||||
docker-compose up
|
||||
```
|
||||
|
||||
### Updating Superset Manually
|
||||
|
||||
To upgrade superset in a native installation, run the following commands:
|
||||
|
||||
```bash
|
||||
pip install apache-superset --upgrade
|
||||
superset db upgrade
|
||||
superset init
|
||||
```
|
||||
|
||||
While upgrading superset should not delete your charts and dashboards, we recommend following best
|
||||
practices and to backup your metadata database before upgrading. Before upgrading production, we
|
||||
recommend upgrading in a staging environment and upgrading production finally during off-peak usage.
|
||||
|
|
@ -0,0 +1,60 @@
|
|||
---
|
||||
title: Introduction
|
||||
hide_title: true
|
||||
sidebar_position: 1
|
||||
---
|
||||
|
||||
## What is Apache Superset?
|
||||
|
||||
Apache Superset is a modern, enterprise-ready business intelligence web application. It
|
||||
is fast, lightweight, intuitive, and loaded with options that make it easy for users of all skill
|
||||
sets to explore and visualize their data, from simple pie charts to highly detailed deck.gl
|
||||
geospatial charts.
|
||||
|
||||
Here are a **few different ways you can get started with Superset**:
|
||||
|
||||
- Download the [source from Apache Foundation's website](https://dist.apache.org/repos/dist/release/superset/1.0.0/)
|
||||
- Download the latest Superset version from [Pypi here](https://pypi.org/project/apache-superset/)
|
||||
- Setup Superset locally with one command
|
||||
using [Docker Compose](installation/installing-superset-using-docker-compose)
|
||||
- Download the [Docker image](https://hub.docker.com/r/apache/superset) from Dockerhub
|
||||
- Install the latest version of Superset
|
||||
[from Github](https://github.com/apache/superset/tree/latest)
|
||||
|
||||
Superset provides:
|
||||
|
||||
- An intuitive interface for visualizing datasets and crafting interactive dashboards
|
||||
- A wide array of beautiful visualizations to showcase your data
|
||||
- Code-free visualization builder to extract and present datasets
|
||||
- A world-class SQL IDE for preparing data for visualization, including a rich metadata browser
|
||||
- A lightweight semantic layer which empowers data analysts to quickly define custom dimensions and metrics
|
||||
- Out-of-the-box support for most SQL-speaking databases
|
||||
- Seamless, in-memory asynchronous caching and queries
|
||||
- An extensible security model that allows configuration of very intricate rules on on who can access which product features and datasets.
|
||||
- Integration with major authentication backends (database, OpenID, LDAP, OAuth, REMOTE_USER, etc)
|
||||
- The ability to add custom visualization plugins
|
||||
- An API for programmatic customization
|
||||
- A cloud-native architecture designed from the ground up for scale
|
||||
|
||||
Superset is cloud-native and designed to be highly available. It was designed to scale out to large,
|
||||
distributed environments and works very well inside containers. While you can easily test drive
|
||||
Superset on a modest setup or simply on your laptop, there’s virtually no limit around scaling out
|
||||
the platform.
|
||||
|
||||
Superset is also cloud-native in the sense that it is flexible and lets you choose the:
|
||||
|
||||
- web server (Gunicorn, Nginx, Apache),
|
||||
- metadata database engine (MySQL, Postgres, MariaDB, etc),
|
||||
- message queue (Redis, RabbitMQ, SQS, etc),
|
||||
- results backend (S3, Redis, Memcached, etc),
|
||||
- caching layer (Memcached, Redis, etc),
|
||||
|
||||
Superset also works well with services like NewRelic, StatsD and DataDog, and has the ability to run
|
||||
analytic workloads against most popular database technologies.
|
||||
|
||||
Superset is currently run at scale at many companies. For example, Superset is run in Airbnb’s
|
||||
production environment inside Kubernetes and serves 600+ daily active users viewing over 100K charts
|
||||
a day.
|
||||
|
||||
You can find a partial list of industries and companies embracing Superset
|
||||
[on this page in GitHub](https://github.com/apache/superset/blob/master/RESOURCES/INTHEWILD.md).
|
||||
|
|
@ -0,0 +1,4 @@
|
|||
{
|
||||
"label": "Miscellaneous",
|
||||
"position": 5
|
||||
}
|
||||
|
|
@ -0,0 +1,147 @@
|
|||
---
|
||||
title: Chart Parameters Reference
|
||||
hide_title: true
|
||||
sidebar_position: 4
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Chart Parameters
|
||||
|
||||
Chart parameters are stored as a JSON encoded string the `slices.params` column and are often referenced throughout the code as form-data. Currently the form-data is neither versioned nor typed as thus is somewhat free-formed. Note in the future there may be merit in using something like [JSON Schema](https://json-schema.org/) to both annotate and validate the JSON object in addition to using a Mypy `TypedDict` (introduced in Python 3.8) for typing the form-data in the backend. This section serves as a potential primer for that work.
|
||||
|
||||
The following tables provide a non-exhausive list of the various fields which can be present in the JSON object grouped by the Explorer pane sections. These values were obtained by extracting the distinct fields from a legacy deployment consisting of tens of thousands of charts and thus some fields may be missing whilst others may be deprecated.
|
||||
|
||||
Note not all fields are correctly categorized. The fields vary based on visualization type and may appear in different sections depending on the type. Verified deprecated columns may indicate a missing migration and/or prior migrations which were unsuccessful and thus future work may be required to clean up the form-data.
|
||||
|
||||
### Datasource & Chart Type
|
||||
|
||||
| Field | Type | Notes |
|
||||
| ----------------- | -------- | ----------------------------------- |
|
||||
| `database_name` | _string_ | _Deprecated?_ |
|
||||
| `datasource` | _string_ | `<datasouce_id>__<datasource_type>` |
|
||||
| `datasource_id` | _string_ | _Deprecated?_ See `datasource` |
|
||||
| `datasource_name` | _string_ | _Deprecated?_ |
|
||||
| `datasource_type` | _string_ | _Deprecated?_ See `datasource` |
|
||||
| `viz_type` | _string_ | The **Visualization Type** widget |
|
||||
|
||||
### Time
|
||||
|
||||
| Field | Type | Notes |
|
||||
| ------------------- | -------- | ------------------------------------- |
|
||||
| `druid_time_origin` | _string_ | The Druid **Origin** widget |
|
||||
| `granularity` | _string_ | The Druid **Time Granularity** widget |
|
||||
| `granularity_sqla` | _string_ | The SQLA **Time Column** widget |
|
||||
| `time_grain_sqla` | _string_ | The SQLA **Time Grain** widget |
|
||||
| `time_range` | _string_ | The **Time range** widget |
|
||||
|
||||
### GROUP BY
|
||||
|
||||
| Field | Type | Notes |
|
||||
| ------------------------- | --------------- | ----------------- |
|
||||
| `metrics` | _array(string)_ | See Query section |
|
||||
| `order_asc` | - | See Query section |
|
||||
| `row_limit` | - | See Query section |
|
||||
| `timeseries_limit_metric` | - | See Query section |
|
||||
|
||||
### NOT GROUPED BY
|
||||
|
||||
| Field | Type | Notes |
|
||||
| --------------- | --------------- | ----------------------- |
|
||||
| `order_by_cols` | _array(string)_ | The **Ordering** widget |
|
||||
| `row_limit` | - | See Query section |
|
||||
|
||||
### Y Axis 1
|
||||
|
||||
| Field | Type | Notes |
|
||||
| --------------- | ---- | -------------------------------------------------- |
|
||||
| `metric` | - | The **Left Axis Metric** widget. See Query section |
|
||||
| `y_axis_format` | - | See Y Axis section |
|
||||
|
||||
### Y Axis 2
|
||||
|
||||
| Field | Type | Notes |
|
||||
| ---------- | ---- | --------------------------------------------------- |
|
||||
| `metric_2` | - | The **Right Axis Metric** widget. See Query section |
|
||||
|
||||
### Query
|
||||
|
||||
| Field | Type | Notes |
|
||||
| ------------------------------------------------------------------------------------------------------ | ------------------------------------------------- | ------------------------------------------------- |
|
||||
| `adhoc_filters` | _array(object)_ | The **Filters** widget |
|
||||
| `extra_filters` | _array(object)_ | Another pathway to the **Filters** widget.<br/>It is generally used to pass dashboard filter parameters to a chart.<br/>It can be used for appending additional filters to a chart that has been saved with its own filters on an ad-hoc basis if the chart is being used as a standalone widget.<br/><br/>For implementation examples see : [utils test.py](https://github.com/apache/superset/blob/66a4c94a1ed542e69fe6399bab4c01d4540486cf/tests/utils_tests.py#L181)<br/>For insight into how superset processes the contents of this parameter see: [exploreUtils/index.js](https://github.com/apache/superset/blob/93c7f5bb446ec6895d7702835f3157426955d5a9/superset-frontend/src/explore/exploreUtils/index.js#L159) |
|
||||
| `columns` | _array(string)_ | The **Breakdowns** widget |
|
||||
| `groupby` | _array(string)_ | The **Group by** or **Series** widget |
|
||||
| `limit` | _number_ | The **Series Limit** widget |
|
||||
| `metric`<br/>`metric_2`<br/>`metrics`<br/>`percent_mertics`<br/>`secondary_metric`<br/>`size`<br/>`x`<br/>`y` | _string_,_object_,_array(string)_,_array(object)_ | The metric(s) depending on the visualization type |
|
||||
| `order_asc` | _boolean_ | The **Sort Descending** widget |
|
||||
| `row_limit` | _number_ | The **Row limit** widget |
|
||||
| `timeseries_limit_metric` | _object_ | The **Sort By** widget |
|
||||
|
||||
The `metric` (or equivalent) and `timeseries_limit_metric` fields are all composed of either metric names or the JSON representation of the `AdhocMetric` TypeScript type. The `adhoc_filters` is composed of the JSON represent of the `AdhocFilter` TypeScript type (which can comprise of columns or metrics depending on whether it is a WHERE or HAVING clause). The `all_columns`, `all_columns_x`, `columns`, `groupby`, and `order_by_cols` fields all represent column names.
|
||||
|
||||
### Chart Options
|
||||
|
||||
| Field | Type | Notes |
|
||||
| -------------- | --------- | --------------------------- |
|
||||
| `color_picker` | _object_ | The **Fixed Color** widget |
|
||||
| `label_colors` | _object_ | The **Color Scheme** widget |
|
||||
| `normalized` | _boolean_ | The **Normalized** widget |
|
||||
|
||||
### Y Axis
|
||||
|
||||
| Field | Type | Notes |
|
||||
| ---------------- | -------- | ---------------------------- |
|
||||
| `y_axis_2_label` | _N/A_ | _Deprecated?_ |
|
||||
| `y_axis_format` | _string_ | The **Y Axis Format** widget |
|
||||
| `y_axis_zero` | _N/A_ | _Deprecated?_ |
|
||||
|
||||
Note the `y_axis_format` is defined under various section for some charts.
|
||||
|
||||
### Other
|
||||
|
||||
| Field | Type | Notes |
|
||||
| -------------- | -------- | ----- |
|
||||
| `color_scheme` | _string_ | |
|
||||
|
||||
### Unclassified
|
||||
|
||||
| Field | Type | Notes |
|
||||
| ----------------------------- | ----- | ----- |
|
||||
| `add_to_dash` | _N/A_ | |
|
||||
| `code` | _N/A_ | |
|
||||
| `collapsed_fieldsets` | _N/A_ | |
|
||||
| `comparison type` | _N/A_ | |
|
||||
| `country_fieldtype` | _N/A_ | |
|
||||
| `default_filters` | _N/A_ | |
|
||||
| `entity` | _N/A_ | |
|
||||
| `expanded_slices` | _N/A_ | |
|
||||
| `filter_immune_slice_fields` | _N/A_ | |
|
||||
| `filter_immune_slices` | _N/A_ | |
|
||||
| `flt_col_0` | _N/A_ | |
|
||||
| `flt_col_1` | _N/A_ | |
|
||||
| `flt_eq_0` | _N/A_ | |
|
||||
| `flt_eq_1` | _N/A_ | |
|
||||
| `flt_op_0` | _N/A_ | |
|
||||
| `flt_op_1` | _N/A_ | |
|
||||
| `goto_dash` | _N/A_ | |
|
||||
| `import_time` | _N/A_ | |
|
||||
| `label` | _N/A_ | |
|
||||
| `linear_color_scheme` | _N/A_ | |
|
||||
| `new_dashboard_name` | _N/A_ | |
|
||||
| `new_slice_name` | _N/A_ | |
|
||||
| `num_period_compare` | _N/A_ | |
|
||||
| `period_ratio_type` | _N/A_ | |
|
||||
| `perm` | _N/A_ | |
|
||||
| `rdo_save` | _N/A_ | |
|
||||
| `refresh_frequency` | _N/A_ | |
|
||||
| `remote_id` | _N/A_ | |
|
||||
| `resample_fillmethod` | _N/A_ | |
|
||||
| `resample_how` | _N/A_ | |
|
||||
| `rose_area_proportion` | _N/A_ | |
|
||||
| `save_to_dashboard_id` | _N/A_ | |
|
||||
| `schema` | _N/A_ | |
|
||||
| `series` | _N/A_ | |
|
||||
| `show_bubbles` | _N/A_ | |
|
||||
| `slice_name` | _N/A_ | |
|
||||
| `timed_refresh_immune_slices` | _N/A_ | |
|
||||
| `userid` | _N/A_ | |
|
||||
|
|
@ -0,0 +1,61 @@
|
|||
---
|
||||
title: Country Map Tools
|
||||
hide_title: true
|
||||
sidebar_position: 1
|
||||
version: 1
|
||||
---
|
||||
|
||||
## The Country Map Visualization
|
||||
|
||||
The Country Map visualization allows you to plot lightweight choropleth maps of
|
||||
your countries by province, states, or other subdivision types. It does not rely
|
||||
on any third-party map services but would require you to provide the
|
||||
[ISO-3166-2](https://en.wikipedia.org/wiki/ISO_3166-2) codes of your country's
|
||||
top-level subdivisions. Comparing to a province or state's full names, the ISO
|
||||
code is less ambiguous and is unique to all regions in the world.
|
||||
|
||||
## Included Maps
|
||||
|
||||
The Country Maps visualization already ships with the maps for the following countries:
|
||||
|
||||
- Belgium
|
||||
- Brazil
|
||||
- Bulgaria
|
||||
- Canada
|
||||
- China
|
||||
- Egypt
|
||||
- France
|
||||
- Germany
|
||||
- India
|
||||
- Iran
|
||||
- Italy
|
||||
- Japan
|
||||
- Korea
|
||||
- Liechtenstein
|
||||
- Morocco
|
||||
- Myanmar
|
||||
- Netherlands
|
||||
- Portugal
|
||||
- Russia
|
||||
- Singapore
|
||||
- Spain
|
||||
- Switzerland
|
||||
- Syria
|
||||
- Thailand
|
||||
- Timorleste
|
||||
- UK
|
||||
- Ukraine
|
||||
- Uruguay
|
||||
- USA
|
||||
- Zambia
|
||||
|
||||
## Adding a New Country
|
||||
|
||||
To add a new country to the list, you'd have to edit files in
|
||||
[@superset-ui/legacy-plugin-chart-country-map](https://github.com/apache-superset/superset-ui/tree/master/plugins/legacy-plugin-chart-country-map).
|
||||
|
||||
1. Generate a new GeoJSON file for your country following the guide in [this Jupyter notebook](https://github.com/apache-superset/superset-ui/blob/master/plugins/legacy-plugin-chart-country-map/scripts/Country%20Map%20GeoJSON%20Generator.ipynb).
|
||||
2. Edit the countries list in [legacy-plugin-chart-country-map/src/countries.js](https://github.com/apache-superset/superset-ui/blob/master/plugins/legacy-plugin-chart-country-map/src/countries.js).
|
||||
3. Ping one of the Superset committers to get the `@superset-ui/legacy-plugin-chart-country-map` package published, or
|
||||
publish it under another name yourself.
|
||||
4. Update npm dependencies in `superset-frontend/package.json` to install the updated plugin package.
|
||||
|
|
@ -0,0 +1,116 @@
|
|||
---
|
||||
title: Importing and Exporting Datasources
|
||||
hide_title: true
|
||||
sidebar_position: 2
|
||||
version: 1
|
||||
---
|
||||
|
||||
## Importing and Exporting Datasources
|
||||
|
||||
The superset cli allows you to import and export datasources from and to YAML. Datasources include
|
||||
both databases and druid clusters. The data is expected to be organized in the following hierarchy:
|
||||
|
||||
```
|
||||
├──databases
|
||||
| ├──database_1
|
||||
| | ├──table_1
|
||||
| | | ├──columns
|
||||
| | | | ├──column_1
|
||||
| | | | ├──column_2
|
||||
| | | | └──... (more columns)
|
||||
| | | └──metrics
|
||||
| | | ├──metric_1
|
||||
| | | ├──metric_2
|
||||
| | | └──... (more metrics)
|
||||
| | └── ... (more tables)
|
||||
| └── ... (more databases)
|
||||
└──druid_clusters
|
||||
├──cluster_1
|
||||
| ├──datasource_1
|
||||
| | ├──columns
|
||||
| | | ├──column_1
|
||||
| | | ├──column_2
|
||||
| | | └──... (more columns)
|
||||
| | └──metrics
|
||||
| | ├──metric_1
|
||||
| | ├──metric_2
|
||||
| | └──... (more metrics)
|
||||
| └── ... (more datasources)
|
||||
└── ... (more clusters)
|
||||
```
|
||||
|
||||
### Exporting Datasources to YAML
|
||||
|
||||
You can print your current datasources to stdout by running:
|
||||
|
||||
```
|
||||
superset export_datasources
|
||||
```
|
||||
|
||||
To save your datasources to a file run:
|
||||
|
||||
```
|
||||
superset export_datasources -f <filename>
|
||||
```
|
||||
|
||||
By default, default (null) values will be omitted. Use the -d flag to include them. If you want back
|
||||
references to be included (e.g. a column to include the table id it belongs to) use the -b flag.
|
||||
|
||||
Alternatively, you can export datasources using the UI:
|
||||
|
||||
1. Open **Sources -> Databases** to export all tables associated to a single or multiple databases.
|
||||
(**Tables** for one or more tables, **Druid Clusters** for clusters, **Druid Datasources** for
|
||||
datasources)
|
||||
2. Select the items you would like to export.
|
||||
3. Click **Actions -> Export** to YAML
|
||||
4. If you want to import an item that you exported through the UI, you will need to nest it inside
|
||||
its parent element, e.g. a database needs to be nested under databases a table needs to be nested
|
||||
inside a database element.
|
||||
|
||||
In order to obtain an **exhaustive list of all fields** you can import using the YAML import run:
|
||||
|
||||
```
|
||||
superset export_datasource_schema
|
||||
```
|
||||
|
||||
As a reminder, you can use the `-b` flag to include back references.
|
||||
|
||||
### Importing Datasources from YAML
|
||||
|
||||
In order to import datasources from a YAML file(s), run:
|
||||
|
||||
```
|
||||
superset import_datasources -p <path or filename>
|
||||
```
|
||||
|
||||
If you supply a path all files ending with **yaml** or **yml** will be parsed. You can apply
|
||||
additional flags (e.g. to search the supplied path recursively):
|
||||
|
||||
```
|
||||
superset import_datasources -p <path> -r
|
||||
```
|
||||
|
||||
The sync flag **-s** takes parameters in order to sync the supplied elements with your file. Be
|
||||
careful this can delete the contents of your meta database. Example:
|
||||
|
||||
```
|
||||
superset import_datasources -p <path / filename> -s columns,metrics
|
||||
```
|
||||
|
||||
This will sync all metrics and columns for all datasources found in the `<path /filename>` in the
|
||||
Superset meta database. This means columns and metrics not specified in YAML will be deleted. If you
|
||||
would add tables to columns,metrics those would be synchronised as well.
|
||||
|
||||
If you don’t supply the sync flag (**-s**) importing will only add and update (override) fields.
|
||||
E.g. you can add a verbose_name to the column ds in the table random_time_series from the example
|
||||
datasets by saving the following YAML to file and then running the **import_datasources** command.
|
||||
|
||||
```
|
||||
databases:
|
||||
- database_name: main
|
||||
tables:
|
||||
- table_name: random_time_series
|
||||
columns:
|
||||
- column_name: ds
|
||||
verbose_name: datetime
|
||||
```
|
||||
|
|
@ -0,0 +1,334 @@
|
|||
---
|
||||
title: Issue Codes
|
||||
sidebar_position: 3
|
||||
version: 1
|
||||
---
|
||||
|
||||
# Issue Code Reference
|
||||
|
||||
This page lists issue codes that may be displayed in
|
||||
Superset and provides additional context.
|
||||
|
||||
## Issue 1000
|
||||
|
||||
```
|
||||
The datasource is too large to query.
|
||||
```
|
||||
|
||||
It's likely your datasource has grown too large to run the current
|
||||
query, and is timing out. You can resolve this by reducing the
|
||||
size of your datasource or by modifying your query to only process a
|
||||
subset of your data.
|
||||
|
||||
## Issue 1001
|
||||
|
||||
```
|
||||
The database is under an unusual load.
|
||||
```
|
||||
|
||||
Your query may have timed out because of unusually high load on the
|
||||
database engine. You can make your query simpler, or wait until the
|
||||
database is under less load and try again.
|
||||
|
||||
## Issue 1002
|
||||
|
||||
```
|
||||
The database returned an unexpected error.
|
||||
```
|
||||
|
||||
Your query failed because of an error that occurred on the database.
|
||||
This may be due to a syntax error, a bug in your query, or some other
|
||||
internal failure within the database. This is usually not an
|
||||
issue within Superset, but instead a problem with the underlying
|
||||
database that serves your query.
|
||||
|
||||
## Issue 1003
|
||||
|
||||
```
|
||||
There is a syntax error in the SQL query. Perhaps there was a misspelling or a typo.
|
||||
```
|
||||
|
||||
Your query failed because of a syntax error within the underlying query. Please
|
||||
validate that all columns or tables referenced within the query exist and are spelled
|
||||
correctly.
|
||||
|
||||
## Issue 1004
|
||||
|
||||
```
|
||||
The column was deleted or renamed in the database.
|
||||
```
|
||||
|
||||
Your query failed because it is referencing a column that no longer exists in
|
||||
the underlying datasource. You should modify the query to reference the
|
||||
replacement column, or remove this column from your query.
|
||||
|
||||
## Issue 1005
|
||||
|
||||
```
|
||||
The table was deleted or renamed in the database.
|
||||
```
|
||||
|
||||
Your query failed because it is referencing a table that no longer exists in
|
||||
the underlying database. You should modify your query to reference the correct
|
||||
table.
|
||||
|
||||
## Issue 1006
|
||||
|
||||
```
|
||||
One or more parameters specified in the query are missing.
|
||||
```
|
||||
|
||||
Your query was not submitted to the database because it's missing one or more
|
||||
parameters. You should define all the parameters referenced in the query in a
|
||||
valid JSON document. Check that the parameters are spelled correctly and that
|
||||
the document has a valid syntax.
|
||||
|
||||
## Issue 1007
|
||||
|
||||
```
|
||||
The hostname provided can't be resolved.
|
||||
```
|
||||
|
||||
The hostname provided when adding a new database is invalid and cannot be
|
||||
resolved. Please check that there are no typos in the hostname.
|
||||
|
||||
## Issue 1008
|
||||
|
||||
```
|
||||
The port is closed.
|
||||
```
|
||||
|
||||
The port provided when adding a new database is not open. Please check that
|
||||
the port number is correct, and that the database is running and listening on
|
||||
that port.
|
||||
|
||||
## Issue 1009
|
||||
|
||||
```
|
||||
The host might be down, and cannot be reached on the provided port.
|
||||
```
|
||||
|
||||
The host provided when adding a new database doesn't seem to be up.
|
||||
Additionally, it cannot be reached on the provided port. Please check that
|
||||
there are no firewall rules preventing access to the host.
|
||||
|
||||
## Issue 1010
|
||||
|
||||
```
|
||||
Superset encountered an error while running a command.
|
||||
```
|
||||
|
||||
Something unexpected happened, and Superset encountered an error while
|
||||
running a command. Please reach out to your administrator.
|
||||
|
||||
## Issue 1011
|
||||
|
||||
```
|
||||
Superset encountered an unexpected error.
|
||||
```
|
||||
|
||||
Something unexpected happened in the Superset backend. Please reach out
|
||||
to your administrator.
|
||||
|
||||
## Issue 1012
|
||||
|
||||
```
|
||||
The username provided when connecting to a database is not valid.
|
||||
```
|
||||
|
||||
The user provided a username that doesn't exist in the database. Please check
|
||||
that the username is typed correctly and exists in the database.
|
||||
|
||||
## Issue 1013
|
||||
|
||||
```
|
||||
The password provided when connecting to a database is not valid.
|
||||
```
|
||||
|
||||
The user provided a password that is incorrect. Please check that the
|
||||
password is typed correctly.
|
||||
|
||||
## Issue 1014
|
||||
|
||||
```
|
||||
Either the username or the password used are incorrect.
|
||||
```
|
||||
|
||||
Either the username provided does not exist or the password was written incorrectly. Please
|
||||
check that the username and password were typed correctly.
|
||||
|
||||
## Issue 1015
|
||||
|
||||
```
|
||||
Either the database is spelled incorrectly or does not exist.
|
||||
```
|
||||
|
||||
Either the database was written incorrectly or it does not exist. Check that it was typed correctly.
|
||||
|
||||
## Issue 1016
|
||||
|
||||
```
|
||||
The schema was deleted or renamed in the database.
|
||||
```
|
||||
|
||||
The schema was either removed or renamed. Check that the schema is typed correctly and exists.
|
||||
|
||||
## Issue 1017
|
||||
|
||||
```
|
||||
The user doesn't have the proper permissions to connect to the database
|
||||
```
|
||||
|
||||
We were unable to connect to your database. Please confirm that your service account has the Viewer and Job User roles on the project.
|
||||
|
||||
## Issue 1018
|
||||
|
||||
```
|
||||
One or more parameters needed to configure a database are missing.
|
||||
```
|
||||
|
||||
Not all parameters required to test, create, or edit a database were present. Please double check which parameters are needed, and that they are present.
|
||||
|
||||
## Issue 1019
|
||||
|
||||
```
|
||||
The submitted payload has the incorrect format.
|
||||
```
|
||||
|
||||
Please check that the request payload has the correct format (eg, JSON).
|
||||
|
||||
## Issue 1020
|
||||
|
||||
```
|
||||
The submitted payload has the incorrect schema.
|
||||
```
|
||||
|
||||
Please check that the request payload has the expected schema.
|
||||
|
||||
## Issue 1021
|
||||
|
||||
```
|
||||
Results backend needed for asynchronous queries is not configured.
|
||||
```
|
||||
|
||||
Your instance of Superset doesn't have a results backend configured, which is needed for asynchronous queries. Please contact an administrator for further assistance.
|
||||
|
||||
## Issue 1022
|
||||
|
||||
```
|
||||
Database does not allow data manipulation.
|
||||
```
|
||||
|
||||
Only `SELECT` statements are allowed against this database. Please contact an administrator if you need to run DML (data manipulation language) on this database.
|
||||
|
||||
## Issue 1023
|
||||
|
||||
```
|
||||
CTAS (create table as select) doesn't have a SELECT statement at the end.
|
||||
```
|
||||
|
||||
The last statement in a query run as CTAS (create table as select) MUST be a SELECT statement. Please make sure the last statement in the query is a SELECT.
|
||||
|
||||
## Issue 1024
|
||||
|
||||
```
|
||||
CVAS (create view as select) query has more than one statement.
|
||||
```
|
||||
|
||||
When running a CVAS (create view as select) the query should have a single statement. Please make sure the query has a single statement, and no extra semi-colons other than the last one.
|
||||
|
||||
## Issue 1025
|
||||
|
||||
```
|
||||
CVAS (create view as select) query is not a SELECT statement.
|
||||
```
|
||||
|
||||
When running a CVAS (create view as select) the query should be a SELECT statement. Please make sure the query has a single statement and it's a SELECT statement.
|
||||
|
||||
## Issue 1026
|
||||
|
||||
```
|
||||
Query is too complex and takes too long to run.
|
||||
```
|
||||
|
||||
The submitted query might be too complex to run under the time limit defined by your Superset administrator. Please double check your query and verify if it can be optimized. Alternatively, contact your administrator to increase the timeout period.
|
||||
|
||||
## Issue 1027
|
||||
|
||||
```
|
||||
The database is currently running too many queries.
|
||||
```
|
||||
|
||||
The database might be under heavy load, running too many queries. Please try again later, or contact an administrator for further assistance.
|
||||
|
||||
## Issue 1028
|
||||
|
||||
```
|
||||
One or more parameters specified in the query are malformatted.
|
||||
```
|
||||
|
||||
The query contains one or more malformed template parameters. Please check your query and confirm that all template parameters are surround by double braces, for example, "{{ ds }}". Then, try running your query again.
|
||||
|
||||
## Issue 1029
|
||||
|
||||
```
|
||||
The object does not exist in this database.
|
||||
```
|
||||
|
||||
Either the schema, column, or table do not exist in the database.
|
||||
|
||||
## Issue 1030
|
||||
|
||||
```
|
||||
The query potentially has a syntax error.
|
||||
```
|
||||
|
||||
The query might have a syntax error. Please check and run again.
|
||||
|
||||
## Issue 1031
|
||||
|
||||
```
|
||||
The results backend no longer has the data from the query.
|
||||
```
|
||||
|
||||
The results from the query might have been deleted from the results backend after some period. Please re-run your query.
|
||||
|
||||
## Issue 1032
|
||||
|
||||
```
|
||||
The query associated with the results was deleted.
|
||||
```
|
||||
|
||||
The query associated with the stored results no longer exists. Please re-run your query.
|
||||
|
||||
## Issue 1033
|
||||
|
||||
```
|
||||
The results stored in the backend were stored in a different format, and no longer can be deserialized.
|
||||
```
|
||||
|
||||
The query results were stored in a format that is no longer supported. Please re-run your query.
|
||||
|
||||
## Issue 1034
|
||||
|
||||
```
|
||||
The database port provided is invalid.
|
||||
```
|
||||
|
||||
Please check that the provided database port is an integer between 0 and 65535 (inclusive).
|
||||
|
||||
## Issue 1035
|
||||
|
||||
```
|
||||
Failed to start remote query on a worker.
|
||||
```
|
||||
|
||||
The query was not started by an asynchronous worker. Please reach out to your administrator for further assistance.
|
||||
|
||||
## Issue 1036
|
||||
|
||||
```
|
||||
The database was deleted.
|
||||
```
|
||||
|
||||
The operation failed because the database referenced no longer exists. Please reach out to your administrator for further assistance.
|
||||
|
|
@ -0,0 +1,26 @@
|
|||
---
|
||||
title: Roadmap
|
||||
hide_title: true
|
||||
sidebar_position: 8
|
||||
---
|
||||
|
||||
import useBaseUrl from "@docusaurus/useBaseUrl";
|
||||
|
||||
## Roadmap
|
||||
|
||||
You can find the approximate public roadmap for Superset [here](https://github.com/apache-superset/superset-roadmap/projects/1).
|
||||
|
||||
<a href="https://github.com/apache-superset/superset-roadmap/projects/1">
|
||||
<img
|
||||
src={useBaseUrl("/img/roadmap.png")}
|
||||
style={{
|
||||
maxWidth: "100%",
|
||||
boxShadow: "rgb(170, 170, 170) 0px 0px 3px 1px",
|
||||
}}
|
||||
/>
|
||||
</a>
|
||||
|
||||
Keep in mind that the roadmap represents only a subset of what's
|
||||
ahead. Many contributions come directly without ever making it onto the roadmap.
|
||||
Find out more about how the roadmap is managed in
|
||||
[SIP (Superset Improvement Proposal) 53](https://github.com/apache/superset/issues/10894)
|
||||
|
|
@ -0,0 +1,149 @@
|
|||
---
|
||||
title: Security
|
||||
hide_title: true
|
||||
sidebar_position: 10
|
||||
---
|
||||
|
||||
### Roles
|
||||
|
||||
Security in Superset is handled by Flask AppBuilder (FAB), an application development framework
|
||||
built on top of Flask. FAB provides authentication, user management, permissions and roles.
|
||||
Please read its [Security documentation](https://flask-appbuilder.readthedocs.io/en/latest/security.html).
|
||||
|
||||
### Provided Roles
|
||||
|
||||
Superset ships with a set of roles that are handled by Superset itself. You can assume
|
||||
that these roles will stay up-to-date as Superset evolves (and as you update Superset versions).
|
||||
|
||||
Even though **Admin** users have the ability, we don't recommend altering the
|
||||
permissions associated with each role (e.g. by removing or adding permissions to them). The permissions
|
||||
associated with each role will be re-synchronized to their original values when you run
|
||||
the **superset init** command (often done between Superset versions).
|
||||
|
||||
### Admin
|
||||
|
||||
Admins have all possible rights, including granting or revoking rights from other
|
||||
users and altering other people’s slices and dashboards.
|
||||
|
||||
### Alpha
|
||||
|
||||
Alpha users have access to all data sources, but they cannot grant or revoke access
|
||||
from other users. They are also limited to altering the objects that they own. Alpha users can add and alter data sources.
|
||||
|
||||
### Gamma
|
||||
|
||||
Gamma users have limited access. They can only consume data coming from data sources
|
||||
they have been given access to through another complementary role. They only have access to
|
||||
view the slices and dashboards made from data sources that they have access to. Currently Gamma
|
||||
users are not able to alter or add data sources. We assume that they are mostly content consumers, though they can create slices and dashboards.
|
||||
|
||||
Also note that when Gamma users look at the dashboards and slices list view, they will
|
||||
only see the objects that they have access to.
|
||||
|
||||
### sql_lab
|
||||
|
||||
The **sql_lab** role grants access to SQL Lab. Note that while **Admin** users have access
|
||||
to all databases by default, both **Alpha** and **Gamma** users need to be given access on a per database basis.
|
||||
|
||||
### Public
|
||||
|
||||
To allow logged-out users to access some Superset features, you can use the `PUBLIC_ROLE_LIKE` config setting and assign it to another role whose permissions you want passed to this role.
|
||||
|
||||
For example, by setting `PUBLIC_ROLE_LIKE = Gamma` in your `superset_config.py` file, you grant
|
||||
public role the same set of permissions as for the **Gamma** role. This is useful if one
|
||||
wants to enable anonymous users to view dashboards. Explicit grant on specific datasets is
|
||||
still required, meaning that you need to edit the **Public** role and add the public data sources to the role manually.
|
||||
|
||||
### Managing Data Source Access for Gamma Roles
|
||||
|
||||
Here’s how to provide users access to only specific datasets. First make sure the users with
|
||||
limited access have [only] the Gamma role assigned to them. Second, create a new role (Menu -> Security -> List Roles) and click the + sign.
|
||||
|
||||
This new window allows you to give this new role a name, attribute it to users and select the
|
||||
tables in the **Permissions** dropdown. To select the data sources you want to associate with this role, simply click on the dropdown and use the typeahead to search for your table names.
|
||||
|
||||
You can then confirm with users assigned to the **Gamma** role that they see the
|
||||
objects (dashboards and slices) associated with the tables you just extended them.
|
||||
|
||||
### Customizing Permissions
|
||||
|
||||
The permissions exposed by FAB are very granular and allow for a great level of
|
||||
customization. FAB creates many permissions automagically for each model that is
|
||||
created (can_add, can_delete, can_show, can_edit, …) as well as for each view.
|
||||
On top of that, Superset can expose more granular permissions like **all_datasource_access**.
|
||||
|
||||
**We do not recommend altering the 3 base roles as there are a set of assumptions that
|
||||
Superset is built upon**. It is possible though for you to create your own roles, and union them to existing ones.
|
||||
|
||||
### Permissions
|
||||
|
||||
Roles are composed of a set of permissions, and Superset has many categories of
|
||||
permissions. Here are the different categories of permissions:
|
||||
|
||||
- Model & Action: models are entities like Dashboard, Slice, or User. Each model has
|
||||
a fixed set of permissions, like **can_edit**, **can_show**, **can_delete**, **can_list**, **can_add**,
|
||||
and so on. For example, you can allow a user to delete dashboards by adding **can_delete** on
|
||||
Dashboard entity to a role and granting this user that role.
|
||||
- Views: views are individual web pages, like the Explore view or the SQL Lab view.
|
||||
When granted to a user, they will see that view in its menu items, and be able to load that page.
|
||||
- Data source: For each data source, a permission is created. If the user does not have the
|
||||
`all_datasource_access permission` granted, the user will only be able to see Slices or explore the data sources that are granted to them
|
||||
- Database: Granting access to a database allows for the user to access all
|
||||
data sources within that database, and will enable the user to query that
|
||||
database in SQL Lab, provided that the SQL Lab specific permission have been granted to the user
|
||||
|
||||
### Restricting Access to a Subset of Data Sources
|
||||
|
||||
We recommend giving a user the **Gamma** role plus any other roles that would add
|
||||
access to specific data sources. We recommend that you create individual roles for
|
||||
each access profile. For example, the users on the Finance team might have access to a set of
|
||||
databases and data sources; these permissions can be consolidated in a single role.
|
||||
Users with this profile then need to be assigned the **Gamma** role as a foundation to
|
||||
the models and views they can access, and that Finance role that is a collection of permissions to data objects.
|
||||
|
||||
A user can have multiple roles associated with them. For example, an executive on the Finance
|
||||
team could be granted **Gamma**, **Finance**, and the **Executive** roles. The **Executive**
|
||||
role could provide access to a set of data sources and dashboards made available only to executives.
|
||||
In the **Dashboards** view, a user can only see the ones they have access too
|
||||
based on the roles and permissions that were attributed.
|
||||
|
||||
### Row Level Security
|
||||
|
||||
Using Row Level Security filters (under the **Security** menu) you can create filters
|
||||
that are assigned to a particular table, as well as a set of roles.
|
||||
If you want members of the Finance team to only have access to
|
||||
rows where `department = "finance"`, you could:
|
||||
|
||||
- Create a Row Level Security filter with that clause (`department = "finance"`)
|
||||
- Then assign the clause to the **Finance** role and the table it applies to
|
||||
|
||||
The **clause** field, which can contain arbitrary text, is then added to the generated
|
||||
SQL statement’s WHERE clause. So you could even do something like create a filter
|
||||
for the last 30 days and apply it to a specific role, with a clause
|
||||
like `date_field > DATE_SUB(NOW(), INTERVAL 30 DAY)`. It can also support
|
||||
multiple conditions: `client_id = 6` AND `advertiser="foo"`, etc.
|
||||
|
||||
All relevant Row level security filters will be combined together (under the hood,
|
||||
the different SQL clauses are combined using AND statements). This means it's
|
||||
possible to create a situation where two roles conflict in such a way as to limit a table subset to empty.
|
||||
|
||||
For example, the filters `client_id=4` and `client_id=5`, applied to a role,
|
||||
will result in users of that role having `client_id=4` AND `client_id=5`
|
||||
added to their query, which can never be true.
|
||||
|
||||
### Reporting Security Vulnerabilities
|
||||
|
||||
Apache Software Foundation takes a rigorous standpoint in annihilating the security issues in its
|
||||
software projects. Apache Superset is highly sensitive and forthcoming to issues pertaining to its
|
||||
features and functionality.
|
||||
|
||||
If you have apprehensions regarding Superset security or you discover vulnerability or potential
|
||||
threat, don’t hesitate to get in touch with the Apache Security Team by dropping a mail at
|
||||
security@apache.org. In the mail, specify the project name Superset with the description of the
|
||||
issue or potential threat. You are also urged to recommend the way to reproduce and replicate the
|
||||
issue. The security team and the Superset community will get back to you after assessing and
|
||||
analysing the findings.
|
||||
|
||||
PLEASE PAY ATTENTION to report the security issue on the security email before disclosing it on
|
||||
public domain. The ASF Security Team maintains a page with the description of how vulnerabilities
|
||||
and potential threats are handled, check their web page for more details.
|
||||
|
|
@ -0,0 +1,217 @@
|
|||
/**
|
||||
* Licensed to the Apache Software Foundation (ASF) under one
|
||||
* or more contributor license agreements. See the NOTICE file
|
||||
* distributed with this work for additional information
|
||||
* regarding copyright ownership. The ASF licenses this file
|
||||
* to you under the Apache License, Version 2.0 (the
|
||||
* "License"); you may not use this file except in compliance
|
||||
* with the License. You may obtain a copy of the License at
|
||||
*
|
||||
* http://www.apache.org/licenses/LICENSE-2.0
|
||||
*
|
||||
* Unless required by applicable law or agreed to in writing,
|
||||
* software distributed under the License is distributed on an
|
||||
* "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
|
||||
* KIND, either express or implied. See the License for the
|
||||
* specific language governing permissions and limitations
|
||||
* under the License.
|
||||
*/
|
||||
|
||||
// @ts-check
|
||||
// Note: type annotations allow type checking and IDEs autocompletion
|
||||
|
||||
const lightCodeTheme = require('prism-react-renderer/themes/github');
|
||||
const darkCodeTheme = require('prism-react-renderer/themes/dracula');
|
||||
|
||||
/** @type {import('@docusaurus/types').Config} */
|
||||
const config = {
|
||||
title: 'Superset',
|
||||
tagline:
|
||||
'Apache Superset is a modern data exploration and visualization platform',
|
||||
url: 'https://superset.apache.org',
|
||||
baseUrl: '/',
|
||||
onBrokenLinks: 'throw',
|
||||
onBrokenMarkdownLinks: 'warn',
|
||||
favicon: 'img/favicon.ico',
|
||||
organizationName: 'apache', // Usually your GitHub org/user name.
|
||||
projectName: 'superset', // Usually your repo name.
|
||||
plugins: [
|
||||
[
|
||||
'@docusaurus/plugin-client-redirects',
|
||||
{
|
||||
fromExtensions: ['html', 'htm'],
|
||||
toExtensions: ['exe', 'zip'],
|
||||
redirects: [
|
||||
{
|
||||
to: '/docs/installation/installing-superset-using-docker-compose',
|
||||
from: '/installation.html',
|
||||
},
|
||||
{
|
||||
to: '/docs/intro',
|
||||
from: '/tutorials.html',
|
||||
},
|
||||
{
|
||||
to: '/docs/creating-charts-dashboards/first-dashboard',
|
||||
from: '/admintutorial.html',
|
||||
},
|
||||
{
|
||||
to: '/docs/creating-charts-dashboards/first-dashboard',
|
||||
from: '/usertutorial.html',
|
||||
},
|
||||
{
|
||||
to: '/docs/security',
|
||||
from: '/security.html',
|
||||
},
|
||||
{
|
||||
to: '/docs/installation/sql-templating',
|
||||
from: '/sqllab.html',
|
||||
},
|
||||
{
|
||||
to: '/docs/installation/sql-templating',
|
||||
from: '/gallery.html',
|
||||
},
|
||||
{
|
||||
to: '/docs/intro',
|
||||
from: '/sqllab.html',
|
||||
},
|
||||
{
|
||||
to: '/docs/databases/druid',
|
||||
from: '/druid.html',
|
||||
},
|
||||
{
|
||||
to: '/docs/miscellaneous/country-map-tools',
|
||||
from: '/misc.html',
|
||||
},
|
||||
{
|
||||
to: '/docs/miscellaneous/country-map-tools',
|
||||
from: '/visualization.html',
|
||||
},
|
||||
{
|
||||
to: '/docs/frequently-asked-questions',
|
||||
from: '/videos.html',
|
||||
},
|
||||
{
|
||||
to: '/docs/frequently-asked-questions',
|
||||
from: '/faq.html',
|
||||
},
|
||||
{
|
||||
to: '/docs/intro',
|
||||
from: '/index.html',
|
||||
},
|
||||
{
|
||||
to: '/docs/creating-charts-dashboards',
|
||||
from: '/tutorial.html',
|
||||
},
|
||||
{
|
||||
to: '/docs/installation/alerts-reports',
|
||||
from: '/docs/installation/email-reports',
|
||||
},
|
||||
],
|
||||
},
|
||||
],
|
||||
],
|
||||
|
||||
presets: [
|
||||
[
|
||||
'@docusaurus/preset-classic',
|
||||
/** @type {import('@docusaurus/preset-classic').Options} */
|
||||
({
|
||||
docs: {
|
||||
sidebarPath: require.resolve('./sidebars.js'),
|
||||
// Please change this to your repo.
|
||||
editUrl: 'https://github.com/facebook/docusaurus/edit/main/website/',
|
||||
},
|
||||
blog: {
|
||||
showReadingTime: true,
|
||||
// Please change this to your repo.
|
||||
editUrl:
|
||||
'https://github.com/facebook/docusaurus/edit/main/website/blog/',
|
||||
},
|
||||
theme: {
|
||||
customCss: require.resolve('./src/css/custom.css'),
|
||||
},
|
||||
}),
|
||||
],
|
||||
],
|
||||
|
||||
themeConfig:
|
||||
/** @type {import('@docusaurus/preset-classic').ThemeConfig} */
|
||||
({
|
||||
colorMode: {
|
||||
defaultMode: 'light',
|
||||
disableSwitch: true,
|
||||
},
|
||||
navbar: {
|
||||
logo: {
|
||||
alt: 'Superset Logo',
|
||||
src: 'img/superset-logo-horiz.svg',
|
||||
srcDark: 'img/superset-logo-horiz-dark.svg',
|
||||
},
|
||||
items: [
|
||||
{
|
||||
type: 'doc',
|
||||
docId: 'intro',
|
||||
position: 'left',
|
||||
label: 'Documentation',
|
||||
},
|
||||
{ to: '/gallery', label: 'Gallery', position: 'left' },
|
||||
{ to: '/community', label: 'Community', position: 'left' },
|
||||
{ to: '/resources', label: 'Resources', position: 'left' },
|
||||
{
|
||||
href: 'https://github.com/apache/superset',
|
||||
label: 'GitHub',
|
||||
position: 'right',
|
||||
},
|
||||
],
|
||||
},
|
||||
footer: {
|
||||
style: 'dark',
|
||||
links: [
|
||||
{
|
||||
title: 'Docs',
|
||||
items: [
|
||||
{
|
||||
label: 'Tutorial',
|
||||
to: '/docs/intro',
|
||||
},
|
||||
],
|
||||
},
|
||||
{
|
||||
title: 'Community',
|
||||
items: [
|
||||
{
|
||||
label: 'Stack Overflow',
|
||||
href: 'https://stackoverflow.com/questions/tagged/docusaurus',
|
||||
},
|
||||
{
|
||||
label: 'Discord',
|
||||
href: 'https://discordapp.com/invite/docusaurus',
|
||||
},
|
||||
{
|
||||
label: 'Twitter',
|
||||
href: 'https://twitter.com/docusaurus',
|
||||
},
|
||||
],
|
||||
},
|
||||
{
|
||||
title: 'More',
|
||||
items: [
|
||||
{
|
||||
label: 'GitHub',
|
||||
href: 'https://github.com/facebook/docusaurus',
|
||||
},
|
||||
],
|
||||
},
|
||||
],
|
||||
copyright: `Copyright © ${new Date().getFullYear()} My Project, Inc. Built with Docusaurus.`,
|
||||
},
|
||||
prism: {
|
||||
theme: lightCodeTheme,
|
||||
darkTheme: darkCodeTheme,
|
||||
},
|
||||
}),
|
||||
|
||||
|
||||
};
|
||||
|
||||
module.exports = config;
|
||||
|
|
@ -0,0 +1,57 @@
|
|||
{
|
||||
"name": "docs-v-2",
|
||||
"version": "0.0.0",
|
||||
"private": true,
|
||||
"scripts": {
|
||||
"docusaurus": "docusaurus",
|
||||
"start": "docusaurus start",
|
||||
"build": "docusaurus build",
|
||||
"swizzle": "docusaurus swizzle",
|
||||
"deploy": "docusaurus deploy",
|
||||
"clear": "docusaurus clear",
|
||||
"serve": "docusaurus serve",
|
||||
"write-translations": "docusaurus write-translations",
|
||||
"write-heading-ids": "docusaurus write-heading-ids",
|
||||
"typecheck": "tsc"
|
||||
},
|
||||
"dependencies": {
|
||||
"@ant-design/icons": "^4.7.0",
|
||||
"@docusaurus/core": "2.0.0-beta.9",
|
||||
"@docusaurus/plugin-client-redirects": "^2.0.0-beta.14",
|
||||
"@docusaurus/preset-classic": "2.0.0-beta.9",
|
||||
"@emotion/core": "^10.1.1",
|
||||
"@emotion/styled": "^10.0.27",
|
||||
"@mdx-js/react": "^1.6.21",
|
||||
"@superset-ui/style": "^0.14.23",
|
||||
"@svgr/webpack": "^5.5.0",
|
||||
"antd": "^4.8.0",
|
||||
"buffer": "^6.0.3",
|
||||
"clsx": "^1.1.1",
|
||||
"file-loader": "^6.2.0",
|
||||
"prism-react-renderer": "^1.2.1",
|
||||
"react": "^17.0.1",
|
||||
"react-dom": "^17.0.1",
|
||||
"react-github-btn": "^1.2.0",
|
||||
"stream": "^0.0.2",
|
||||
"swagger-ui-react": "^4.1.2",
|
||||
"theme-ui": "^0.3.1",
|
||||
"url-loader": "^4.1.1"
|
||||
},
|
||||
"devDependencies": {
|
||||
"@docusaurus/module-type-aliases": "2.0.0-beta.9",
|
||||
"@tsconfig/docusaurus": "^1.0.4",
|
||||
"typescript": "^4.3.5"
|
||||
},
|
||||
"browserslist": {
|
||||
"production": [
|
||||
">0.5%",
|
||||
"not dead",
|
||||
"not op_mini all"
|
||||
],
|
||||
"development": [
|
||||
"last 1 chrome version",
|
||||
"last 1 firefox version",
|
||||
"last 1 safari version"
|
||||
]
|
||||
}
|
||||
}
|
||||
|
|
@ -0,0 +1,50 @@
|
|||
/**
|
||||
* Licensed to the Apache Software Foundation (ASF) under one
|
||||
* or more contributor license agreements. See the NOTICE file
|
||||
* distributed with this work for additional information
|
||||
* regarding copyright ownership. The ASF licenses this file
|
||||
* to you under the Apache License, Version 2.0 (the
|
||||
* "License"); you may not use this file except in compliance
|
||||
* with the License. You may obtain a copy of the License at
|
||||
*
|
||||
* http://www.apache.org/licenses/LICENSE-2.0
|
||||
*
|
||||
* Unless required by applicable law or agreed to in writing,
|
||||
* software distributed under the License is distributed on an
|
||||
* "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
|
||||
* KIND, either express or implied. See the License for the
|
||||
* specific language governing permissions and limitations
|
||||
* under the License.
|
||||
*/
|
||||
|
||||
/**
|
||||
* Creating a sidebar enables you to:
|
||||
- create an ordered group of docs
|
||||
- render a sidebar for each doc of that group
|
||||
- provide next/previous navigation
|
||||
|
||||
The sidebars can be generated from the filesystem, or explicitly defined here.
|
||||
|
||||
Create as many sidebars as you want.
|
||||
*/
|
||||
|
||||
// @ts-check
|
||||
|
||||
/** @type {import('@docusaurus/plugin-content-docs').SidebarsConfig} */
|
||||
const sidebars = {
|
||||
// By default, Docusaurus generates a sidebar from the docs folder structure
|
||||
tutorialSidebar: [{type: 'autogenerated', dirName: '.'}],
|
||||
|
||||
// But you can create a sidebar manually
|
||||
/*
|
||||
tutorialSidebar: [
|
||||
{
|
||||
type: 'category',
|
||||
label: 'Tutorial',
|
||||
items: ['hello'],
|
||||
},
|
||||
],
|
||||
*/
|
||||
};
|
||||
|
||||
module.exports = sidebars;
|
||||
|
|
@ -0,0 +1,91 @@
|
|||
/**
|
||||
* Licensed to the Apache Software Foundation (ASF) under one
|
||||
* or more contributor license agreements. See the NOTICE file
|
||||
* distributed with this work for additional information
|
||||
* regarding copyright ownership. The ASF licenses this file
|
||||
* to you under the Apache License, Version 2.0 (the
|
||||
* "License"); you may not use this file except in compliance
|
||||
* with the License. You may obtain a copy of the License at
|
||||
*
|
||||
* http://www.apache.org/licenses/LICENSE-2.0
|
||||
*
|
||||
* Unless required by applicable law or agreed to in writing,
|
||||
* software distributed under the License is distributed on an
|
||||
* "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
|
||||
* KIND, either express or implied. See the License for the
|
||||
* specific language governing permissions and limitations
|
||||
* under the License.
|
||||
*/
|
||||
|
||||
/**
|
||||
* Any CSS included here will be global. The classic template
|
||||
* bundles Infima by default. Infima is a CSS framework designed to
|
||||
* work well for content-centric websites.
|
||||
*/
|
||||
|
||||
/* You can override the default Infima variables here. */
|
||||
:root {
|
||||
--ifm-color-primary: #20a7c9;
|
||||
--ifm-color-primary-dark: #1985a0;
|
||||
--ifm-color-primary-darker: #t;
|
||||
--ifm-color-primary-darkest: #ffffff;
|
||||
--ifm-color-primary-light: #79cade;
|
||||
--ifm-color-primary-lighter: #a5dbe9;
|
||||
--ifm-color-primary-lightest: #d2edf4;
|
||||
--ifm-code-font-size: 95%;
|
||||
--ifm-menu-link-padding-vertical: 12px;
|
||||
--doc-sidebar-width: 350px !important;
|
||||
--ifm-navbar-height: none;
|
||||
}
|
||||
|
||||
.docusaurus-highlight-code-line {
|
||||
background-color: rgba(0, 0, 0, 0.1);
|
||||
display: block;
|
||||
margin: 0 calc(-1 * var(--ifm-pre-padding));
|
||||
padding: 0 var(--ifm-pre-padding);
|
||||
}
|
||||
|
||||
html[data-theme='dark'] .docusaurus-highlight-code-line {
|
||||
background-color: rgba(0, 0, 0, 0.3);
|
||||
}
|
||||
|
||||
.navbar__logo {
|
||||
height: 40px;
|
||||
}
|
||||
|
||||
.navbar-sidebar__brand {
|
||||
padding-left: 0;
|
||||
}
|
||||
|
||||
.menu,
|
||||
.navbar {
|
||||
font-size: 14px;
|
||||
font-weight: 400;
|
||||
}
|
||||
|
||||
/* Hacks to disable Swagger UI's "try it out" interactive mode */
|
||||
.try-out,
|
||||
.auth-wrapper,
|
||||
.information-container {
|
||||
display: none !important;
|
||||
}
|
||||
|
||||
.swagger-ui table td,
|
||||
.swagger-ui table th,
|
||||
.swagger-ui table tr {
|
||||
border: none;
|
||||
}
|
||||
|
||||
.markdown h2:first-child {
|
||||
margin-top: 0.5em;
|
||||
}
|
||||
|
||||
@media only screen and (min-width: 800px) {
|
||||
.navbar__logo {
|
||||
height: 50px;
|
||||
}
|
||||
|
||||
.navbar {
|
||||
padding-left: 0;
|
||||
}
|
||||
}
|
||||
|
|
@ -0,0 +1,119 @@
|
|||
/**
|
||||
* Licensed to the Apache Software Foundation (ASF) under one
|
||||
* or more contributor license agreements. See the NOTICE file
|
||||
* distributed with this work for additional information
|
||||
* regarding copyright ownership. The ASF licenses this file
|
||||
* to you under the Apache License, Version 2.0 (the
|
||||
* "License"); you may not use this file except in compliance
|
||||
* with the License. You may obtain a copy of the License at
|
||||
*
|
||||
* http://www.apache.org/licenses/LICENSE-2.0
|
||||
*
|
||||
* Unless required by applicable law or agreed to in writing,
|
||||
* software distributed under the License is distributed on an
|
||||
* "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
|
||||
* KIND, either express or implied. See the License for the
|
||||
* specific language governing permissions and limitations
|
||||
* under the License.
|
||||
*/
|
||||
import React from 'react';
|
||||
import styled from '@emotion/styled';
|
||||
import { List } from 'antd';
|
||||
import Layout from '@theme/Layout';
|
||||
|
||||
const links = [
|
||||
[
|
||||
'https://join.slack.com/t/apache-superset/shared_invite/zt-uxbh5g36-AISUtHbzOXcu0BIj7kgUaw',
|
||||
'Slack',
|
||||
'interact with other Superset users and community members',
|
||||
],
|
||||
[
|
||||
'https://github.com/apache/superset',
|
||||
'GitHub',
|
||||
'create tickets to report issues, report bugs, and suggest new features',
|
||||
],
|
||||
[
|
||||
'https://lists.apache.org/list.html?dev@superset.apache.org',
|
||||
'dev@ Mailing List',
|
||||
'participate in conversations with committers and contributors',
|
||||
],
|
||||
[
|
||||
'https://stackoverflow.com/questions/tagged/superset+apache-superset',
|
||||
'Stack Overflow',
|
||||
'our growing knowledge base',
|
||||
],
|
||||
[
|
||||
'https://www.meetup.com/Global-Apache-Superset-Community-Meetup/',
|
||||
'Superset Meetup Group',
|
||||
'join our monthly virtual meetups and register for any upcoming events',
|
||||
],
|
||||
[
|
||||
'https://github.com/apache/superset/blob/master/RESOURCES/INTHEWILD.md',
|
||||
'Organizations',
|
||||
'a list of some of the organizations using Superset in production',
|
||||
],
|
||||
[
|
||||
'https://github.com/apache-superset/awesome-apache-superset',
|
||||
'Contributors Guide',
|
||||
'Interested in contributing? Learn how to contribute and best practices',
|
||||
],
|
||||
];
|
||||
|
||||
const StyledMain = styled('main')`
|
||||
padding-bottom: 60px;
|
||||
padding-left: 16px;
|
||||
padding-right: 16px;
|
||||
section {
|
||||
width: 100%;
|
||||
max-width: 800px;
|
||||
margin: 0 auto;
|
||||
padding: 60px 0 0 0;
|
||||
font-size: 17px;
|
||||
&:first-of-type{
|
||||
padding: 40px;
|
||||
background-image: linear-gradient(120deg, #d6f2f8, #52c6e3);
|
||||
border-radius: 0 0 10px;
|
||||
}
|
||||
}
|
||||
`;
|
||||
|
||||
const StyledGetInvolved = styled('div')`
|
||||
margin-bottom: 25px;
|
||||
`;
|
||||
|
||||
const Community = () => {
|
||||
return (
|
||||
<Layout
|
||||
title="Community"
|
||||
description="Community website for Apache Superset, a data visualization and data exploration platform"
|
||||
>
|
||||
<StyledMain>
|
||||
<section>
|
||||
<h1 className="title">Community</h1>
|
||||
Get involved in our welcoming, fast growing community!
|
||||
</section>
|
||||
<section className="joinCommunity">
|
||||
<StyledGetInvolved>
|
||||
<h2>Get involved!</h2>
|
||||
<List
|
||||
size="small"
|
||||
bordered
|
||||
dataSource={links}
|
||||
renderItem={([href, link, post]) => (
|
||||
<List.Item>
|
||||
<a href={href}>{link}</a>
|
||||
{' '}
|
||||
-
|
||||
{' '}
|
||||
{post}
|
||||
</List.Item>
|
||||
)}
|
||||
/>
|
||||
</StyledGetInvolved>
|
||||
</section>
|
||||
</StyledMain>
|
||||
</Layout>
|
||||
);
|
||||
};
|
||||
|
||||
export default Community;
|
||||
|
|
@ -0,0 +1,463 @@
|
|||
/**
|
||||
* Licensed to the Apache Software Foundation (ASF) under one
|
||||
* or more contributor license agreements. See the NOTICE file
|
||||
* distributed with this work for additional information
|
||||
* regarding copyright ownership. The ASF licenses this file
|
||||
* to you under the Apache License, Version 2.0 (the
|
||||
* "License"); you may not use this file except in compliance
|
||||
* with the License. You may obtain a copy of the License at
|
||||
*
|
||||
* http://www.apache.org/licenses/LICENSE-2.0
|
||||
*
|
||||
* Unless required by applicable law or agreed to in writing,
|
||||
* software distributed under the License is distributed on an
|
||||
* "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
|
||||
* KIND, either express or implied. See the License for the
|
||||
* specific language governing permissions and limitations
|
||||
* under the License.
|
||||
*/
|
||||
import React, { useRef, useState } from 'react';
|
||||
import Layout from '@theme/Layout';
|
||||
import Link from '@docusaurus/Link';
|
||||
import {
|
||||
Button, Col, Row, Carousel,
|
||||
} from 'antd';
|
||||
import styled from '@emotion/styled';
|
||||
import { supersetTheme } from '@superset-ui/style';
|
||||
import {
|
||||
DeploymentUnitOutlined,
|
||||
FireOutlined,
|
||||
DotChartOutlined,
|
||||
DatabaseOutlined,
|
||||
} from '@ant-design/icons';
|
||||
import GitHubButton from 'react-github-btn';
|
||||
import 'antd/dist/antd.css';
|
||||
import { mq } from '../utils';
|
||||
import { Databases } from '../resources/data';
|
||||
|
||||
const { colors } = supersetTheme;
|
||||
|
||||
const StyledMain = styled('main')`
|
||||
text-align: center;
|
||||
.alert-color {
|
||||
color: ${colors.alert.base};
|
||||
}
|
||||
.error-color {
|
||||
color: ${colors.error.base};
|
||||
}
|
||||
.warning-color {
|
||||
color: ${colors.warning.base};
|
||||
}
|
||||
.info-color {
|
||||
color: ${colors.info.base};
|
||||
}
|
||||
.success-color {
|
||||
color: ${colors.success.base};
|
||||
}
|
||||
.secondary-color {
|
||||
color: ${colors.secondary.base};
|
||||
}
|
||||
.info-text {
|
||||
font-size: 32px;
|
||||
font-weight: normal;
|
||||
max-width: 600px;
|
||||
margin: auto;
|
||||
}
|
||||
.info-text-smaller {
|
||||
font-size: 24px;
|
||||
max-width: 800px;
|
||||
}
|
||||
`;
|
||||
|
||||
const StyledTitleContainer = styled('div')`
|
||||
position: relative;
|
||||
padding-top: 60px;
|
||||
padding-bottom: 80px;
|
||||
padding-left: 20px;
|
||||
padding-right: 20px;
|
||||
background-image: url('img/data-point.jpg');
|
||||
background-size: cover;
|
||||
background-position-x: right;
|
||||
.github-section {
|
||||
margin-bottom: 40px;
|
||||
margin-top: 40px;
|
||||
.github-button {
|
||||
margin: 5px;
|
||||
}
|
||||
}
|
||||
.logo-horiz {
|
||||
margin-top: 20px;
|
||||
margin-bottom: 20px;
|
||||
width: 600px;
|
||||
max-width: 100%;
|
||||
${[mq[3]]} {
|
||||
width: 550px;
|
||||
}
|
||||
${[mq[2]]} {
|
||||
width: 450px;
|
||||
}
|
||||
${[mq[1]]} {
|
||||
width: 425px;
|
||||
}
|
||||
${[mq[0]]} {
|
||||
width: 400px;
|
||||
}
|
||||
}
|
||||
.alert {
|
||||
color: #0c5460;
|
||||
background-color: #d1ecf1;
|
||||
border-color: #bee5eb;
|
||||
max-width: 600px;
|
||||
margin: 0 auto;
|
||||
padding: 0.75rem 1.25rem;
|
||||
margin-top: 83px;
|
||||
border: 1px solid transparent;
|
||||
border-radius: 0.25rem;
|
||||
}
|
||||
`;
|
||||
|
||||
const StyledHeading = styled('h2')`
|
||||
font-size: 55px;
|
||||
text-align: center;
|
||||
`;
|
||||
|
||||
const StyledFeatures = styled('div')`
|
||||
background: #fff;
|
||||
padding: 5vw 0;
|
||||
margin-top: 0px;
|
||||
margin-bottom: 30px;
|
||||
.featureList {
|
||||
padding: 40px;
|
||||
width: 100%;
|
||||
list-style-type: none;
|
||||
margin: 0 auto;
|
||||
max-width: 1000px;
|
||||
.feature {
|
||||
padding: 20px;
|
||||
text-align: center;
|
||||
margin-bottom: 40px;
|
||||
.imagePlaceHolder {
|
||||
svg {
|
||||
width: 70px;
|
||||
height: 70px;
|
||||
}
|
||||
margin-bottom: 15px;
|
||||
}
|
||||
.featureText {
|
||||
color: ${colors.grayscale.dark2};
|
||||
font-size: 16px;
|
||||
strong {
|
||||
font-size: 22px;
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
.heading {
|
||||
font-size: 22px;
|
||||
margin: 0 auto;
|
||||
text-align: center;
|
||||
}
|
||||
`;
|
||||
|
||||
const StyledIntegrations = styled('div')`
|
||||
background: white;
|
||||
margin-bottom: 64px;
|
||||
.databaseSub {
|
||||
text-align: center;
|
||||
display: block;
|
||||
margin-bottom: 40px;
|
||||
font-size: 18px;
|
||||
}
|
||||
|
||||
.database-list {
|
||||
margin-top: 100px;
|
||||
list-style-type: none;
|
||||
padding: 0px;
|
||||
max-width: 1000px;
|
||||
margin: 0 auto;
|
||||
display: flex;
|
||||
flex-wrap: wrap;
|
||||
justify-content: space-around;
|
||||
margin-bottom: 50px;
|
||||
li {
|
||||
padding: 15px;
|
||||
}
|
||||
}
|
||||
`;
|
||||
|
||||
const CarouselSection = styled('div')`
|
||||
.toggleContainer {
|
||||
display: flex;
|
||||
flex-direction: column;
|
||||
margin-bottom: 100px;
|
||||
position: relative;
|
||||
.toggleBtns {
|
||||
display: flex;
|
||||
flex-direction: row;
|
||||
/* ${[mq[0]]} {
|
||||
flex-direction: column;
|
||||
} */
|
||||
justify-content: center;
|
||||
.toggle {
|
||||
margin: 10px;
|
||||
color: #666;
|
||||
border: 1px solid #888;
|
||||
background-color: #20a7c911;
|
||||
border-radius: 3px;
|
||||
padding: 16px;
|
||||
transition: all 0.25s;
|
||||
overflow: visible;
|
||||
${[mq[0]]} {
|
||||
> span {
|
||||
display: none;
|
||||
position: absolute;
|
||||
bottom: 0px;
|
||||
left: 50%;
|
||||
width: 100%;
|
||||
transform: translate(-50%, 100%);
|
||||
}
|
||||
h2 {
|
||||
font-size: 14px;
|
||||
margin: 0;
|
||||
}
|
||||
}
|
||||
&:hover {
|
||||
cursor: pointer;
|
||||
color: ${colors.primary.base};
|
||||
border: 1px solid ${colors.primary.base};
|
||||
}
|
||||
&.active {
|
||||
background: red;
|
||||
background: #20a7c933;
|
||||
${[mq[0]]} {
|
||||
> span {
|
||||
display: block;
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
}
|
||||
.imageContainer {
|
||||
img {
|
||||
margin: 0 auto;
|
||||
width: 80%;
|
||||
box-shadow: 0 0 3px #aaa;
|
||||
margin-top: 5px;
|
||||
margin-bottom: 5px;
|
||||
}
|
||||
}
|
||||
}
|
||||
`;
|
||||
interface featureProps {
|
||||
icon: React.ReactNode,
|
||||
title: string,
|
||||
descr: string,
|
||||
}
|
||||
const Feature = ({ icon, title, descr }: featureProps) => (
|
||||
<li className="feature">
|
||||
<div className="imagePlaceHolder">
|
||||
{icon}
|
||||
</div>
|
||||
<div className="featureText">
|
||||
<h3>{title}</h3>
|
||||
{descr}
|
||||
</div>
|
||||
</li>
|
||||
);
|
||||
|
||||
export default function Home(): JSX.Element {
|
||||
const slider = useRef(null);
|
||||
|
||||
const [slideIndex, setSlideIndex] = useState(0);
|
||||
|
||||
const onChange = (index) => {
|
||||
setSlideIndex(index);
|
||||
};
|
||||
|
||||
return (
|
||||
<Layout
|
||||
title="Welcome"
|
||||
description="Community website for Apache Superset, a data visualization and data exploration platform"
|
||||
>
|
||||
<StyledMain>
|
||||
<StyledTitleContainer>
|
||||
<img className="logo-horiz" src="img/superset-logo-horiz-apache.svg" alt="logo-horiz" />
|
||||
<div className="info-text">
|
||||
Apache Superset is a modern data exploration and visualization
|
||||
platform
|
||||
</div>
|
||||
<div className="github-section">
|
||||
<span className="github-button">
|
||||
<GitHubButton
|
||||
href="https://github.com/apache/superset"
|
||||
data-size="large"
|
||||
data-show-count="true"
|
||||
aria-label="Star apache/superset on GitHub"
|
||||
>
|
||||
Star
|
||||
</GitHubButton>
|
||||
</span>
|
||||
<span className="github-button">
|
||||
<GitHubButton
|
||||
href="https://github.com/apache/superset/subscription"
|
||||
data-size="large"
|
||||
data-show-count="true"
|
||||
aria-label="Watch apache/superset on GitHub"
|
||||
>
|
||||
Watch
|
||||
</GitHubButton>
|
||||
</span>
|
||||
<span className="github-button">
|
||||
<GitHubButton
|
||||
href="https://github.com/apache/superset/fork"
|
||||
data-size="large"
|
||||
data-show-count="true"
|
||||
aria-label="Fork apache/superset on GitHub"
|
||||
>
|
||||
Fork
|
||||
</GitHubButton>
|
||||
</span>
|
||||
</div>
|
||||
<div>
|
||||
<Link to="/docs/intro">
|
||||
<Button type="primary">
|
||||
Get Started
|
||||
</Button>
|
||||
</Link>
|
||||
</div>
|
||||
</StyledTitleContainer>
|
||||
|
||||
<StyledFeatures>
|
||||
<StyledHeading>Overview</StyledHeading>
|
||||
<div className="info-text info-text-smaller">
|
||||
Superset is fast, lightweight, intuitive, and loaded with options
|
||||
that make it easy for users of all skill sets to explore and
|
||||
visualize their data, from simple line charts to highly detailed
|
||||
geospatial charts.
|
||||
</div>
|
||||
<ul className="featureList ant-row">
|
||||
<Row>
|
||||
<Col sm={24} md={12}>
|
||||
<Feature
|
||||
icon={<FireOutlined className="warning-color" />}
|
||||
title="Powerful yet easy to use"
|
||||
descr={`
|
||||
Quickly and easily integrate and explore your data, using
|
||||
either our simple no-code viz builder or state of the art SQL
|
||||
IDE.
|
||||
`}
|
||||
/>
|
||||
</Col>
|
||||
|
||||
<Col sm={24} md={12}>
|
||||
<Feature
|
||||
icon={<DatabaseOutlined className="info-color" />}
|
||||
title="Integrates with modern databases"
|
||||
descr={`
|
||||
Superset can connect to any SQL based datasource
|
||||
through SQLAlchemy, including modern cloud native databases
|
||||
and engines at petabyte scale.
|
||||
`}
|
||||
/>
|
||||
</Col>
|
||||
</Row>
|
||||
<Row>
|
||||
<Col sm={24} md={12}>
|
||||
<Feature
|
||||
icon={<DeploymentUnitOutlined className="success-color" />}
|
||||
title="Modern architecture"
|
||||
descr={`
|
||||
Superset is lightweight and highly scalable, leveraging the
|
||||
power of your existing data infrastructure without requiring
|
||||
yet another ingestion layer.
|
||||
`}
|
||||
/>
|
||||
</Col>
|
||||
<Col sm={24} md={12}>
|
||||
<Feature
|
||||
icon={<DotChartOutlined className="alert-color" />}
|
||||
title="Rich visualizations and dashboards"
|
||||
descr={`
|
||||
Superset ships with a wide array of beautiful visualizations.
|
||||
Our visualization plug-in architecture makes it easy to build
|
||||
custom visualizations that drop directly into Superset.
|
||||
`}
|
||||
/>
|
||||
</Col>
|
||||
</Row>
|
||||
</ul>
|
||||
</StyledFeatures>
|
||||
|
||||
<CarouselSection>
|
||||
<StyledHeading>Explore</StyledHeading>
|
||||
<div className="toggleContainer">
|
||||
<div className="toggleBtns">
|
||||
<div
|
||||
className={`toggle ${slideIndex === 0 ? 'active' : null}`}
|
||||
onClick={() => slider.current.goTo(0)}
|
||||
role="button"
|
||||
>
|
||||
<h2>Explore</h2>
|
||||
<span>
|
||||
Explore your data using the array of data visualizations.
|
||||
</span>
|
||||
</div>
|
||||
|
||||
<div
|
||||
className={`toggle ${slideIndex === 1 ? 'active' : null}`}
|
||||
onClick={() => slider.current.goTo(1)}
|
||||
role="button"
|
||||
>
|
||||
<h2>View</h2>
|
||||
<span>View your data through interactive dashboards</span>
|
||||
</div>
|
||||
<div
|
||||
className={`toggle ${slideIndex === 2 ? 'active' : null}`}
|
||||
onClick={() => slider.current.goTo(2)}
|
||||
role="button"
|
||||
>
|
||||
<h2>Investigate</h2>
|
||||
<span>Use SQL Lab to write queries to explore your data</span>
|
||||
</div>
|
||||
</div>
|
||||
<Carousel ref={slider} effect="scrollx" afterChange={onChange}>
|
||||
<div className="imageContainer">
|
||||
<img src="img/explorer5.jpg" alt="" />
|
||||
</div>
|
||||
<div className="imageContainer">
|
||||
<img src="img/dashboard3.png" alt="" />
|
||||
</div>
|
||||
<div className="imageContainer">
|
||||
<img src="img/sqllab5.jpg" alt="" />
|
||||
</div>
|
||||
</Carousel>
|
||||
</div>
|
||||
<StyledIntegrations>
|
||||
<StyledHeading>Supported Databases</StyledHeading>
|
||||
|
||||
<ul className="database-list">
|
||||
{Databases.map(
|
||||
({
|
||||
title, imgName: imageName, width, height,
|
||||
}) => (
|
||||
<li>
|
||||
<img src={`img/databases/${imageName}`} width={width} height={height || 50} title={title} />
|
||||
</li>
|
||||
),
|
||||
)}
|
||||
</ul>
|
||||
<span className="databaseSub">
|
||||
... and many other
|
||||
<a href="docs/connecting-to-databases/installing-database-drivers">
|
||||
{' '}
|
||||
compatible databases
|
||||
{' '}
|
||||
</a>
|
||||
</span>
|
||||
</StyledIntegrations>
|
||||
</CarouselSection>
|
||||
|
||||
</StyledMain>
|
||||
</Layout>
|
||||
);
|
||||
}
|
||||
|
|
@ -0,0 +1,26 @@
|
|||
<!--
|
||||
Licensed to the Apache Software Foundation (ASF) under one
|
||||
or more contributor license agreements. See the NOTICE file
|
||||
distributed with this work for additional information
|
||||
regarding copyright ownership. The ASF licenses this file
|
||||
to you under the Apache License, Version 2.0 (the
|
||||
"License"); you may not use this file except in compliance
|
||||
with the License. You may obtain a copy of the License at
|
||||
|
||||
http://www.apache.org/licenses/LICENSE-2.0
|
||||
|
||||
Unless required by applicable law or agreed to in writing,
|
||||
software distributed under the License is distributed on an
|
||||
"AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
|
||||
KIND, either express or implied. See the License for the
|
||||
specific language governing permissions and limitations
|
||||
under the License.
|
||||
-->
|
||||
|
||||
---
|
||||
title: Markdown page example
|
||||
---
|
||||
|
||||
# Markdown page example
|
||||
|
||||
You don't need React to write simple standalone pages.
|
||||
|
|
@ -0,0 +1,136 @@
|
|||
/**
|
||||
* Licensed to the Apache Software Foundation (ASF) under one
|
||||
* or more contributor license agreements. See the NOTICE file
|
||||
* distributed with this work for additional information
|
||||
* regarding copyright ownership. The ASF licenses this file
|
||||
* to you under the Apache License, Version 2.0 (the
|
||||
* "License"); you may not use this file except in compliance
|
||||
* with the License. You may obtain a copy of the License at
|
||||
*
|
||||
* http://www.apache.org/licenses/LICENSE-2.0
|
||||
*
|
||||
* Unless required by applicable law or agreed to in writing,
|
||||
* software distributed under the License is distributed on an
|
||||
* "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
|
||||
* KIND, either express or implied. See the License for the
|
||||
* specific language governing permissions and limitations
|
||||
* under the License.
|
||||
*/
|
||||
|
||||
export const Databases = [
|
||||
{
|
||||
title: 'Amazon Redshfit',
|
||||
href: 'https://aws.amazon.com/redshift/',
|
||||
imgName: 'aws-redshift.png',
|
||||
},
|
||||
{
|
||||
title: 'Apache Druid',
|
||||
href: 'http://druid.io/',
|
||||
imgName: 'druid.png',
|
||||
},
|
||||
{
|
||||
title: 'Apache Kylin',
|
||||
href: 'http://kylin.apache.org/',
|
||||
imgName: 'apache-kylin.png',
|
||||
},
|
||||
{
|
||||
title: 'BigQuery',
|
||||
href: 'https://cloud.google.com/bigquery/',
|
||||
imgName: 'googleBQ.png',
|
||||
},
|
||||
{
|
||||
title: 'ClickHouse',
|
||||
href: 'https://clickhouse.tech/',
|
||||
imgName: 'clickhouse.png',
|
||||
},
|
||||
{
|
||||
title: 'Dremio',
|
||||
href: 'https://dremio.com/',
|
||||
imgName: 'dremio.png',
|
||||
},
|
||||
{
|
||||
title: 'Exasol',
|
||||
href: 'https://www.exasol.com/en/',
|
||||
imgName: 'exasol.png',
|
||||
},
|
||||
{
|
||||
title: 'FireBirdSql',
|
||||
href: 'https://firebirdsql.org/',
|
||||
imgName: 'firebird.png',
|
||||
},
|
||||
{
|
||||
title: 'Green Plum',
|
||||
href: 'https://greenplum.org/',
|
||||
imgName: 'greenplum.png',
|
||||
},
|
||||
{
|
||||
title: 'IBM Db2',
|
||||
href: 'https://www.ibm.com/analytics/db2',
|
||||
imgName: 'ibmdb2.png',
|
||||
},
|
||||
{
|
||||
title: 'MySQL',
|
||||
href: 'https://www.mysql.com/',
|
||||
imgName: 'mysql.png',
|
||||
},
|
||||
{
|
||||
title: 'Microsoft SqlServer',
|
||||
href: 'https://www.microsoft.com/en-us/sql-server',
|
||||
imgName: 'msql.png',
|
||||
},
|
||||
{
|
||||
title: 'MonetDB',
|
||||
href: 'https://www.monetdb.org/',
|
||||
imgName: 'monet.png',
|
||||
},
|
||||
{
|
||||
title: 'Oracle',
|
||||
href: 'https://www.oracle.com/database/',
|
||||
imgName: 'oraclelogo.png',
|
||||
},
|
||||
{
|
||||
title: 'PostgresSQL',
|
||||
href: 'https://www.postgresql.org/',
|
||||
imgName: 'postsql.png',
|
||||
},
|
||||
{
|
||||
title: 'Presto',
|
||||
href: 'https://prestodb.io/',
|
||||
imgName: 'presto-og.png',
|
||||
},
|
||||
{
|
||||
title: 'Snowflake',
|
||||
href: 'https://www.snowflake.com/',
|
||||
imgName: 'snowflake.png',
|
||||
},
|
||||
{
|
||||
title: 'SQLite',
|
||||
href: 'https://www.sqlite.org/index.html',
|
||||
imgName: 'sqllite.png',
|
||||
},
|
||||
{
|
||||
title: 'Trino',
|
||||
href: 'https://trino.io/',
|
||||
imgName: 'trino2.jpg',
|
||||
},
|
||||
{
|
||||
title: 'Rockset',
|
||||
href: 'https://rockset.com/',
|
||||
imgName: 'rockset.png',
|
||||
},
|
||||
{
|
||||
title: 'Vertica',
|
||||
href: 'https://www.vertica.com/',
|
||||
imgName: 'vertica.png',
|
||||
},
|
||||
{
|
||||
title: 'Hologres',
|
||||
href: 'https://www.alibabacloud.com/product/hologres',
|
||||
imgName: 'hologres.png',
|
||||
},
|
||||
{
|
||||
title: 'IBM Netezza Performance Server',
|
||||
href: 'https://www.ibm.com/products/netezza',
|
||||
imgName: 'netezza.png',
|
||||
},
|
||||
];
|
||||
|
|
@ -0,0 +1,22 @@
|
|||
/**
|
||||
* Licensed to the Apache Software Foundation (ASF) under one
|
||||
* or more contributor license agreements. See the NOTICE file
|
||||
* distributed with this work for additional information
|
||||
* regarding copyright ownership. The ASF licenses this file
|
||||
* to you under the Apache License, Version 2.0 (the
|
||||
* "License"); you may not use this file except in compliance
|
||||
* with the License. You may obtain a copy of the License at
|
||||
*
|
||||
* http://www.apache.org/licenses/LICENSE-2.0
|
||||
*
|
||||
* Unless required by applicable law or agreed to in writing,
|
||||
* software distributed under the License is distributed on an
|
||||
* "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY
|
||||
* KIND, either express or implied. See the License for the
|
||||
* specific language governing permissions and limitations
|
||||
* under the License.
|
||||
*/
|
||||
|
||||
const breakpoints = [576, 768, 992, 1200];
|
||||
|
||||
export const mq = breakpoints.map((bp) => `@media (max-width: ${bp}px)`);
|
||||
{kind=link}
|
After Width: | Height: | Size: 72 KiB |
{kind=link}
|
After Width: | Height: | Size: 80 KiB |
{kind=link}
|
After Width: | Height: | Size: 255 KiB |
{kind=link}
|
After Width: | Height: | Size: 85 KiB |
{kind=link}
|
After Width: | Height: | Size: 22 KiB |
{kind=link}
|
After Width: | Height: | Size: 28 KiB |
{kind=link}
|
After Width: | Height: | Size: 26 KiB |